| 这个作业属于哪个课程 | 班级链接 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | GitHub 使用,制定代码规范,独立开发一个疫情统计程序,学会需求分析、单元测试、覆盖率分析、性能分析,学会PSP表格 |
| 作业正文 | 本文 |
| 其他参考文献 | 单元测试与回归测试、JProfiler使用、相关博文 |
一、Github 仓库地址
Github仓库地址
二、PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 45 |
| Estimate | 估计这个任务需要多少时间 | 40 | 30 |
| Development | 开发 | 40 | 45 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 60 |
| Design Spec | 生成设计文档 | 40 | 40 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 600 | 360 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 240 |
| Reporting | 报告 | 120 | 90 |
| Test Report | 测试报告 | 100 | 120 |
| Size Measurement | 计算工作量 | 30 | 40 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 30 | 30 |
| 合计 | 1290 | 1240 |
三、解题思路描述

看完题目需求我将程序的功能大致分为三个模块:
1. 命令行参数解析
处理main函数传入的命令行参数数组,解析-log -out -type -date -province指令并作相应处理
2. 读取输入日志文件
根据-log 传入的目录读取日志文件,根据-date 传入的参数确定日期,然后就是解析文件的每行字符串,转换成数据,根据下标判断字符串就能区分所有情况
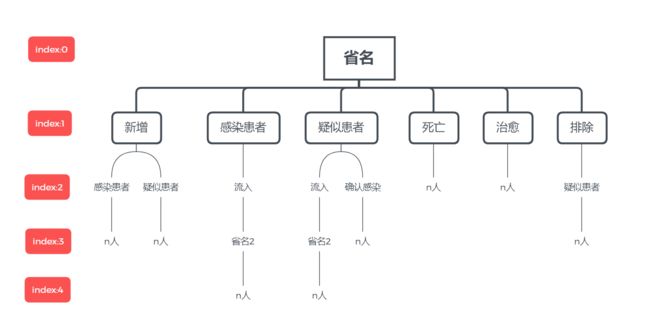
3. 输出统计文件
根据-out 传入的输出文件目录,若需要输出全国数据,则统计全国数据,并写入文件的第一行。之后将其他需要输出的省份数据统计之后,按照省份拼音先后顺序排序后输出
四、设计实现过程
-
程序模块设计

-
数据结构设计
- 写了一个Province类来存储和处理省份数据。
- 用HashMap
- 用ArrayList 分别实现了-province传入的省份列表,以及所有有数据的省份列表,用于排序。
-
关键函数流程
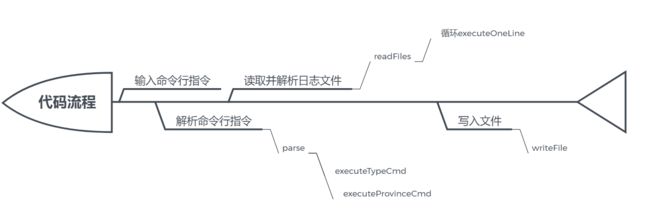
五、代码说明
-
存储省份数据的数据结构:
提供修改数据和输出数据的API
public class Province{ /** 省份名字 */ private String name; /** 感染患者数量 */ private long ip; /** 疑似患者数量 */ private long sp; /** 治愈患者数量 */ private long cure; /** 死亡患者数量 */ private long dead; //提供修改数据的API ... /** * description:获取要输出的统计数据 * @return 要输出的字符串 */ public String getOuputResult() { if (isShowAllData) { return getAllOuputResult(); } return getOuputResultByTypes(typeList); } /** * description:获取要输出的全部统计数据 * @return 要输出的字符串 */ private String getAllOuputResult() { String res = name + ' ' + "感染患者" + ip + "人" + ' ' + "疑似患者" + sp + "人" + ' ' + "治愈" + cure + "人" + ' ' + "死亡" + dead + "人"; return res; } /** * description:通过命令行指令参数获取要输出的统计结果 * @param types 命令行参数类型数组 * @return 要输出的字符串 */ private String getOuputResultByTypes(ArrayListtypes) { String res = name + " "; for (int i = 0; i < types.size(); i++) { switch (types.get(i)) { case Constants.TYPE_IP: res += "感染患者" + ip + "人 "; break; case Constants.TYPE_SP: res += "疑似患者" + sp + "人 "; break; case Constants.TYPE_CURE: res += "治愈" + cure + "人 "; break; case Constants.TYPE_DEAD: res += "死亡" + dead + "人 "; break; default: break; } } return res; } } -
用一个常数类来存储常数:
防止打错,不好debug和修改
public static class Constants{ private static final int NUM_PROVINCE = 34; private static final int NUM_TYPE = 4; private static final String TYPE_IP = "ip"; private static final String TYPE_SP = "sp"; private static final String TYPE_CURE = "cure"; private static final String TYPE_DEAD = "dead"; private static final String CMD_LOG = "-log"; private static final String CMD_OUT = "-out"; private static final String CMD_DATE = "-date"; private static final String CMD_TYPE = "-type"; private static final String CMD_PROVINCE = "-province"; } -
循环解析命令行参数数组:
若传入-Date 则将isReadALL标志设为false,表示不需要读取所有日志文件,若没有传入则默认传入的日期为当前日志文件的最新日期
-type和-province的参数分别存入相应的数组中,等待后续的调用,将相应标志设为false,表示不需要全部输出,而是从列表中选择性输出
private void parse() { for (int i = 1; i < args.length; i++) { switch (args[i]) { case Constants.CMD_DATE: isReadAll = false; date = args[++i]; break; case Constants.CMD_LOG: logPath = args[++i]; break; case Constants.CMD_OUT: outputPath = args[++i]; break; case Constants.CMD_TYPE: isShowAllData = false; i = executeTypeCmd(i + 1) - 1; break; case Constants.CMD_PROVINCE: isShowAllProvince = false; i = executeProvinceCmd(i + 1) - 1; break; default: break; } } } -
读取并解析文件:
如果日志文件夹错误或者日期参数超出范围,都会报错提前结束程序,而不会写入文件操作
日期没有问题则比较传入日期与获取的文件名的日期,小于传入日期就循环读取解析文件每行的信息
private void readFiles() { File file = new File(logPath); File[] logFiles = file.listFiles(); if (logFiles.length == 0) { System.out.println("当前文件夹下没有日志文件!路径:" + logPath); isEnd = true; return; } if (isReadAll == false) { //比较输入日期与最新日期 String lastestDate = getLastestData(logFiles); if (date.compareTo(lastestDate) > 0) { System.out.println("日期超出范围,当前最新日期为:" + lastestDate); isEnd = true; return; } } //读取日志文件 for (int i = 0; i < logFiles.length; i++) { String logDate = logFiles[i].getName().split("\\.")[0]; if (isReadAll || date.compareTo(logDate) >= 0) { try { BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(logFiles[i]), "UTF-8"));; String line = new String(); while ((line = br.readLine()) != null){ String[] datas = line.split(" "); //读取并处理单行数据 executeOneLine(datas); } //单个文件读取完毕 br.close(); } catch (Exception e) { e.printStackTrace(); } } } //文件全部读取完毕 } -
处理文件每行的信息:
根据需求分析所述,将文件单行数据用空格分隔,解析字符串数组,对不同情况进行分类,调用该省份对象的方法来处理变动的数据
如果省份为第一次出现,则创建新的对象,并加入哈希表中存储,否则直接按名从哈希表中获取对象
private void executeOneLine(String[] datas) { //忽略注释行 if(datas[0].equals("//")) { return; } String provinceName = datas[0]; Province prov = getProvinceByKey(provinceName); //根据不同情况进行处理 switch (datas[1]) { case "死亡": prov.increaseDead(datas[2]); break; case "治愈": prov.increaseCure(datas[2]); break; case "新增": if (datas[2].equals("感染患者")) { prov.increaseIp(datas[3]); } else { //新增疑似患者 prov.increaseSp(datas[3]); } break; case "排除": //排除疑似患者 prov.decreaseSp(datas[3]); break; case "疑似患者": if (datas[2].equals("确诊感染")) { //疑似患者确诊 prov.increaseIpBySpConfirmed(datas[3]); } else { //疑似患者流入他省 Province prov2 = getProvinceByKey(datas[3]); prov.decreaseSp(datas[4]); prov2.increaseSp(datas[4]); } break; case "感染患者": //感染患者流入他省 Province prov2 = getProvinceByKey(datas[3]); prov.decreaseIp(datas[4]); prov2.increaseIp(datas[4]); break; default: System.out.println("日志格式可能出现错误!解析失败!"); break; } } -
写入文件:
优先统计并写入全国的数据,若不需要输出全国则跳过
根据type参数来判定输出哪些省份,默认为全部省份,对省份列表进行排序之后依次写入文件
private void writeFile() { //若中途出错则直接结束程序 if (isEnd) { return; } try { BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outputPath), "UTF-8")); //判断输出列表是否包含全国 if (isShowAllProvince || isOuputNationwide()) { //打印全国数据 Province nation = getNationStatResult(); bw.write(nation.getOuputResult()); bw.newLine(); } if (isShowAllProvince == false) { //输出参数传入的省份 //provinceArgsList.sort(new ProvinceCompartor()); Collections.sort(provinceArgsList, Collator.getInstance(java.util.Locale.CHINA)); for (String name : provinceArgsList) { if (!name.equals("全国")) { bw.write(provinceHashtable.get(name).getOuputResult()); bw.newLine(); } } } else { //输出所有省份 //allProvinceList.sort(new ProvinceCompartor()); Collections.sort(allProvinceList, Collator.getInstance(java.util.Locale.CHINA)); for (String name : allProvinceList) { bw.write(provinceHashtable.get(name).getOuputResult()); bw.newLine(); } } bw.close(); System.out.println("文件写入完毕."); } catch (Exception e) { e.printStackTrace(); } }
六、单元测试截图和描述(总共写了十个测试例子 都运行成功)
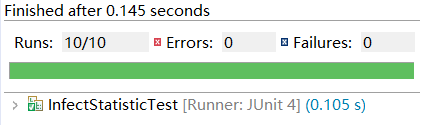
1. Test1 测试基础命令 只有 -log 和 -out 输出结果正确


2. Test2 测试 -date 传入日期参数 读取单个文件数据 输出结果正确


3. Test3 测试读取多个文件,并加入-type参数 输出结果正确


4. Test4 测试加入-province参数 日志中未出现香港,则数据为0 输出结果正确


5. Test5 测试-province参数 加入全国 排序正确 输出结果正确


6. Test6 测试-type 和-province复合参数,输出结果正确


7. Test7 测试-date 传入日志文件没有的日期,则当天数据为0 输出结果正确


8. Test8 测试-date 传入日期超过日志文件的最新日期,命令行给出输入错误提示

![]()
9. Test9 测试命令行指令错误检测是否成功,输入asd指令,命令行给出命令不存在提示

![]()
10. Test10 综合测试所有指令,并加入多个省份包括全国,查看排序是否正确,最终输出结果正确


七、单元测试覆盖率优化和性能测试
单元测试覆盖率
删除了一些没有用到的方法之后,主类覆盖率为95.7%,其余没有覆盖到的都是异常处理部分的代码
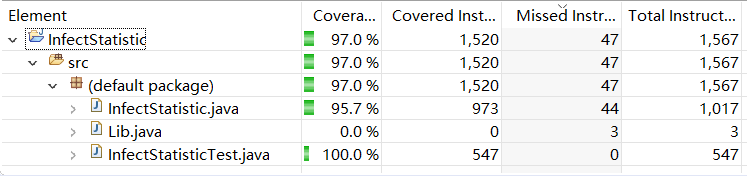
JProfiler 性能报告总览:

内存使用情况:

八、代码规范链接
代码规范 codestyle.md
九、心路历程与收获
心路历程:第一次看到题目时,因为没有相关开发经验,我看不懂那些命令行指令是什么意思,不知道怎么实现,导致逃避了很久,先去学Unity相关的东西了,拖到后面才意识到已经快到截止日期,于是上网搜索了相关资料,才发现原来是这么简单的东西,好在文件处理的需求也很简单,最后花了两三天赶完了,但程序的架构却是非常草率,运行效率也不高,然后代码写完才知道要做单元测试,没有事先设计好测试代码全程测试,导致单元测试没有起到什么作用,代码设计时也没有考虑如何测试,导致测试代码只能跑完全程,都怪我当初太懒,如果第一时间我就去想办法解决需求的话,就有更多的时间思考代码的设计,程序的质量应该会得到显著的提升,也就能收获更多东西。
收获:最大的收获就是学会了单元测试和回归测试的概念,还有PSP表格,也懂得了开发一个程序最重要的不是编写代码,而是需求分析,在具体编码前就要做足一系列的设计工作,对开发过程各个环节做出时间的合理预估,才能更充分的安排时间,让开发过程更有效率,开发软件是一项工程,就像建筑一样,同样需要有详细的设计图和工程管理方案,才不会导致建到一半才发现存在各式各样的问题,那样付出的代价是非常大的,所以程序设计和项目管理也是非常重要的一环。
十、技术路线图相关的 5 个仓库
-
像素宝可梦风格引擎
这个项目附带了从宝可梦系列视频游戏中提取的数据和图形。这个项目的目标不是创建和/或发布一个游戏,而是学习如何在Unity中创建类似的游戏。因此,这个项目除了可能成为未来类似项目的基础引擎之外,与宝可梦专营权无关,主要具有教育目的。
-
Unity-Design-Pattern
各种设计模式的Unity3D C#版本实现。
-
Entitas框架
Entitas是一个专门为C#和Unity制作的超快速实体组件系统框架(ECS)。
-
QFramework
是一套渐进式的快速开发框架。
-
ML-Agents ToolKit
ML-Agents ToolKit是一个开源的Unity3D机器学习插件,它使游戏和模拟能够作为智能代理培训的环境。