经典监督学习算法——决策树
什么是决策树
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
简单的说就是你做出决定的一系列依据,下面的一个例子能帮助我们很好地理解决策树的概念
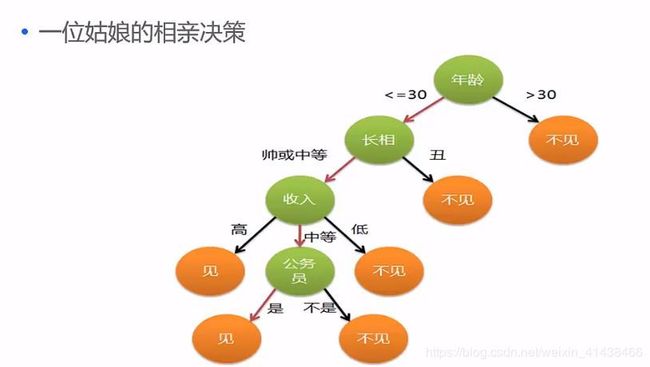
决策树是一种树形结构,其生成过程是每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。通俗的说就是先选取一个对象的一个特征,在这个特征的所有取值上做出决策。叶节点就是我们做出的决策
决策树通常有三个步骤:特征选择、决策树的生成、决策树的修剪
决策树所解决的问题
- 分类问题(使用较多)
- 回归问题
决策树的种类
预备知识——信息熵
(看之前可以了解一下信息熵的创始人:克劳德·艾尔伍德·香农(Claude Elwood Shannon ,1916年4月30日—2001年2月24日))
先给出信息熵的公式:
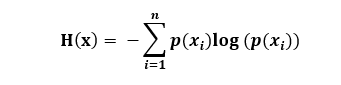
其中:?(??)代表随机事件??的概率。
下面逐步介绍信息熵公式来源!
首先了解一下信息量:信息量是对信息的度量,就跟时间的度量是秒一样,当我们考虑一个离散的随机变量 x 的时候,当我们观察到的这个变量的一个具体值的时候,我们接收到了多少信息呢?
多少信息用信息量来衡量,我们接受到的信息量跟具体发生的事件有关。
信息的大小跟随机事件的概率有关。越小概率的事情发生了产生的信息量越大,如湖南产生地震了;越大概率的事情发生了产生的信息量越小,如太阳从东边升起来了(肯定发生嘛, 没什么信息量)。这很好理解!
因此一个具体事件的信息量应该是随着其发生概率而递减的,且不能为负。但是这个表示信 息量函数的形式怎么找呢?随着概率增大而减少的函数形式太多了!不要着急,我们还有下 面这条性质。
如果我们有俩个不相关的事件 x 和 y,那么我们观察到的俩个事件同时发生时获得的信息应 该等于观察到的事件各自发生时获得的信息之和,即: h(x,y) = h(x) + h(y)
由于 x,y 是俩个不相关的事件,那么满足 p(x,y) = p(x)*p(y).
根据上面推导,我们很容易看出 h(x)一定与 p(x)的对数有关(因为只有对数形式的真数相乘 之后,能够对应对数的相加形式,可以试试)。因此我们有信息量公式如下:
?(?) = −?????(?)
(1)为什么有一个负号?其中,负号是为了确保信息一定是正数或者是 0,总不能为负数吧!
(2)为什么底数为 2 这是因为,我们只需要信息量满足低概率事件 x 对应于高的信息量。那么对数的选择是任意的。我们只是遵循信息论的普遍传统,使用 2 作为对数的底!
信息熵 下面正式引出信息熵:信息量度量的是一个具体事件发生了所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。即
?(?) = −???(?(?)?????(?))
转换一下也就是:
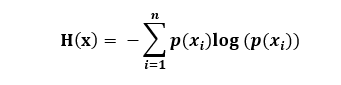
最终我们的公式来源推导完成了。
信息熵还可以作为一个系统复杂程度的度量,如果系统越复杂,出现不同情况的种类越多, 那么他的信息熵是比较大的。如果一个系统越简单,出现情况种类很少(极端情况为 1 种情况,那么对应概率为 1,那么对应的信息熵为 0),此时的信息熵较小。
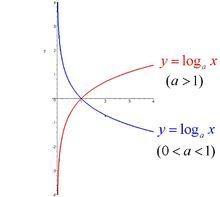
最后附上对数函数一些性质,你画出 ?(?) = −????? 的图像会更加明了。
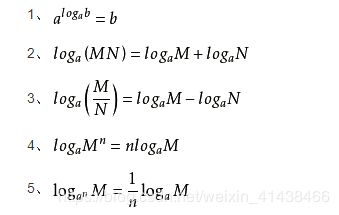
参考
1、 ID3决策树
首先了解一下ID3算法,ID3算法是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
实例
问题描述:
下面是一个小型的数据集,5条记录,2个特征(属性),有标签。

根据这个数据集,我们可以建立如下决策树(用matplotlib的注释功能画的)。
观察决策树,决策节点为特征,其分支为决策节点的各个不同取值,叶节点为预测值。

那么如何建立这样的决策树呢?
第一步:建立决策树。
1.1 利用信息增益寻找当前最佳分类特征
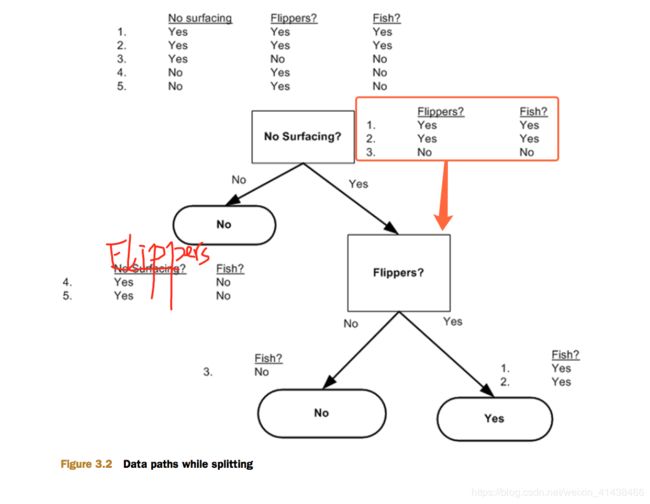
我们用信息增益来选择某个节点上用哪个特征来进行分类。
信息增益=原信息熵-新信息熵
注意:新香农熵为按照某特征划分之后,∑ 每个分支数据集的香农熵*该分支数据集中记录条数占划分前记录条数的百分比。
可以这样想:信息熵相当于数据类别(标签)的混乱程度,信息增益可以衡量划分数据集前后数据(标签)向有序性发展的程度。因此,回到怎样利用信息增益寻找当前最佳分类特征的话题,假如你是一个判断节点,你拿来一个数据集,数据集里面有若干个特征,你需要从中选取一个特征,使得信息增益最大(注意:将数据集中在该特征上取值相同的记录划分到同一个分支,得到若干个分支数据集,每个分支数据集都有自己的信息熵,各个分支数据集的信息熵的期望才是新信息熵)。要找到这个特征只需要将数据集中的每个特征遍历一次,求信息增益,取获得最大信息增益的那个特征。
代码如下(其中,calcShannonEnt(dataSet)函数用来计算数据集dataSet的信息熵,splitDataSet(dataSet, axis, value)函数将数据集dataSet的第axis列中特征值为value的记录挑出来,组成分支数据集返回给函数。这两个函数后面会给出函数定义。):
# 3-3 选择最好的'数据集划分方式'(特征)
# 一个一个地试每个特征,如果某个按照某个特征分类得到的信息增益(原香农熵-新香农熵)最大,
# 则选这个特征作为最佳数据集划分方式
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
calcShannonEnt(dataSet)函数代码:
def calcShannonEnt(dataSet):
numEntries = len(dataSet) # 总记录数
labelCounts = {} # dataSet中所有出现过的标签值为键,相应标签值出现过的次数作为值
for featVec in dataSet:
currentLabel = featVec[-1]
labelCounts[currentLabel] = labelCounts.get(currentLabel, 0) + 1
shannonEnt = 0.0
for key in labelCounts:
prob = -float(labelCounts[key])/numEntries
shannonEnt += prob * log(prob, 2)
return shannonEnt
splitDataSet(dataSet, axis, value)函数代码:
# 3-2 按照给定特征划分数据集(在某个特征axis上,值等于value的所有记录
# 组成新的数据集retDataSet,新数据集不需要axis这个特征,注意value是特征值,axis指的是特征(所在的列下标))
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
1.2 建树
建树是一个递归的过程。
递归结束的标志(判断某节点是叶节点的标志):
情况1. 分到该节点的数据集中,所有记录的标签列取值都一样。
或
情况2. 分到该节点的数据集中,只剩下标签列。
a. 经判断,若是叶节点,则:
对应情况1,返回数据集中第一条记录的标签值(反正所有标签值都一样)。
对应情况2,返回数据集中所有标签值中,出现次数最多的那个标签值(代码中,定义一个函数majorityCnt(classList)来实现)
b. 经判断,若不是叶节点,则:
step1. 建立一个字典,字典的键为该数据集上选出的最佳特征(划分依据)。
step2. 将具有相同特征值的记录组成新的数据集(利用splitDataSet(dataSet, axis, value)函数实现,注意期间抛弃了当前用于划分数据的特征列),对新的数据集们进行递归建树。
建树代码:
# 3-4 创建树的函数代码
# 如果非叶子结点,则以当前数据集建树,并返回该树。该树的根节点是一个字典,键为划分当前数据集的最佳特征,值为按照键值划分后各个数据集构造的树
# 叶子节点有两种:1.只剩没有特征时,叶子节点的返回值为所有记录中,出现次数最多的那个标签值 2.该叶子节点中,所有记录的标签相同。
def createTree(dataSet, labels): #label向量的维度为特征数,不是记录数,是不同列下标对应的特征
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals: #递归建子树,若值为字典,则非叶节点,若为字符串,则为叶节点
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), labels)
return myTree
画决策树的代码
# _*_coding:utf-8_*_
# 3-7 plotTree函数
import matplotlib.pyplot as plt
# 定义节点和箭头格式的常量
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def plotMidTest(cntrPt, parentPt,txtString):
xMid = (parentPt[0] + cntrPt[0])/2.0
yMid = (parentPt[1] + cntrPt[1])/2.0
createPlot.ax1.text(xMid, yMid, txtString)
# 绘制自身
# 若当前子节点不是叶子节点,递归
# 若当子节点为叶子节点,绘制该节点
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
# depth = getTreeDepth(myTree)
firstStr = myTree.keys()[0]
cntrPt = (plotTree.xoff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yoff)
plotMidTest(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yoff = plotTree.yoff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xoff = plotTree.xoff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xoff, plotTree.yoff), cntrPt, leafNode)
plotMidTest((plotTree.xoff, plotTree.yoff), cntrPt, str(key))
plotTree.yoff = plotTree.yoff + 1.0/plotTree.totalD
# figure points
# 画结点的模板
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, # 注释的文字,(一个字符串)
xy=parentPt, # 被注释的地方(一个坐标)
xycoords='axes fraction', # xy所用的坐标系
xytext=centerPt, # 插入文本的地方(一个坐标)
textcoords='axes fraction', # xytext所用的坐标系
va="center",
ha="center",
bbox=nodeType, # 注释文字用的框的格式
arrowprops=arrow_args) # 箭头属性
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111,frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xoff = -0.5/plotTree.totalW
plotTree.yoff = 1.0
plotTree(inTree, (0.5, 1.0),'') #树的引用作为父节点,但不画出来,所以用''
plt.show()
def getNumLeafs(myTree):
numLeafs = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ =='dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
# 子树中树高最大的那一颗的高度+1作为当前数的高度
def getTreeDepth(myTree):
maxDepth = 0 #用来记录最高子树的高度+1
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if(thisDepth > maxDepth):
maxDepth = thisDepth
return maxDepth
# 方便测试用的人造测试树
def retrieveTree(i):
listofTrees = [{'no surfacing':{0:'no',1:{'flippers':{0:'no',1:'yes'}}}},
{'no surfacing':{0:'no',1:{'flippers':{0:{'head':{0:'no',1:'yes'}},1:'no'}}}}
]
return listofTrees[i]
用上面给出的数据来建立一颗决策树做示范:
在同一个程序中输入如下代码并运行:
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing', 'flippers']
return dataSet, labels
myDat, labels = createDataSet()
myTree = createTree(myDat, labels)
print myTree
运行结果为:
{‘no surfacing’: {0: ‘no’, 1: {‘flippers’: {0: ‘no’, 1: ‘yes’}}}}
利用画决策树的代码可以画出这颗决策树:
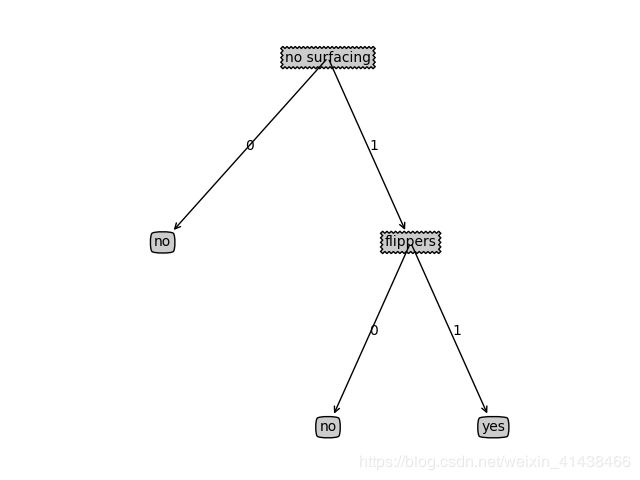
案例
我们通过建立决策树来预测患者需要佩戴哪种隐形眼镜(soft(软材质)、hard(硬材质)、no
lenses(不适合硬性眼睛)),数据集包含下面几个特征:age(年龄), prescript(近视还是远视),
astigmatic(散光), tearRate(眼泪清除率)
建树的结果为:
{‘tearRate’: {‘reduced’: ‘no lenses’, ‘normal’: {‘astigmatic’: {‘yes’:
{‘prescript’: {‘hyper’: {‘age’: {‘pre’: ‘no lenses’, ‘presbyopic’: ‘no
lenses’, ‘young’: ‘hard’}}, ‘myope’: ‘hard’}}, ‘no’: {‘age’: {‘pre’:
‘soft’, ‘presbyopic’: {‘prescript’: {‘hyper’: ‘soft’, ‘myope’: ‘no
lenses’}}, ‘young’: ‘soft’}}}}}}
画出来是这个样子:

2、C4.5决策树
3、CART决策树(Classification And Regression Tree)
决策树的优点和缺点
优点
能够进行可视化分析
可解释性强
能够处理确实数据
缺点
容易忽略属性之间的相关性
类别太多时错误可能就会增加的比较快