机器学习之线性回归原理与Python实现
线性回归
线性回归研究自变量(X)和因变量(Y)之间的关系。其中自变量和因变量满足线性关系。
本章节主要内容是线性回归的原理和实现。
1.线性回归原理
1.1一个例子开始
设X和Y满足以下多元一次方程关系:
x 11 w 1 + x 12 w 2 + x 13 w 3 + . . . + x 1 j w j + . . . + x 1 m w m + b = y ^ 1 x_{11} w_1 + x_{12} w_2 + x_{13} w_3 + ... + x_{1j} w_j + ... + x_{1m} w_m + b = \hat y_1 x11w1+x12w2+x13w3+...+x1jwj+...+x1mwm+b=y^1
x 21 w 1 + x 22 w 2 + x 23 w 3 + . . . + x 2 j w j + . . . + x 2 m w m + b = y ^ 2 x_{21} w_1 + x_{22} w_2 + x_{23} w_3 + ... + x_{2j} w_j + ... + x_{2m} w_m + b = \hat y_2 x21w1+x22w2+x23w3+...+x2jwj+...+x2mwm+b=y^2
x 31 w 1 + x 32 w 2 + x 33 w 3 + . . . + x 3 j w j + . . . + x 3 m w m + b = y ^ 3 x_{31} w_1 + x_{32} w_2 + x_{33} w_3 + ... + x_{3j} w_j + ... + x_{3m} w_m + b = \hat y_3 x31w1+x32w2+x33w3+...+x3jwj+...+x3mwm+b=y^3
. . . ... ...
x n 1 w 1 + x n 2 w 2 + x n 3 w 3 + . . . + x n j w j + . . . + x n m w m + b = y ^ n x_{n1} w_1 + x_{n2} w_2 + x_{n3} w_3 + ... + x_{nj} w_j + ... + x_{nm} w_m + b = \hat y_n xn1w1+xn2w2+xn3w3+...+xnjwj+...+xnmwm+b=y^n
其中 x i j x_{ij} xij代表地第 i i i个样本的第 j j j个特征值, y i y_i yi代表第 i i i个样本的预测结果, w w w和 b b b是参数,样本数总共为n个,每个样本的特征数量为m。
为方便起见,记
x i = [ x i 1 , x i 2 , x i 3 , . . . , x i m ] x_i = [x_{i1}, x_{i2}, x_{i3}, ..., x_{im}] xi=[xi1,xi2,xi3,...,xim]
w = [ w 1 , w 2 , w 3 , . . . , w m ] T w = {[w_1, w_2, w_3, ..., w_m]}^T w=[w1,w2,w3,...,wm]T
则对于每一组样本有:
y ^ i = x i w + b \hat y_i = x_i w + b y^i=xiw+b
1.2求解参数
记 y i y_i yi为第 i i i个样本的实际观测值, y ^ i \hat y_i y^i为第 i i i个样本的预测值,
ϵ i = y i − y ^ i \epsilon_i=y_i - \hat y_i ϵi=yi−y^i代表第 i i i个样本的预测误差
假设预测误差服从高斯分布:
p ( ϵ i ) = 1 2 π σ e x p ( − ϵ 2 2 σ 2 ) p(\epsilon_i) = \frac {1}{\sqrt{2 \pi} \sigma} exp (-\frac {\epsilon^2}{2 \sigma^2}) p(ϵi)=2πσ1exp(−2σ2ϵ2)
则:
p ( y i ∣ x i ; w , b ) = 1 2 π σ e x p ( − ( x i w + b − y i ) 2 2 σ 2 ) p(y_i|x_i; w,b) = \frac {1}{\sqrt{2 \pi} \sigma} exp (-\frac {{(x_i w + b - y_i)}^2}{2 \sigma^2}) p(yi∣xi;w,b)=2πσ1exp(−2σ2(xiw+b−yi)2)
对所有样本进行最大似然估计:
L ( y ∣ x ; w , b ) = ∏ i = 1 n 1 2 π σ e x p ( − ( x i w + b − y i ) 2 2 σ 2 ) L(y|x;w,b) = \prod_{i=1}^{n} \frac {1}{\sqrt{2 \pi} \sigma} exp (-\frac {{(x_i w + b - y_i)}^2}{2 \sigma^2}) L(y∣x;w,b)=i=1∏n2πσ1exp(−2σ2(xiw+b−yi)2)
此处可以这样理解预测误差的最大似然:
1.高斯分布表示了在横坐标(预测误差)值为0的中间位置纵坐标(概率值)越大,且距离中间位置越远,概率值越小;
2.最大似然估计趋向于总体样本的概率值大的方向,也就是趋向于预测误差为零的方向。
为了方便计算,取最大似然估计的对数:
log L ( y ∣ x ; w , b ) = log ∏ i = 1 n 1 2 π σ e x p ( − ( x i w + b − y i ) 2 2 σ 2 ) \log L(y|x;w,b) = \log \prod_{i=1}^{n} \frac {1}{\sqrt{2 \pi} \sigma} exp (-\frac {{(x_i w + b - y_i)}^2}{2 \sigma^2}) logL(y∣x;w,b)=logi=1∏n2πσ1exp(−2σ2(xiw+b−yi)2)
log L ( y ∣ x ; w , b ) = log ∏ i = 1 n 1 2 π σ e x p ( − ( x i w + b − y i ) 2 2 σ 2 ) = ∑ i = 1 n log 1 2 π σ e x p ( − ( x i w + b − y i ) 2 2 σ 2 ) = n log 1 2 π σ + ∑ i = 1 n ( − ( x i w + b − y i ) 2 2 σ 2 ) = n log 1 2 π σ − 1 2 σ 2 ∑ i = 1 n ( x i w + b − y i ) 2 \begin{aligned} \log L(y|x;w,b) &= \log \prod_{i=1}^{n} \frac {1}{\sqrt{2 \pi} \sigma} exp (-\frac {{(x_i w + b - y_i)}^2}{2 \sigma^2}) \\ &= \sum_{i=1}^{n} \log \frac {1}{\sqrt{2 \pi} \sigma} exp (-\frac {{(x_i w + b - y_i)}^2}{2 \sigma^2}) \\ &= n\log \frac {1}{\sqrt{2 \pi} \sigma} + \sum_{i=1}^{n} (-\frac {{(x_i w + b - y_i)}^2}{2 \sigma^2}) \\ &= n\log \frac {1}{\sqrt{2 \pi} \sigma} - \frac{1}{2 \sigma^2} \sum_{i=1}^{n} {(x_i w + b - y_i)}^2 \\ \end{aligned} logL(y∣x;w,b)=logi=1∏n2πσ1exp(−2σ2(xiw+b−yi)2)=i=1∑nlog2πσ1exp(−2σ2(xiw+b−yi)2)=nlog2πσ1+i=1∑n(−2σ2(xiw+b−yi)2)=nlog2πσ1−2σ21i=1∑n(xiw+b−yi)2
我们依据最大似然估计想要得到的是:
max log L ( y ∣ x ; w , b ) \max \log L(y|x;w,b) maxlogL(y∣x;w,b)
由于 n log 1 2 π σ n \log \frac {1}{\sqrt{2 \pi} \sigma} nlog2πσ1是常数
且 1 σ 2 \frac{1}{\sigma^2} σ21也是常数,所以原式等价于:
min J ( w , b ) = 1 2 ∑ i = 1 n ( x i w + b − y i ) 2 (1) \min J(w,b) = \frac{1}{2} \sum_{i=1}^{n} {(x_i w + b - y_i)}^2 \tag1 minJ(w,b)=21i=1∑n(xiw+b−yi)2(1)
公式(1)也是损失函数,线型模型的损失函数也就是均方误差。
参数是 w w w和 b b b,对参数进行求导:
∂ J ( w , b ) ∂ w j = ∑ i = 1 n ( x i w + b − y i ) x i j (2) \frac {\partial J(w, b)}{\partial w_j} = \sum_{i=1}^{n} {(x_i w + b - y_i)} x_{ij} \tag2 ∂wj∂J(w,b)=i=1∑n(xiw+b−yi)xij(2)
∂ J ( w , b ) ∂ b = ∑ i = 1 n ( x i w + b − y i ) (3) \frac {\partial J(w, b)}{\partial b} = \sum_{i=1}^{n} {(x_i w + b - y_i)} \tag3 ∂b∂J(w,b)=i=1∑n(xiw+b−yi)(3)
可以用梯度下降法进行对 w w w和 b b b进行求解:
w j = w j − α ∑ i = 1 n ( x i w + b − y i ) x i j w_j = w_j - \alpha \sum_{i=1}^{n} {(x_i w + b - y_i)} x_{ij} wj=wj−αi=1∑n(xiw+b−yi)xij
b = b − α ∑ i = 1 n ( x i w + b − y i ) b = b - \alpha \sum_{i=1}^{n} {(x_i w + b - y_i)} b=b−αi=1∑n(xiw+b−yi)
也可以随机梯度下降法(SGD):
for i=1 to n:
w j = w j − α ( x i w + b − y i ) x i j w_j = w_j - \alpha {(x_i w + b - y_i)} x_{ij} wj=wj−α(xiw+b−yi)xij
b = b − α ( x i w + b − y i ) b = b -\alpha {(x_i w + b - y_i)} b=b−α(xiw+b−yi)
当然也可以用批量随机梯度下降法,即循环多次,每次从样本中随机取出一部分样本迭代参数。上式中 α \alpha α为学习率。
2.线性回归的代码实现
线性回归模型实现
import numpy as np
class MyLinearRegression(object):
def __init__(self, lr=0.01, n_epoch=50):
"""
线型回归模型,通过随机梯度下降法实现
:param lr: 学习率,默认值0.01
:param n_epoch: 训练循环次数,默认值50
"""
self.lr = lr
self.n_epoch = n_epoch
self.params = {'w': None, 'b': 0}
def __init_params(self, m):
"""
初始化参数,正态分布
:param m: 特征维度数,和w的个数相对应
:return: None
"""
self.params['w'] = np.random.randn(m)
def fit(self, X, y):
"""
训练模型,随机梯度下降法训练模型
w_j = w_j - lr * (x_i @ w - y_i) * x_ij
b = b - lr * (x_i @ w - y_i)
:param X: 训练数据X,shape(n, m), n代表训练样本个数,m代表每个样本的特征维度数
:param y: 训练数据y, shape(n)
:return: None
"""
X = np.array(X)
# n 样本数量, m 一个样本的特征维度数量
n, m = X.shape
self.__init_params(m)
for _ in range(self.n_epoch):
for x_i, y_i in zip(X, y):
for j in range(m):
self.params['w'][j] = self.params['w'][j] - self.lr * (np.dot(x_i, self.params['w'].T) + self.params['b'] - y_i) * x_i[j]
self.params['b'] = self.params['b'] - self.lr * (np.dot(x_i, self.params['w'].T) + self.params['b'] - y_i)
def predict(self, X):
"""
预测模型结果
:param X: 二维数据,shape(n,m),n代表个数,m代表单个样本的维度数
:return: y shape(n), 预测结果
"""
return np.dot(X, self.params['w'].T) + self.params['b']
验证结果,首先生成测试样本:
def get_samples(n_ex=100, n_classes=100, n_in=1, seed=0):
# 生成100个样本,为了能够在二维平面上画出图线表示出来,每个样本的特征维度设置为1
from sklearn.datasets.samples_generator import make_blobs
from sklearn.model_selection import train_test_split
X, y = make_blobs(
n_samples=n_ex, centers=n_classes, n_features=n_in, random_state=seed
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=seed
)
return X_train, y_train, X_test, y_test
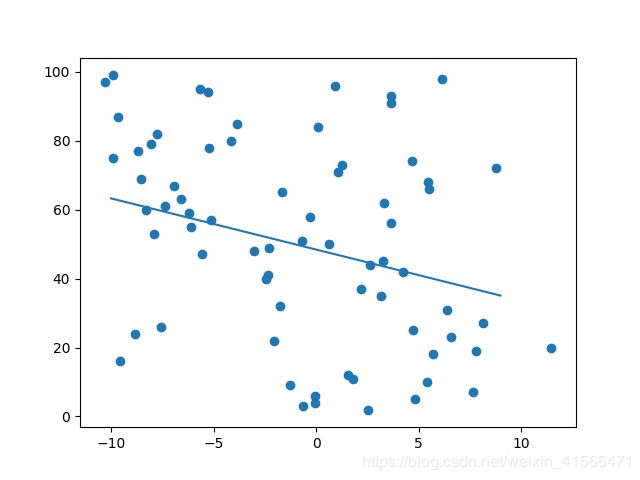
运行模型并画图观察效果:
def run_my_model():
from matplotlib import pyplot as plt
my = MyLinearRegression()
X_train, y_train, X_test, y_test = get_samples()
my.fit(X_train, y_train)
params = my.params
w = params['w'][0]
b = params['b']
x_list = [i for i in range(-10, 10)]
y_list = [w * x + b for x in x_list]
plt.plot(x_list, y_list)
plt.scatter(X_train, y_train)
plt.show()
y_pred = my.predict(X_test)
print(y_pred, y_test)