Java爬虫之利用Jsoup+HttpClient爬取类叔叔不约匿名聊天网站的图片,未果——后爬取某网站美女图片案例
博主最近学了一点爬虫的知识,闲着无聊,秉承学以致用的理念,于是突然想到何不挑战一下,爬取一些叔叔不约网站的图片,来巩固一下所学知识(#滑稽)。说干就干,打开eclipse或idea,创建maven工程,引入所需jar包的依赖:
org.apache.httpcomponents
httpclient
org.jsoup
jsoup
1.8.3
org.apache.commons
commons-lang3
3.9
org.apache.httpcomponents
httpclient
4.5.5
工程创建好了,可是怎么操作呢?于是博主打开了匿名网站,之前看到某位博主说"叔叔不约"的图片加入了反爬机制,已经爬取不了了。于是我百度了一下,找到了另外一个匿名聊天网站,名为"好像聊",网址“http://www.haoxiangliao.com/”.
博主刚开始设置性别男,匹配了半天没人理我,为了学习,咱拼了,于是我把性别设置为‘女’,果不其然,一堆青虫上脑男士都来找我聊天(#捂脸哭)。找到了一个男的,本来想发一张图片获取一下这张图片的url,可是这个网站不聊够3分钟不让发图片,于是我就假装妹子和男的聊了起来.....
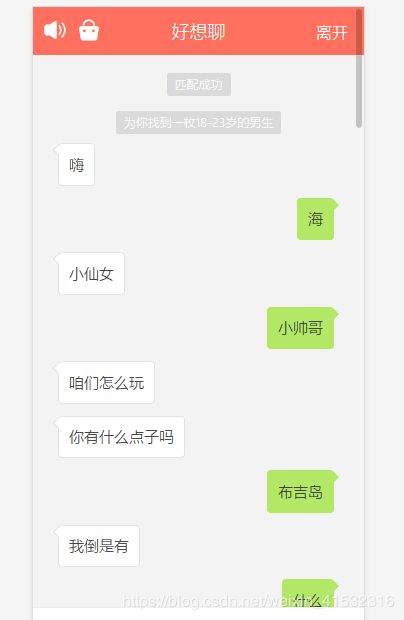
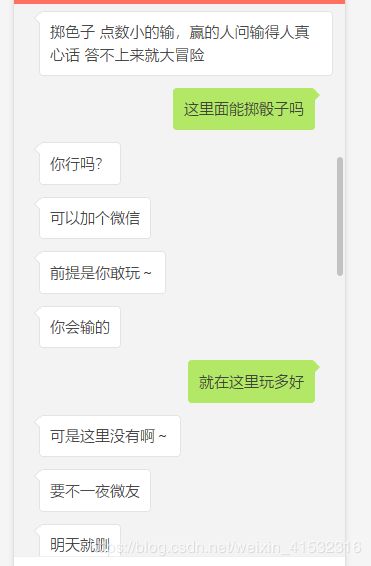
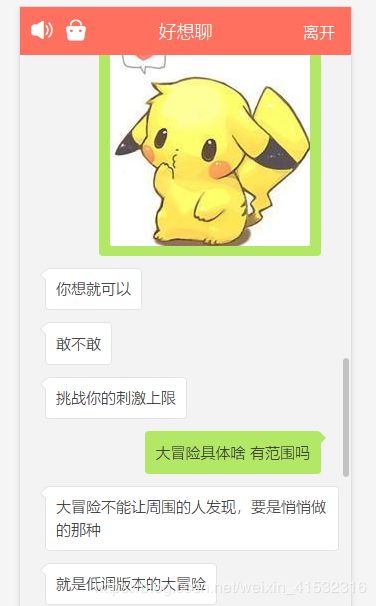
咳咳,发送了三张图片,完成了任务,就关了聊天(#口区)
打开F12,发现三张图片的url:
http://static.haoxiangliao.com/2019-08-30_23-32-48-167_31yvrwjgmpy.png
http://static.haoxiangliao.com/2019-08-30_23-34-39-991_614okhvblhb.png
http://static.haoxiangliao.com/2019-08-30_23-36-05-985_qouquv73gnn.jpg
分析一波,他把图片名字命名成了格式化时间+11位的随机字符串。
于是我思路就有了,用java获取格式化时间,并生成11位数字字母字符串,代码如下:
/**
* 获取格式化时间
*/
public String getTime() {
Date date = new Date();
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd_HH-mm-ss-SSS_");
String Formattime = dateFormat.format(date);
System.out.println("Formattime:" + Formattime);
return Formattime;
}
// 生成随机数字和字母
public String getStringRandom(int length) {
String val = "";
Random random = new Random();
// length为几位密码
for (int i = 0; i < length; i++) {
String charOrNum = random.nextInt(2) % 2 == 0 ? "char" : "num";
// 输出字母还是数字
if ("char".equalsIgnoreCase(charOrNum)) {
// 输出是大写字母还是小写字母
// int temp = random.nextInt(2) % 2 == 0 ? 65 : 97;
int temp = 97;
val += (char) (random.nextInt(26) + temp);
} else if ("num".equalsIgnoreCase(charOrNum)) {
val += String.valueOf(random.nextInt(10));
}
}
return val;有了格式化时间和随机字符串,可以创建图片url了,写一个死循环,循环调用生成时间与随机串的方法:
public void createUrl() {
getFormatPicName getFormatDate = new getFormatPicName();
int i = 0;
while (true) {
i++;
String stringRandom = getFormatDate.getStringRandom(11);
String time = getFormatDate.getTime();
System.out.print("第" + i + "次 ");
String picName = time + stringRandom;
System.out.println(time + stringRandom);
String url = "http://static.haoxiangliao.com/" + picName + ".jpg";
doGetImage(url);
}
}下载图片的方法:
/**
* 下载图片
* @param url
* @return 图片名称
*/
public String doGetImage(String url) {
// 获取httpClient对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(this.cm).build();
// 创建httpGet请求对象,设置url地址
HttpGet httpGet = new HttpGet(url);
// 设置请求信息
httpGet.setConfig(this.getConfig());
// 使用httpClient发起请求,获取响应
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
// 解析响应,返回结果
if (response.getStatusLine().getStatusCode() == 200) {
// 判断响应体Entity是否不为空,如果不为空,就可以使用Entityutils
if (response.getEntity() != null) {
// 下载图片
// 获取图片的后缀
String extName = url.substring(url.lastIndexOf("."));
// 创建图片图片名,重命名图片
String picName = UUID.randomUUID().toString() + extName;
// 下载图片
// 声明outputStream 完整文件路径
File file=new File("D:\\webCrawler\\pic\\");
if(!file.exists()&& !file.isDirectory()){
file.mkdirs(); //如果文件夹不存在,就创建
}
OutputStream outputStream = new FileOutputStream( file+"\\"+ picName);
response.getEntity().writeTo(outputStream);
// 返回图片名称
return picName;
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭response
if (response != null) {
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 如果下载失败,返回空串
return "";
}就这样,博主把电脑时间设置成前几天的半夜,开启了爬虫。爬了大概几个小时15万次,结果令人大失所望,是的,一张图片都没有,像这种网站的图片加密方式,能刚好随机到的概率几乎为零。(#允悲)
爬取匿名网站的想法虽然失败了,但是何不找一个美女网站来练习一下呢?百度了一个网站,“http://www.kunv.cc/index.html”,
准备拿到首页的几十张图片,思路大概不变,只需要加一个解析页面的逻辑即可,下边上完整代码,有兴趣的同学可以一试,毕竟咱们不为别的,就是为了学习嘛(#滑稽)。
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.UUID;
public class getPicTask {
public static void main(String[] args) throws Exception {
// 开启爬虫
new getPicTask().getPicTask();
}
private PoolingHttpClientConnectionManager cm;
public getPicTask() {
this.cm = new PoolingHttpClientConnectionManager();
// 设置最大连接数
this.cm.setMaxTotal(100);
// 设置每个主机最大连接数
this.cm.setDefaultMaxPerRoute(10);
}
public void getPicTask() throws Exception {
//解析地址
String url = "http://www.kunv.cc/index.html"; //首页
String html = doGetHtml(url);
parse(html);
}
/**
* 根据请求地址下载页面数据
*
* @param url
* @return 页面数据
*/
public String doGetHtml(String url) {
// 获取httpClient对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(this.cm).build();
// 创建httpGet请求对象,设置url地址
HttpGet httpGet = new HttpGet(url);
httpGet.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36");
// 设置请求信息
httpGet.setConfig(this.getConfig());
// 使用httpClient发起请求,获取响应
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
// 解析响应,返回结果
if (response.getStatusLine().getStatusCode() == 200) {
// 判断响应体Entity是否不为空,如果不为空,就可以使用Entityutils
if (response.getEntity() != null) {
String content = EntityUtils.toString(response.getEntity(), "utf8");
return content;
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭response
if (response != null) {
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 解析响应,返回结果
return "";
}
//解析页面获取图片url
private void parse(String html) throws Exception {
// 解析html获取Document对象
Document doc = Jsoup.parse(html);
// 获取图片url
Element element = doc.select("div.boxs").get(1);
Elements picTagsList = element.select("img[src$=.jpg]");
for (Element element1 : picTagsList) {
// 解析出了图片的url
String picUrl = element1.attr("src");
// 调用下载图片的方法
doGetImage("http://www.kunv.cc//"+picUrl);
}
System.out.println("---结束---");
}
// public void createUrl() {
// getFormatPicName getFormatDate = new getFormatPicName();
// int i = 0;
// while (true) {
// i++;
// String stringRandom = getFormatDate.getStringRandom(11);
// String time = getFormatDate.getTime();
// System.out.print("第" + i + "次 ");
// String picName = time + stringRandom;
// System.out.println(time + stringRandom);
// String url = "http://static.haoxiangliao.com/" + picName + ".jpg";
// doGetImage(url);
// }
// }
/**
* 下载图片
* @param url
* @return 图片名称
*/
public String doGetImage(String url) {
// 获取httpClient对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(this.cm).build();
// 创建httpGet请求对象,设置url地址
HttpGet httpGet = new HttpGet(url);
// 设置请求信息
httpGet.setConfig(this.getConfig());
// 使用httpClient发起请求,获取响应
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
// 解析响应,返回结果
if (response.getStatusLine().getStatusCode() == 200) {
// 判断响应体Entity是否不为空,如果不为空,就可以使用Entityutils
if (response.getEntity() != null) {
// 下载图片
// 获取图片的后缀
String extName = url.substring(url.lastIndexOf("."));
// 创建图片图片名,重命名图片
String picName = UUID.randomUUID().toString() + extName;
// 下载图片
// 声明outputStream 完整文件路径
File file=new File("D:\\webCrawler\\pic\\");
if(!file.exists()&& !file.isDirectory()){
file.mkdirs(); //如果文件夹不存在,就创建
}
OutputStream outputStream = new FileOutputStream( file+"\\"+ picName);
response.getEntity().writeTo(outputStream);
// 返回图片名称
return picName;
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭response
if (response != null) {
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 如果下载失败,返回空串
return "";
}
// 设置请求信息
private RequestConfig getConfig() {
RequestConfig config = RequestConfig.custom()
.setConnectTimeout(1000)
.setConnectionRequestTimeout(500)
.setSocketTimeout(10000) //数据传输的最长时间
.build();
return config;
}
}
有学习兴趣的自己分析一下代码,并不难,博主只是抛砖引玉,你可以改造一下,爬一下其他网站(#正经脸),或者把这个网站加翻页功能,爬取整个网站的图片。ok,完结撒花~感谢观看!
--------------------------------------分隔符-----------------------------------------
目前我重写了代码,把上边网站的所有图片都爬到了,有需要学术交流的同学,可以留言,我贴源码(19.09.04)。