xgboost
Xgboost
概念内容介绍来自七月在线头条号:
xgboost一直在竞赛江湖里被传为神器,比如时不时某个kaggle/天池比赛中,某人用xgboost于千军万马中斩获冠军。
RF和GBDT是工业界大爱的模型,Xgboost 是大杀器包裹,Kaggle各种Top排行榜曾一度呈现Xgboost一统江湖的局面,另外某次滴滴比赛第一名的改进也少不了Xgboost的功劳”。
1 决策树
举个例子,集训营某一期有100多名学员,假定给你一个任务,要你统计男生女生各多少人,当一个一个学员依次上台站到你面前时,你会怎么区分谁是男谁是女呢?
很快,你考虑到男生的头发一般很短,女生的头发一般比较长,所以你通过头发的长短将这个班的所有学员分为两拨,长发的为“女”,短发为“男”。
相当于你依靠一个指标“头发长短”将整个班的人进行了划分,于是形成了一个简单的决策树,而划分的依据是头发长短。
这时,有的人可能有不同意见了:为什么要用“头发长短”划分呀,我可不可以用“穿的鞋子是否是高跟鞋”,“有没有喉结”等等这些来划分呢,答案当然是可以的。
但究竟根据哪个指标划分更好呢?很直接的判断是哪个分类效果更好则优先用哪个。所以,这时就需要一个评价标准来量化分类效果了。
怎么判断“头发长短”或者“是否有喉结”是最好的划分方式,效果怎么量化呢?直观上来说,如果根据某个标准分类人群后,纯度越高效果越好,比如说你分为两群,“女”那一群都是女的,“男”那一群全是男的,那这个效果是最好的。但有时实际的分类情况不是那么理想,所以只能说越接近这种情况,我们则认为效果越好。
量化分类效果的方式有很多,比如信息增益(ID3)、信息增益率(C4.5)、基尼系数(CART)等等。
信息增益的度量标准:熵
ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
什么是信息增益呢?为了精确地定义信息增益,我们先定义信息论中广泛使用的一个度量标准,称为熵(entropy),它刻画了任意样例集的纯度(purity)。给定包含关于某个目标概念的正反样例的样例集S,那么S相对这个布尔型分类的熵为:
![]()
上述公式中,p+代表正样例,比如在本文开头第二个例子中p+则意味着去打羽毛球,而p-则代表反样例,不去打球(在有关熵的所有计算中我们定义0log0为0)。
举例来说,假设S是一个关于布尔概念的有14个样例的集合,它包括9个正例和5个反例(我们采用记号[9+,5-]来概括这样的数据样例),那么S相对于这个布尔样例的熵为:
Entropy([9+,5-])=-(9/14)log2(9/14)-(5/14)log2(5/14)=0.940。
So,根据上述这个公式,我们可以得到:S的所有成员属于同一类,
Entropy(S)=0; S的正反样例数量相等,Entropy(S)=1;S的正反样例数量不等,熵介于0,1之间,如下图所示:
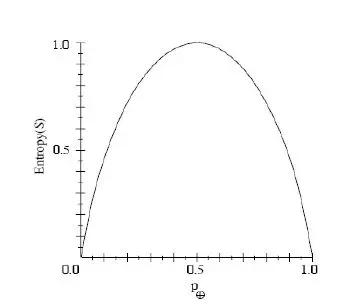
看到没,通过Entropy的值,你就能评估当前分类树的分类效果好坏了。
更多细节如剪枝、过拟合、优缺点、可以参考此文《决策树学习》。
所以,现在决策树的灵魂已经有了,即依靠某种指标进行树的分裂达到分类/回归的目的,总是希望纯度越高越好。
2
回归树与集成学习
如果用一句话定义xgboost,很简单:Xgboost就是由很多分类和回归树集成。分类树好理解,但,回归树又是什么呢?
数据挖掘或机器学习中使用的决策树有两种主要类型:
1、分类树分析是指预测结果是数据所属的类(比如某个电影去看还是不看)
2、回归树分析是指预测结果可以被认为是实数(例如房屋的价格,或患者在医院中的逗留时间)
而术语分类和回归树(CART,Classification And Regression Tree)分析是用于指代上述两种树的总称,由Breiman等人首先提出。
2.1 回归树
事实上,分类与回归是两个很接近的问题,分类的目标是根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类,它的结果是离散值。而回归的结果是连续的值。当然,本质是一样的,都是特征(feature)到结果/标签(label)之间的映射。
理清了什么是分类和回归之后,理解分类树和回归树就不难了。
分类树的样本输出(即响应值)是类的形式,比如判断这个救命药是真的还是假的,周末去看电影《风语咒》还是不去。而回归树的样本输出是数值的形式,比如给某人发放房屋贷款的数额就是具体的数值,可以是0到300万元之间的任意值。
所以,对于回归树,你没法再用分类树那套信息增益、信息增益率、基尼系数来判定树的节点分裂了,你需要采取新的方式评估效果,包括预测误差(常用的有均方误差、对数误差等)。而且节点不再是类别,是数值(预测值),那么怎么确定呢?有的是节点内样本均值,有的是最优化算出来的比如Xgboost。
2.2 boosting集成学习
所谓集成学习,是指构建多个分类器(弱分类器)对数据集进行预测,然后用某种策略将多个分类器预测的结果集成起来,作为最终预测结果。通俗比喻就是“三个臭皮匠赛过诸葛亮”,或一个公司董事会上的各董事投票决策,它要求每个弱分类器具备一定的“准确性”,分类器之间具备“差异性”。
集成学习根据各个弱分类器之间有无依赖关系,分为Boosting和Bagging两大流派:
Boosting流派,各分类器之间有依赖关系,必须串行,比如Adaboost、GBDT(Gradient Boosting Decision Tree)、Xgboost
Bagging流派,各分类器之间没有依赖关系,可各自并行,比如随机森林(Random Forest)
而著名的Adaboost作为boosting流派中最具代表性的一种方法,本博客曾详细介绍它。
AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,由Yoav Freund和Robert Schapire在1995年提出。它的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
具体说来,整个Adaboost 迭代算法就3步:
1、初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
2、训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
3、将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
而另一种boosting方法GBDT(Gradient Boost Decision Tree),则与AdaBoost不同,GBDT每一次的计算是都为了减少上一次的残差,进而在残差减少(负梯度)的方向上建立一个新的模型。
boosting集成学习由多个相关联的决策树联合决策,什么叫相关联?举个例子
1、有一个样本[数据->标签]是:[(2,4,5)-> 4]
2、第一棵决策树用这个样本训练的预测为3.3
3、那么第二棵决策树训练时的输入,这个样本就变成了:[(2,4,5)-> 0.7]
4、也就是说,下一棵决策树输入样本会与前面决策树的训练和预测相关
很快你会意识到,Xgboost为何也是一个boosting的集成学习了。
而一个回归树形成的关键点在于:
分裂点依据什么来划分(如前面说的均方误差最小,loss);
分类后的节点预测值是多少(如前面说,有一种是将叶子节点下各样本实际值得均值作为叶子节点预测误差,或者计算所得)
至于另一类集成学习方法,比如Random Forest(随机森林)算法,各个决策树是独立的、每个决策树在样本堆里随机选一批样本,随机选一批特征进行独立训练,各个决策树之间没有啥关系。本文暂不展开介绍。
3 GBDT
说到Xgboost,不得不先从GBDT(Gradient Boosting Decision Tree)说起。而且前面说过,两者都是boosting方法(如图所示:Y = Y1 + Y2 + Y3)
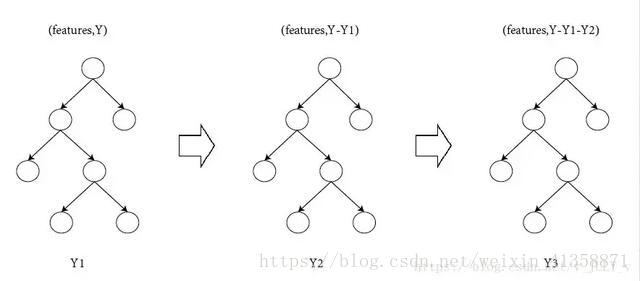
咱们来看个年龄预测的例子。
简单起见,假定训练集只有4个人:A,B,C,D,他们的年龄分别是14,16,24,26。其中A、B分别是高一和高三学生;C,D分别是应届毕业生和工作两年的员工。
如果是用一棵传统的回归决策树来训练,会得到如下图所示结果:

现在我们使用GBDT来做这件事,由于数据太少,我们限定叶子节点做多有两个,即每棵树都只有一个分枝,并且限定只学两棵树。
我们会得到如下图所示结果:

在第一棵树分枝和图1一样,由于A,B年龄较为相近,C,D年龄较为相近,他们被分为左右两拨,每拨用平均年龄作为预测值。
• 此时计算残差(残差的意思就是:A的实际值 - A的预测值 = A的残差),所以A的残差就是实际值14 - 预测值15 = 残差值-1。
• 注意,A的预测值是指前面所有树累加的和,这里前面只有一棵树所以直接是15,如果还有树则需要都累加起来作为A的预测值。
残差在数理统计中是指实际观察值与估计值(拟合值)之间的差。“残差”蕴含了有关模型基本假设的重要信息。如果回归模型正确的话, 我们可以将残差看作误差的观测值。
进而得到A,B,C,D的残差分别为-1,1,-1,1。
然后拿它们的残差代替A B C D的原值-1、1、-1、1,到第二棵树去学习,第二棵树只有两个值1和-1,直接分成两个节点,即A和C分在左边,B和D分在右边,经过计算(比如A,实际值-1 - 预测值-1 = 残差0,比如C,实际值-1 - 预测值-1 = 0),此时所有人的残差都是0。
残差值都为0,相当于第二棵树的预测值和它们的实际值相等,则只需把第二棵树的结论累加到第一棵树上就能得到真实年龄了,即每个人都得到了真实的预测值。
换句话说,现在A,B,C,D的预测值都和真实年龄一致了。Perfect!
A: 14岁高一学生,购物较少,经常问学长问题,预测年龄A = 15 – 1 = 14
B: 16岁高三学生,购物较少,经常被学弟问问题,预测年龄B = 15 + 1 = 16
C: 24岁应届毕业生,购物较多,经常问师兄问题,预测年龄C = 25 – 1 = 24
D: 26岁工作两年员工,购物较多,经常被师弟问问题,预测年龄D = 25 + 1 = 26
4
Xgboost
4.1 xgboost树的定义
本节的示意图基本引用自xgboost原作者陈天奇的讲座PPT中。
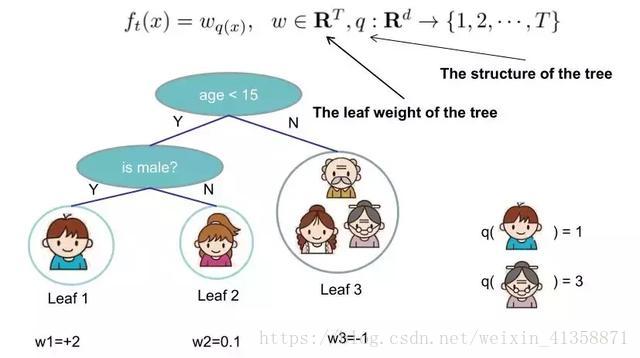
举个例子,我们要预测一家人谁是谁,则可以先通过年龄区分开小孩和大人,然后再通过性别区分开是男是女,如下图所示。
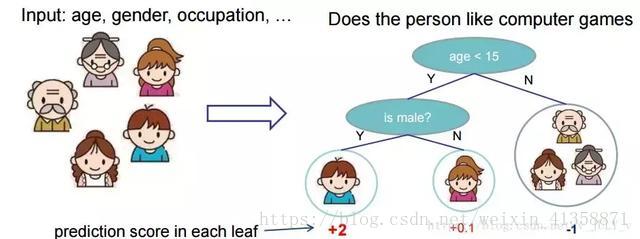
就这样,训练出了2棵树tree1和tree2,类似之前gbdt的原理,两棵树的结论累加起来便是最终的结论,所以小孩的预测分数就是两棵树中小孩所落到的结点的分数相加:2 + 0.9 = 2.9。爷爷的预测分数同理:-1 + (-0.9)= -1.9。具体如下图所示
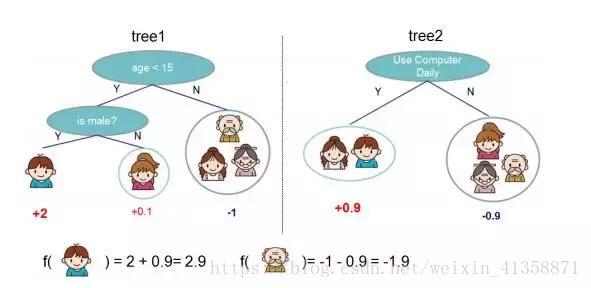
恩,你可能要拍案而起了,惊呼,这不是跟上文介绍的gbdt乃异曲同工么?
事实上,如果不考虑工程实现、解决问题上的一些差异,xgboost与gbdt比较大的不同就是目标函数的定义。xgboost的目标函数如下图所示:

其中
红色箭头所指向的L 即为损失函数(比如平方损失函数: (yi,y^i) = (yi−y^i)2,或logistic损失函数:
![]()
红色方框所框起来的是正则项(包括L1正则、L2正则)
红色圆圈所圈起来的为常数项
对于f(x),xgboost利用泰勒展开三项,做一个近似
我们可以很清晰地看到,最终的目标函数只依赖于每个数据点的在误差函数上的一阶导数和二阶导数。
4.2 xgboost目标函数
首先,再次明确下我们的目标,是希望建立K个回归树,使得树群的预测值尽量接近真实值(准确率)而且有尽量大的泛化能力(更为本质的东西)。
从数学角度看这是一个泛函最优化,多目标,把目标函数简化下:
![]()
很明显,这个目标函数分为两部分:误差函数和正则化项。且误差/损失函数揭示训练误差,正则化定义复杂度。
对于上式而言,yi’是整个累加模型的输出,正则化项∑kΩ()是则表示树的复杂度的函数,值越小复杂度越低,泛化能力越强,其表达式为
![]()
T表示叶子节点的个数,w表示节点的数值。直观上看,目标要求预测误差尽量小,且叶子节点T尽量少,节点数值w尽量不极端。
插一句,一般的目标函数都包含下面两项

其中,误差函数鼓励我们的模型尽量去拟合训练数据,使得最后的模型会有比较少的 bias。而正则化项则鼓励更加简单的模型。因为当模型简单之后,有限数据拟合出来结果的随机性比较小,不容易过拟合,使得最后模型的预测更加稳定。
4.2.1 模型学习与训练误差
具体来说,目标函数第一部分中i 表示第i样本,l (y^i−yi) 表示第 i个样本的预测误差,我们的目标当然是误差越小越好。

在当前步yi,以及y(t-1)都是已知值,模型学习的是ft。
那接下来,我们如何选择每一轮加入什么f?答案是非常直接的,选取一f 来使得我们的目标函数尽量最大地降低。

这个公式可能有些过于抽象,我们可以考虑l 是平方误差的情况,这个时候我们的目标可以被写成下面这样的二次函数
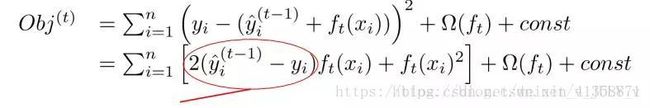
更加一般的,损失函数不是二次函数咋办?泰勒展开,不是二次的想办法近似为二次。

且把常数项移除之后,我们会发现如下一个比较统一的目标函数。
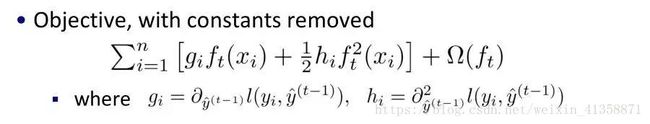
这时,目标函数只依赖于每个数据点的在误差函数上的一阶导数和二阶导数
到目前为止我们讨论了目标函数中的第一个部分:训练误差。接下来我们讨论目标函数的第二个部分:如何定义树的复杂度。
4.2.2 树的复杂度
首先,梳理下几个规则
用叶子节点集合以及叶子节点得分表示
每个样本都落在一个叶子节点上
q(x)表示样本x在某个叶子节点上,wq(x)是该节点的打分,即该样本的模型预测值
所以当我们把树成结构部分q和叶子权重部分w后,结构函数q把输入映射到叶子的索引号上面去,而w给定了每个索引号对应的叶子分数是什么。
这个树的复杂度复杂度包含了一棵树里面节点的个数,以及每个树叶子节点上面输出分数的L2模平方。用图说明下,可能更形象点:
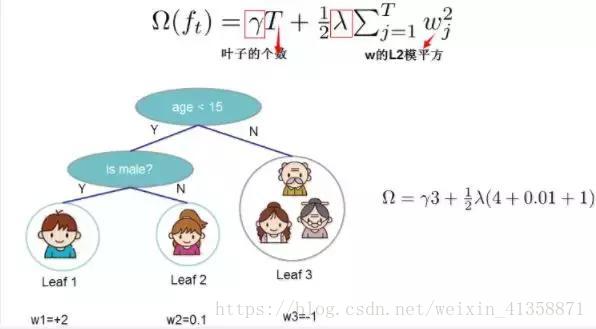
从图中可以看出,xgboost算法中对树的复杂度项包含了两个部分,一个是叶子节点个数T,一个是叶子节点得分L2正则化项w,针对每个叶结点的得分增加L2平滑,目的也是为了避免过拟合。
还记得4.2节开头对目标函数的说明吧(损失函数揭示训练误差 + 正则化定义复杂度)?
把目标函数简化下:
![]()
这是目标函数优化的是整体的模型。很明显,这个目标函数分为两部分:误差函数和正则化项。且误差/损失函数揭示训练误差,正则化定义复杂度。
对于上式而言,yi’是整个累加模型的输出,正则化项∑kΩ(fk)是则表示树的复杂度的函数,值越小复杂度越低,泛化能力越强,其表达式为
![]()
T表示叶子节点的个数,w表示节点的数值。直观上看,目标要求预测误差尽量小,且叶子节点T尽量少,节点数值w尽量不极端。
在这种新的定义下,我们可以把目标函数进行如下改写

其中ij被定义为每个叶节点 j 上面样本集合
![]()
g是一阶导数,h是二阶导数。这一步是由于xgboost目标函数第二部分加了两个正则项,一个是叶子节点个数(T),一个是叶节点的分数(w)。
从而,加了正则项的目标函数里就出现了两种累加
▶ 一种是i - > n(样本数)
▶ 一种是j -> T(叶子节点数)
这一个目标包含了T个相互独立的单变量二次函数。我们可以定义
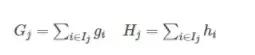
最终公式可以化简为
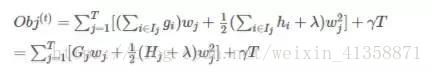
通过wj对求导等于0,可以得到
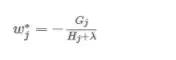
然后把wj最优解代入得到:
![]()
4.3 打分函数计算
Obj代表了当我们指定一个树的结构的时候,我们在目标上面最多减少多少。我们可以把它叫做结构分数(structure score)
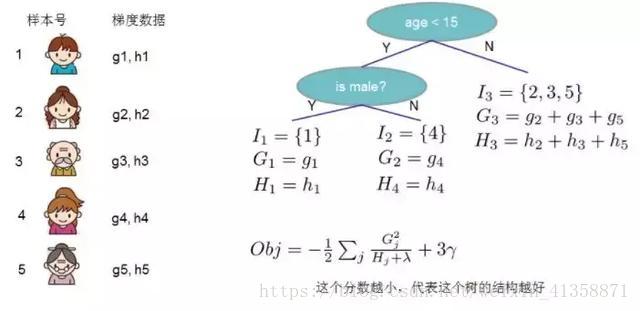
4.3.1 分裂节点
xgboost的原始论文中给出了两种分裂节点的方法
(1)枚举所有不同树结构的贪心法
不断地枚举不同树的结构,利用这个打分函数来寻找出一个最优结构的树,加入到我们的模型中,再重复这样的操作。不过枚举所有树结构这个操作不太可行,所以常用的方法是贪心法,每一次尝试去对已有的叶子加入一个分割。对于一个具体的分割方案,我们可以获得的增益可以由如下公式计算。

对于每次扩展,我们还是要枚举所有可能的分割方案,如何高效地枚举所有的分割呢?我假设我们要枚举所有x < a 这样的条件,对于某个特定的分割a我们要计算a左边和右边的导数和。

我们可以发现对于所有的a,我们只要做一遍从左到右的扫描就可以枚举出所有分割的梯度和GL和GR。然后用上面的公式计算每个分割方案的分数就可以了。
观察这个目标函数,大家会发现第二个值得注意的事情就是引入分割不一定会使得情况变好,因为我们有一个引入新叶子的惩罚项。优化这个目标对应了树的剪枝, 当引入的分割带来的增益小于一个阀值的时候,我们可以剪掉这个分割。
大家可以发现,当我们正式地推导目标的时候,像计算分数和剪枝这样的策略都会自然地出现,而不再是一种因为heuristic(启发式)而进行的操作了。
下面是论文中的算法

(2)近似算法
主要针对数据太大,不能直接进行计算

4.4 小结:Boosted Tree Algorithm
总结一下,如图所示

咱们来再次回顾整个过程。
如果某个样本label数值为4,那么第一个回归树预测3,第二个预测为1; 另外一组回归树,一个预测2,一个预测2,那么倾向后一种,为什么呢?前一种情况,第一棵树学的太多,太接近4,也就意味着有较大的过拟合的风险。
OK,听起来很美好,可是怎么实现呢,上面这个目标函数跟实际的参数怎么联系起来,记得我们说过,回归树的参数:
1、选取哪个feature分裂节点呢
2、节点的预测值(总不能靠取平均值这么粗暴不讲道理的方式吧,好歹高级一点)
最终的策略就是:贪心 + 最优化(二次最优化,恩你没看错) 。
通俗解释贪心策略:就是决策时刻按照当前目标最优化决定,说白了就是眼前利益最大化决定,“目光短浅”策略。
这里是怎么用贪心策略的呢,刚开始你有一群样本,放在第一个节点,这时候T=1,w多少呢,不知道,是求出来的,这时候所有样本的预测值都是w,带入样本的label数值,此时loss function变为
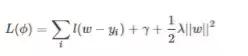
如果这里的l(w−yi)误差表示用的是平方误差,那么上述函数就是一个关于w的二次函数求最小值,取最小值的点就是这个节点的预测值,最小的函数值为最小损失函数。
本质上来讲,这就是一个二次函数最优化问题!但要是损失函数不是二次函数咋办?泰勒展开,不是二次的想办法近似为二次。
接着来,接下来要选个feature分裂成两个节点,变成一棵弱小的树苗,那么需要:
1、确定分裂用的feature,how?最简单的是粗暴的枚举,选择loss function效果最好的那个;
2、如何确立节点的ww以及最小的loss function,大声告诉我怎么做?对,二次函数的求最值(计算二次的最值一般都有固定套路,即导数等于0的点) 。所以,选择一个feature分裂,计算loss function最小值,然后再选一个feature分裂,又得到一个loss function最小值,你枚举完,找一个效果最好的,把树给分裂,就得到了小树苗。
在分裂的时候,你可以注意到,每次节点分裂,loss function被影响的只有这个节点的样本,因而每次分裂,计算分裂的增益(loss function的降低量)只需要关注打算分裂的那个节点的样本。
原论文这里会推导出一个优雅的公式,如下图所示:

接下来,继续分裂,按照上述的方式,形成一棵树,再形成一棵树,每次在上一次的预测基础上取最优进一步分裂/建树,是不是贪心策略?
凡是这种循环迭代的方式必定有停止条件,什么时候停止呢?
1、当引入的分裂带来的增益小于一个阀值的时候,我们可以剪掉这个分裂,所以并不是每一次分裂loss function整体都会增加的,有点预剪枝的意思,阈值参数为(即正则项里叶子节点数T的系数);
2、当树达到最大深度时则停止建立决策树,设置一个超参数max_depth,避免树太深导致学习局部样本,从而过拟合;
3、当样本权重和小于设定阈值时则停止建树,这个解释一下,涉及到一个超参数-最小的样本权重和min_child_weight,和GBM的 min_child_leaf 参数类似,但不完全一样,大意就是一个叶子节点样本太少了,也终止同样是过拟合;
4、貌似看到过有树的最大数量的…
xgboost调参
1数据的加载形式
#Data=pd.dataframe().values
data = np.random.rand(5,10) # 5 entities, each contains 10 features
label = np.random.randint(2, size=5) # binary target
dtrain = xgb.DMatrix( data, label=label)
#X_test = xgb.DMatrix( test)
2调参顺序
Step 1- Find the number of estimators for a high learning rate,一般设置为0.1
Step2-Find the number of max_depth and min_child_weight, interval decrease
Step3-Find the number of gamma
Step4-Find the number of subsample, colsample_bytree
Step5-Find the number of reg_alpha
Step6-Find the number of reg_lambda
Step7-Find the number of learning_rate,decrease the learning rate
都是按照xgboost调参的顺序来安排的
- 合适的n_estimators
predictors = [x for x in train.columns if x not in [target, IDcol]]
xgb1 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
seed=27)
modelfit(xgb1, train, test, predictors)def modelfit(alg, dtrain, dtest, predictors,useTrainCV=True, cv_folds=5, early_stopping_rounds=50):
if useTrainCV:
xgb_param = alg.get_xgb_params()
xgtrain = xgb.DMatrix(dtrain[predictors].values, label=dtrain[target].values)
xgtest = xgb.DMatrix(dtest[predictors].values)
cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds,
metrics='auc', early_stopping_rounds=early_stopping_rounds, show_progress=False)
alg.set_params(n_estimators=cvresult.shape[0])
#Fit the algorithm on the data
alg.fit(dtrain[predictors], dtrain['Disbursed'],eval_metric='auc')
#Predict training set:
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
#Print model report:
print "\nModel Report"
print "Accuracy : %.4g" % metrics.accuracy_score(dtrain['Disbursed'].values, dtrain_predictions)
print "AUC Score (Train): %f" % metrics.roc_auc_score(dtrain['Disbursed'], dtrain_predprob)
# Predict on testing data:
dtest['predprob'] = alg.predict_proba(dtest[predictors])[:,1]
results = test_results.merge(dtest[['ID','predprob']], on='ID')
print 'AUC Score (Test): %f' % metrics.roc_auc_score(results['Disbursed'], results['predprob'])
feat_imp = pd.Series(alg.booster().get_fscore()).sort_values(ascending=False)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')
#其他内容见详见:xgboost网格搜索实例
https://github.com/aarshayj/Analytics_Vidhya/blob/master/Articles/Parameter_Tuning_XGBoost_with_Example/XGBoost%20models.ipynb
xgboost 中文文档:http://xgboost.apachecn.org/cn/latest/parameter.html
XGBoost:参数解释:https://blog.csdn.net/zc02051126/article/details/46711047
XGboost数据比赛实战之调参篇(完整流程):
https://segmentfault.com/a/1190000014040317
python-贝叶斯优化调参之Hyperopt::
https://blog.csdn.net/gdh756462786/article/details/79268685
XGBoost参数调优:http://www.cnblogs.com/zhangbojiangfeng/p/6428988.html
XGBoost:在Python中使用XGBoost:
https://blog.csdn.net/zc02051126/article/details/46771793#数据接口