EMA计算(pandas之emw函数使用及设置)
在股市及其他金融领域中,经常需要进行指数加权平均计算,这个指标可以较好反应指数变动的趋势。
在python 中用pandas 的ewm函数可以很方便进行计算,但这个函数的说明过于复杂,大多数文章都很难清晰描述,而且原文也没有很好的中文译本。在使用过程中总对不上数据,经过反复实验,终于有了一些头绪,记录如下。
先看看指数移动平均值EMA的定义:
EMA(Exponential Moving Average)是指数移动平均值。也叫EXPMA指标,它也是一种趋向类指标,指数移动平均值是以指数式递减加权的移动平均。
EMA(today)=α * Price(today) + ( 1 - α ) * EMA(yesterday);
其中,α为平滑指数,一般取作2/(N+1)。典型的在计算MACD指标时,EMA计算中的N一般选取12和26天,因此α相应为2/13和2/27。
这里可以看到一个问题,如果是N>1,则存在EMA(0)的取值问题,一般可以取值EMA(0)= Price(0)
再看看这个函数的说明
pandas.Series.ewm:
Series.ewm(self, com=None, span=None, halflife=None, alpha=None, min_periods=0, adjust=True, ignore_na=False, axis=0)[source]
参数说明
com : 类型:浮点数;可选参数;定义有关质心的衰减参数(这个定义有点拗口,简单的说是用来定义α的一种方式, α=1/(1+com), for com≥0.)
span : 类型:浮点数;可选参数;定义有关时间窗口的衰减参数(这个定义好了一点,但依然不好理解,简单的说也是用来定义α的一种方式, α=2/(span+1), for span≥1.)
halflife : 类型:浮点数;可选参数;定义半生命周期的的衰减参数,太专业了,一般用的不太多,其实就是 α=1−exp(log(0.5)/halflife),for halflife>0.(公式复杂,本文不讨论了)
alpha : 类型:浮点数;可选参数;这个简单粗暴,就是直接定义平滑因子 α, 0<α≤1.
min_periods : 类型:整数,默认为0,表示窗口期取数的最小数量(翻译很拗口,有没有更好的?原文如下:Minimum number of observations in window required to have a value (otherwise result is NA). )。
adjust : 类型:布尔, 默认为 True。决定调整因子开始期间的计算方式,英文原文不容易翻译。
原文:Divide by decaying adjustment factor in beginning periods to account for imbalance in relative weightings (viewing EWMA as a moving average).
ignore_na : 类型 布尔, 默认 False,是否在加权计算中忽略Nan的值
axis : 类型 取值0 或1,分别代表是行还是列,默认为 0
返回值 为DataFrame,计算的结果
注意点:
(1)关系α因子的参数,包括com、span、half-life和 alpha 只能选一个,而且必须选一个。
(2)adjust 参数需要注意,在adjust值为默认True时, 加权平均是按如下因子计算:(1-alpha)(n-1), (1-alpha)(n-2), …, 1-alpha, 1.
当adjust值为False时,因子权重按如下当时计算:
weighted_average[0] = arg[0];
weighted_average[i] = (1-alpha)weighted_average[i-1] + alphaarg[i].
用下面两个式子比较直接(x表示时间序列如每日股价,y表示均值):
当 adjust=True
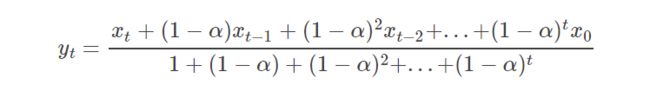
当adjust=Flase

这里可以看出是adjust=False时与EMA相符合。
(3)ignore_na 参数是用来表明如何处理空缺的值(Nan),当它是默认值False时,权重基于绝对位置,即不忽略Nan的值,只是不理而已,例如 the weights of x and y used in calculating the final weighted average of [x, None, y] are (1-alpha)**2 and 1 (if adjust is True), and (1-alpha)**2 and alpha (if adjust is False).
当ignore_na为True时, 权重计算就是基于相对位置,即忽略Nan的值,
(reproducing pre-0.15.0 behavior), weights are based on relative positions. For example, the weights of x and y used in calculating the final weighted average of [x, None, y] are 1-alpha and 1 (if adjust is True), and 1-alpha and alpha (if adjust is False).
看了上面的文字,依然会让人觉得很绕,不如看几个范例,就会比较清晰。
从上文中,我们至少知道了几点:
(1)计算EMA 需要使用参数adjust=False
(2)ignore_na 暂时不用理,可以看实际计算结果
(3)α因子取值方式其实有很多种,下例中不考虑半生命周期参数 halflife
范例:
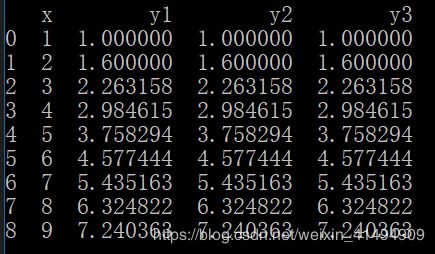
用 x=【1,2,3,4,5,6,7,8,9】来作为一个数列
若Y=EMA(X,N),则Y=[2*X+(N-1)*Y’]/(N+1),其中Y’表示上一周期的Y值。
EMA(x,0)=【1,2,3,4,5,6,7,8,9】
EMA(x,5)=【1.000000 ,1.333333 ,1.888889 ,2.592593 ,3.395062,
4.263374,5.175583,6.117055,7.078037】
对于EMA(x,5),α=2/(5+1)=1/3
那么用ewm函数,对应的可以用com,span,alpha参数,adjust=False
代码如下
# #一个人至少有一个梦想,有一个理由去坚强
import numpy as np
import pandas as pd
df=pd.DataFrame({'x':[1,2,3,4,5,6,7,8,9]})
df['y1']=df['x'].ewm(com=2,adjust=False).mean()
df['y2']=df['x'].ewm(span=5,adjust=False).mean()
df['y3']=df['x'].ewm(alpha=1/3.0,adjust=False).mean()
print(df)
运行结果:
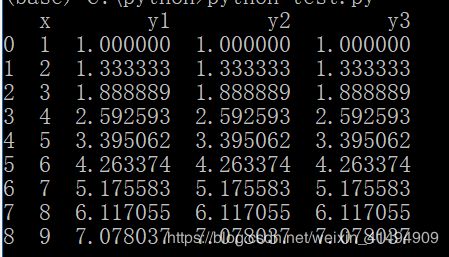
至于参数的其他用法,可以百度其他文章,可以说的是,如果参数设置不一样,如忽略adjust,则结果如下: