python机器学习第六章:模型评估与参数调优实战
使⽤代码进⾏实践,通过对算法进⾏调优来构建性能良好的机器学习模型,并对模型的性能进⾏评估。我们将学习如下内容:
1·模型性能的⽆偏估计
2·处理机器学习算法中常⻅问题
3·机器学习模型调优
4·使⽤不同的性能指标评估预测模型
基于流水线(pipline)的工作流
1.使用pandas从UCI网站直接读取数据集:

2.pipline对象拟合多个处理步骤的模型:

Pipeline对象采⽤元组的序列作为输⼊,其中每个元组中的第⼀个值为⼀个字符串,它可以是任意的标识符,我们通过它来访问流⽔线中的元素,⽽元组的第⼆个值则为scikit-learn中的⼀个转换器或者评估器。

2.使用k折交叉验证评估模型性能
交叉验证技术:holdout交叉验证(holdout cross-validation)和k折交叉验证(k-foldcross-validation)
借助于这两种⽅法,我可以得到模型泛化误差的可靠估计,即模型在新数据上的性能表现。
2.1 holdout方 法
使⽤holdout进⾏模型选择更好的⽅法是将数据划分为三个部分:训练数据集、验证数据集和测试数据集。
训练数据集⽤于不同模型的拟合,模型在验证数据集上的性能表现作为模型选择的标准。使用模型训练及模型
选择阶段不曾使⽤的数据作为测试数据集的优势在于:评估模型应⽤于新数据上能够获得较⼩偏差。
holdout⽅法的⼀个缺点在于:模型性能的评估对训练数据集划分为训练及验证⼦集的⽅法是敏感的。

2.2 k折交叉验证
在k折交叉验证中,我们不重复地随机将训练数据集划分为k个,其中k-1个⽤于模型的训练,剩余的1个⽤于测试。重复此过程k次,我们就得到了k个模型及对模型性能的评价。与holdout⽅法相⽐,这样得到的结果对数据划分⽅法的敏感性相对较低。
下图总结了k折交叉验证的相关概念,其中k=10。训练数据集被划分为10块,在10次迭代中,每次迭代都将9块⽤于训练,剩余的1块作为测试集⽤于模型的评估。此外,每次迭代中得到的性能评价指标Ei(例如,分类的准确性或者误差)可⽤来计算模型的估计平均性能E: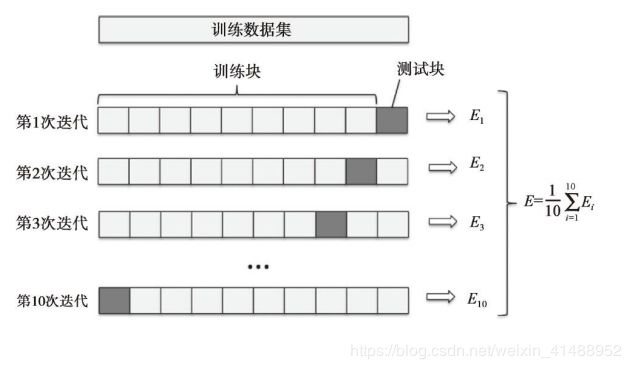
如果训练数据集相对较⼩,我们增⼤k的值,在每次迭代中将会有更多的数据⽤于模型的训练,这样通过计算各性能评估结果的平均值对模型的泛化性能进⾏评价时,可以得到较⼩的偏差。但是,k值的增加将导致交叉验证算法运⾏时间延⻓,⽽且由于各训练块间⾼度相似,也会导致评价结果⽅差较⾼。
另⼀⽅⾯,如果数据集较⼤,则可以选择较⼩的k值,如k=5,这不光能够降低模型在不同数据块上进⾏重复拟合和性能评估的计算成本,还可以在平均性能的基础上获得对模型的准确评估。
知识点:scikit-learn实现k折交叉验证评分的计算

cross_val_score⽅法具备⼀个极为有⽤的特点,它可以将不同分块的性能评估分布到多个CPU上进⾏处理。如果将n_jobs参数的值设为1,则与例⼦中使⽤的StratifiedKFold类似,只使⽤⼀个CPU对性能进⾏评估。如果设定n_jobs=2,我们可以将10轮的交叉验证分布到两块CPU(如果使⽤的计算机⽀持)上进⾏,如果设置n_jobs=-1,则可利⽤计算机所有的CPU并⾏地进⾏计算。
3. 通过学习及验证曲线来调试

左上⽅图像显⽰的是⼀个⾼偏差模型。此模型的训练准确率和交叉验证准确率都很低,这表明此模型未能很好地拟合数据。解决此问题的常⽤⽅法是增加模型中参数的数量,例如,收集或构建额外特征,或者降低类似于SVM和逻辑斯谛回归器等模型的正则化程度。
右上⽅图像中的模型⾯临⾼⽅差的问题,表明训练准确度与交叉验证准确度之间有很⼤差距。针对此类过拟合问题,我们可以收集更多的训练数据或者降低模型的复杂度,如增加正则化的参数;对于不适合正则化的模型,也可以通过第4章介绍的特征选择,或者第5章中的特征提取来降低特征的数量。
知识点:learning_curve绘制学习曲线
sklearn.model_selection.learning_curve(estimator, X, y, groups=None,
train_sizes=array([0.1, 0.33, 0.55, 0.78, 1. ]),
cv=’warn’, scoring=None,
exploit_incremental_learning=False,
n_jobs=None, pre_dispatch=’all’, verbose=0,
shuffle=False, random_state=None,
error_score=’raise-deprecating’)
Returns:
train_sizes:指定训练样本数量的变化规则,比如np.linspace(.1, 1.0, 5)表示把训练样本数量从0.1~1分成五等分,从[0.1, 0.33, 0.55, 0.78, 1. ]的序列中取出训练样本数量百分比,逐个计算在当前训练样本数量情况下训练出来的模型准确性。
train_scores : array, shape (n_ticks, n_cv_folds)
test_scores : array, shape (n_ticks, n_cv_folds)
在画训练集的曲线时:横轴为 train_sizes,纵轴为 train_scores_mean;
画测试集的曲线时:横轴为train_sizes,纵轴为test_scores_mean。
title:
图像的名字。
cv :
整数, 交叉验证生成器或可迭代的可选项,确定交叉验证拆分策略。
Determines the cross-validation splitting strategy. Possible inputs for cv are:
无,使用默认的3倍交叉验证;整数,指定折叠数;要用作交叉验证生成器的对象;可迭代的yielding训练/测试分裂。
ShuffleSplit:
我们这里设置cv,交叉验证使用ShuffleSplit方法,一共取得100组训练集与测试集,每次的测试集为20%,它返回的是每组训练集与测试集的下标索引,由此可以知道哪些是train,那些是test。
ylim:
tuple, shape (ymin, ymax), 可选的。定义绘制的最小和最大y值,这里是(0.7,1.01)。
n_jobs :
整数,可选并行运行的作业数(默认值为1)。windows开多线程需要在if “name” == “main”: 中运行
知识点:validation_curve绘制验证曲线
验证曲线与学习曲线相似,不过绘制的不是样本大小与训练准确率、测试准确率之间的函数关系,⽽是准确率与模型参数之间的关系,例如,逻辑斯谛回归模型中的正则化参数C。
train_scores, test_scores = validation_curve(
estimator=pipe_lr,
X=X_train,
y=y_train,
param_name='logisticregression__C',
param_range=param_range,
cv=10)
ROC AUC(recevier operator characteristic area under the curve)
https://blog.csdn.net/program_developer/article/details/79946787
理解查全率 查准率
(1)主要作用
- ROC曲线能很容易的查出任意阈值对学习器的泛化性能影响。
2.有助于选择最佳的阈值。ROC曲线越靠近左上角,模型的查全率就越高。最靠近左上角的ROC曲线上的点是分类错误最少的最好阈值,其假正例和假反例总数最少。
3.可以对不同的学习器比较性能。将各个学习器的ROC曲线绘制到同一坐标中,直观地鉴别优劣,靠近左上角的ROC曲所代表的学习器准确性最高。
AUC对样本类别是否均衡并不敏感,这也是不均衡样本通常用AUC评价学习器性能的一个原因。例如在癌症预测的场景中,假设没有患癌症的样本为正例,患癌症样本为负例,负例占比很少(大概0.1%),如果使用准确率评估,把所有的样本预测为正例便可以获得99.9%的准确率。但是如果使用AUC,把所有样本预测为正例,TPR为1,FPR为1。这种情况下学习器的AUC值将等于0.5,成功规避了样本不均衡带来的问题。