作者:Tom HardyDate:2020-04-15来源:CVPR2020文章汇总 | 点云处理、三维重建、姿态估计、SLAM、3D数据集等(12篇)
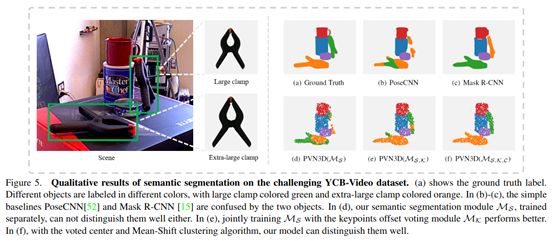
1.PVN3D: A Deep Point-wise 3D Keypoints Voting Network for 6DoF PoseEstimation
文章链接:https://arxiv.org/abs/1911.04231
代码链接:https://github.com/ethnhe/PVN3D
在这项工作中,论文提出了一种新的数据驱动下的方法,可以从单一的RGB-D图像中进行鲁棒的6自由度物体姿态估计。与往前直接回归姿态参数的方法不同,本文使用基于关键点的方法来处理这一具有挑战性的任务。具体地说,提出了一个深度Hough投票网络来检测物体的三维关键点,并使用最小二乘拟合的方式估计6D姿态参数。论文的方法是二维关键点方法的自然扩展,成功地用于基于RGB的六自由度估计。它可以充分利用具有额外深度信息的刚性物体的几何约束,便于网络学习和优化。通过大量的实验验证了三维关键点检测在6D姿态估计任务中的有效性。实验结果还表明,论文的方法在多个基准上都比最新的方法有很大的性能提升。

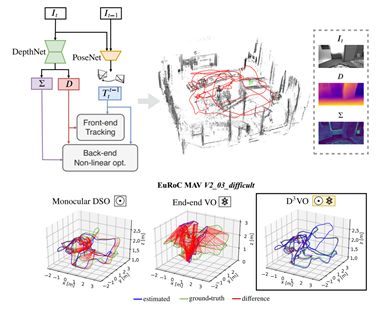
2.D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular VisualOdometry
论文链接:https://arxiv.org/abs/2003.01060
论文提出D3VO作为一个新的单目视觉里程测量框架,它利用深度、姿态和不确定性三个层次的深层网络。本文首先提出了一种新的无需外部监控的立体视频单目深度估计网络,它通过预测亮度变换参数将训练图像对对齐到相似的照明条件中。此外,还对输入图像上像素的光度不确定性进行了建模,提高了深度估计的精度,并为直接(无特征)视觉里程测量中的光度残差提供了学习的加权函数。评价结果表明,网络的性能优于现有的自监督深度估计网络。D3VO将预测的深度、姿态和不确定性紧密地结合到一种直接的视觉里程测量方法中,既提高了前端跟踪性能,又提高了后端非线性优化性能。论文在KITTI odometry基准和EuRoC MAV数据集上根据单目视觉里程计评估D3VO。结果表明,D3VO算法在很大程度上优于目前最先进的单目VO算法。它在仅使用一个摄像头下还获得了与KITTI上最先进的立体声/激光雷达里程表和EuRoC MAV上最先进的视觉惯性里程表相当的结果。

3.Total3DUnderstanding: Joint Layout, Object Pose and MeshReconstruction for Indoor Scenes from a Single Image
论文链接:http://arxiv.org/abs/2002.12212v1
室内场景的语义重建是指场景理解和物体重建。现有的工作要么解决这个问题的一部分,要么关注独立的对象。本文将理解与重建之间的鸿沟联系起来,提出了一种端到端的方法来从单个图像中联合重建房间布局、对象边界框和网格。本文的方法没有分别解决场景理解和对象重建问题,而是建立在整体场景上下文的基础上,提出了一个由粗到细的层次结构,该层次结构由三个部分组成:带相机姿势的房间布局、三维对象边界框、对象网格。我们认为,理解每个组件的上下文有助于解析其他组件,从而实现联合理解和重构。在SUN-RGBD和Pix3D数据集上的实验表明,该方法在室内布局估计、三维目标检测和网格重建方面均优于现有方法。




4.RPM-Net: Robust Point Matching using Learned Features
论文链接:http://arxiv.org/abs/2003.13479v1
代码链接:https://github.com/yewzijian/RPMNet
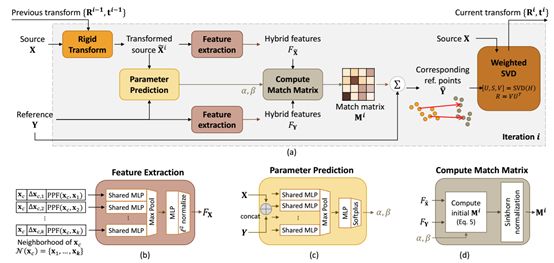
迭代最近点法(ICP)分两步迭代求解刚性点云配准问题:(1)对空间上最近点对应关系进行硬赋值,然后(2)求出最小二乘刚性变换。基于空间距离的最近点对应的硬赋值对初始刚性变换和噪声/离群点敏感,往往导致ICP收敛到错误的局部极小值。本文提出了RPM网络,一种对初始化不敏感的基于深度学习的刚性点云配准方法。网络使用可微Sinkhorn层和退火算法从空间坐标和局部几何中学习的混合特征中获得点对应的软分配。为了进一步提高配准性能,论文引入二次网络来预测最优退火参数。与某些现有方法不同,RPM网络可以处理缺少的对应关系和部分可见性的点云。实验结果表明,与现有的非深度学习和最新的深度学习方法相比,本文的RPM网络达到了SOTA。

5.Learning multiview 3D point cloud registration
论文链接:https://arxiv.org/abs/2001.05119v2
代码链接:https://github.com/zgojcic/3D_multiview_reg
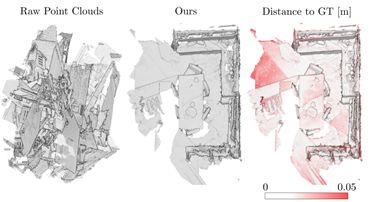
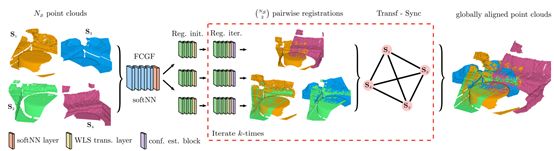
论文提出了一种新的、端到端可学习的多视点三维点云配准算法。多个扫描的注册通常遵循两个阶段的流程:初始成对对齐和全局一致优化。前者由于相邻点云重叠程度低、对称性强、场景部分重复等原因,往往具有模糊性。因此,后一种全局求精旨在建立跨多个扫描的循环一致性,并有助于解决不明确的情况。本文提出了第一个端到端的算法来联合学习这两个阶段的问题。在公认的基准数据集上进行的实验评估表明,论文的方法比目前最先进的方法有显著的优势,同时具有端到端可训练和计算成本较低的特点。此外,还提出了详细的分析和消融研究,验证了论文方法的新组成部分。
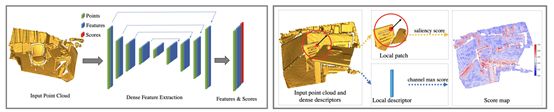
6.D3Feat: Joint Learning of Dense Detection and Description of 3DLocal Features
论文链接:http://arxiv.org/abs/2003.03164v1
代码链接:https://github.com/XuyangBai/D3Feat
一个成功的点云配准通常依赖于通过区分三维局部特征建立稀疏匹配。尽管基于学习的三维特征描述子的发展很快,但是对于三维特征检测器的学习却没有引起足够的重视,更不用说对这两个任务的联合学习了。本文利用三维全卷积网络对三维点云进行学习,提出了一种新的、实用的学习机制,该学习机制可以对每个三维点的检测分数和描述特征进行密集预测。特别地,提出了一种克服三维点云固有密度变化的关键点选择策略,并进一步提出了一种在训练过程中由实时特征匹配结果引导的自监督检测器损耗。最后,本文的方法在室内和室外场景下都取得了最新的结果,在3DMatch和KITTI数据集上进行了评估,并在ETH数据集上显示出了很强的泛化能力。在实际应用中,采用可靠的特征检测器,对少量特征进行采样,就可以实现精确快速的点云对齐。
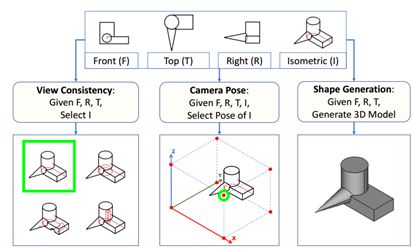
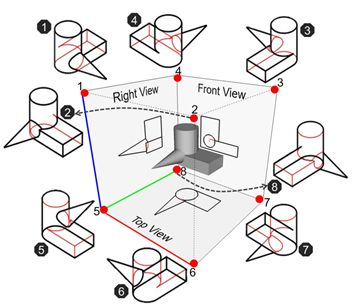
7.SPARE3D: A Dataset for SPAtial REasoning on Three-View Line Drawings
论文链接:http://arxiv.org/abs/2003.14034v1
数据集链接:https://ai4ce.github.io/SPARE3D
空间推理是人类智能的重要组成部分。我们可以想象三维物体的形状和它们的空间关系的原因,只需在二维中查看它们的三个视图线,它们具有不同的层次
能力。深层网络能被训练来执行空间推理任务吗?我们如何测量他们的“空间智能”?为了回答这些问题,论文展示了SPARE3D数据集。基于认知科学和心理测量学,SPARE3D包含视图一致性、相机姿态和形状生成三种类型的2D-3D推理任务,难度越来越大。我们设计了一种方法来自动生成大量具有挑战性的问题,每个任务都有基本的真实答案。它们用于提供监督,以使用最先进的架构(如ResNet)来培训基线模型。实验表明,尽管卷积网络在许多视觉学习任务中都取得了超人的性能,但它们在SPARE3D中的空间推理性能几乎等同于随机猜测。
我们希望SPARE3D能够激发新的空间推理问题公式和网络设计,使智能机器人能够通过二维传感器在三维世界中有效地工作。
8.InPerfectShape: Certifiably Optimal 3D Shape Reconstruction from 2DLandmarks
论文链接:http://arxiv.org/abs/1911.11924v2
本文研究了从单个图像中提取的二维地标进行三维形状重建的问题。采用三维可变形形状模型,将重建过程描述为摄像机姿态和线性形状参数的联合优化。论文的第一个贡献是应用Lasserre的凸平方和(SOS)松弛层次来解决形状重建问题,并证明了最小2阶的SOS松弛在经验上精确地解决了原非凸问题。论文的第二个贡献是利用目标函数中多项式的结构,找到SOS松弛的基单项式的约化集,该约化集在不影响精度的情况下显著减小了得到的半定程序(SDP)的大小。
这两个贡献导致了第一个可证明的三维形状重建最优解算器,我们称之为shape*。论文的第三个贡献是利用截断最小二乘(TLS)鲁棒代价函数和梯度非凸性求解TLS添加了一个离群拒绝层的shape*,无需初始化。结果是一个健壮的重建算法,命名为Shape#,它可以容忍大量的异常值测量。

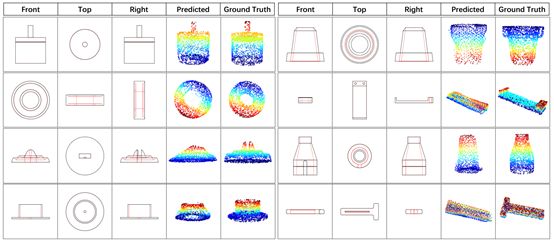
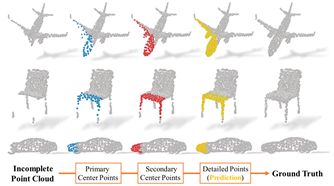
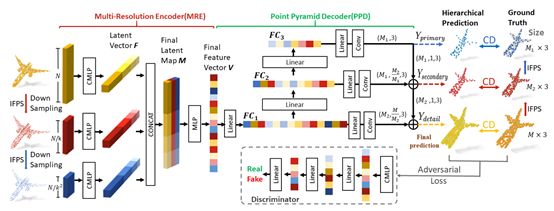
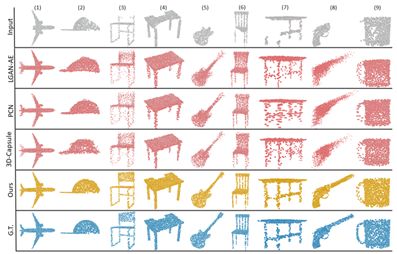
9.PFNet: Point Fractal Network for 3D Point Cloud Completion
论文链接:http://arxiv.org/abs/2003.00410v1
本文提出了一种新的基于学习的点云精确高保真完成方法——点分形网络(PFNet)。PFNet不同于现有的点云补全网络,它从不完整的点云中生成点云的整体形状,并且总是改变现有的点,遇到噪声和几何损失,它保留了不完整点云的空间布局,并能计算出缺失点云的详细几何结构预测中的区域。为了成功地完成这一任务,PF-Net利用基于特征点的多尺度生成网络,对缺失点云进行分层估计。此外,论文将多阶段完成损失和对抗性损失相加,生成更为真实的缺失区域。在预测中,对抗性损失可以更好地处理多种模式。实验证明了论文中的方法对于一些具有挑战性的点云补全任务的有效性。
10.PointAugment: An Auto-Augmentation Framework for Point CloudClassification
论文链接:http://arxiv.org/abs/2002.10876v2
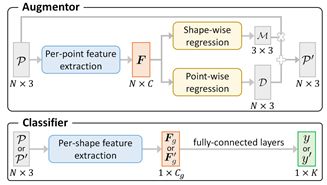
论文提出了一种新的自动增强框架PointAugment,它在训练分类网络时自动优化和增强点云样本,以丰富数据的多样性。与现有的二维图像自增强方法不同,PointAugment具有样本感知能力,采用对抗学习策略对增强器网络和分类器网络进行联合优化,使增强器能够学习生成最适合分类器的增强器样本。此外,本文还利用形状变换和点位移构造了一个可学习的点增广函数,并根据分类器的学习进度精心设计了采用增广样本的损失函数。大量的实验也证实了PointAugment的有效性和鲁棒性,以及提高各种网络在形状分类和检索方面的性能。

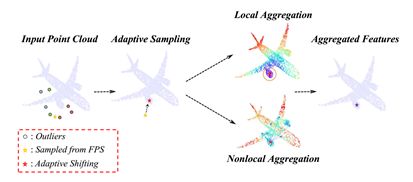
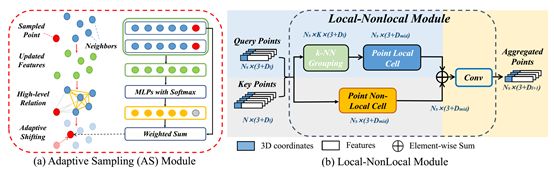
11.PointASNL: Robust Point Clouds Processing using Nonlocal NeuralNetworks with Adaptive Sampling
论文链接:https://arxiv.org/abs/2002.10876v2
代码链接:https://github.com/yanx27/PointASNL
原始点云数据通过三维传感器采集或重建算法,不可避免地会包含异常点或噪声。本文提出了一种新的端到端的点云处理网络PointASNL,它能有效地处理带有噪声的点云。该方法的关键部分是自适应采样(AS)模块。它首先从最远点采样(FPS)开始对初始采样点周围的邻域重新加权,然后自适应地调整整个点云之外的采样点。AS模块不仅有利于点云的特征学习,而且可以缓解异常点的偏倚效应。为了进一步捕获针对采样点的邻域依赖性和长距离依赖性,论文提出了一种基于非局部操作的局部非局部(L-NL)模型。这种L-NL模块使得学习过程对噪声不敏感。大量实验验证了该方法在点云处理任务中的稳健性和优越性,无论是合成数据、室内数据和有无噪声的室外数据。PointASNL在所有数据集上实现了分类和分割任务的最新鲁棒性能,并且在噪声情况下,在SemanticKITTI数据集上显著地优于以前的方法。
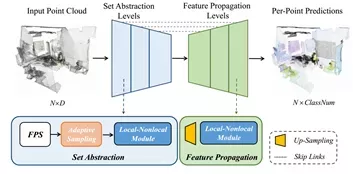
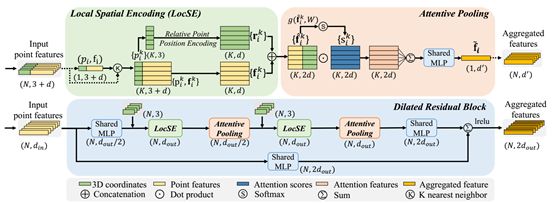
12.RandLANet: Efficient Semantic Segmentation of Large-Scale PointClouds
论文链接:http://arxiv.org/abs/1911.11236v2
本文研究了大规模三维点云的有效语义分割问题。依靠昂贵的采样技术或计算量大的前/后处理步骤,大多数现有方法只能在小尺度点云上进行训练和操作。本文介绍了一种高效、轻量级的神经网络结构RandLA-Net,用于直接推断大规模点云的逐点语义。论文方法的关键是使用随机点采样而不是更多复杂点选择方法。
尽管随机抽样具有显著的计算效率和存储效率,但它可能会偶然丢弃关键特征。为了克服这一缺点,论文引入了一种新的局部特征聚合模块来逐步增加每个3D点的接收场,从而有效地保留几何细节。大量实验表明,RandLA网络在一次传递中可以处理100万个点,比现有方法快200倍。此外, RandLA网络Semantic3D 和SemanticKITTI两个大规模基准上明显超过了最新的语义分割方法。