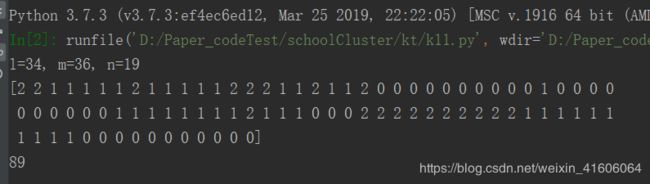
使用sklearn中的k-means方法就行聚类,并统计每个簇内样本点的数目
# 导入库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import MiniBatchKMeans, KMeans
x = np.array([[13378434.0829, 3526829.86612], [13378960.4042, 3526855.13451], [13372997.8308, 3526543.79201],
[13374160.2849, 3526499.56629],
[13375908.5746, 3526220.11996], [13374880.6989, 3526196.03995], [13374604.7169, 3527096.87862],
[13379547.6796, 3525986.68579],
[13374997.7791, 3524021.50132], [13374487.4915, 3526040.18441], [13377134.2636, 3524647.274],
[13374975.2792, 3524067.31441],
[13376013.5305, 3524566.02273], [13379191.518, 3526840.29867], [13380653.4589, 3525937.22248],
[13379185.9935, 3526996.18228],
[13374426.881, 3524227.71439], [13373246.4295, 3526561.59268], [13377963.1478, 3525580.05298],
[13374469.8778, 3526082.15448],
[13375251.7951, 3524902.72185], [13378458.073, 3523924.15117], [13382247.5439, 3529671.33493],
[13382041.2247, 3527903.34268],
[13380083.2029, 3528692.35517], [13380962.0043, 3528519.81002], [13379799.8328, 3528740.27736],
[13380743.9947, 3528862.75402],
[13380888.449, 3529724.53706], [13381768.4638, 3530180.20618], [13380283.8783, 3530417.55057],
[13379460.7078, 3529092.52867],
[13375514.1202, 3528071.73721], [13380595.5945, 3530292.25917], [13380750.4876, 3529651.32254],
[13380020.662, 3530023.70025],
[13382992.3395, 3529466.83067], [13380185.5946, 3529943.15481], [13381854.6163, 3529846.18257],
[13381526.4017, 3530218.27078],
[13379174.5312, 3529960.69999], [13381059.6294, 3528718.48633], [13382355.3521, 3529153.06305],
[13376067.8257, 3524653.68303], [13376785.7169, 3525281.54726], [13374648.6243, 3523594.54953],
[13374505.6438, 3524385.68232],
[13374704.6372, 3525093.75937], [13375979.3623, 3525089.48732], [13373386.2021, 3525459.09954],
[13376068.2445, 3524653.68192],
[13378256.4344, 3527892.07034], [13374516.8695, 3527797.75433], [13373268.7718, 3525794.99404],
[13374733.503, 3527630.0296],
[13380626.4887, 3529676.59458], [13382565.6018, 3530091.82782], [13381572.2346, 3529338.43359],
[13379010.5618, 3526321.89087],
[13378858.6421, 3526091.82007], [13378430.4016, 3525571.12207], [13378744.2362, 3525445.31746],
[13378278.2184, 3526127.19582],
[13378213.6778, 3526458.71913], [13377726.0386, 3526473.46834], [13379334.6825, 3526319.49906],
[13379942.1047, 3525652.10691],
[13379447.9135, 3526619.89596], [13375048.4629, 3524743.80287], [13374890.1955, 3524628.85715],
[13374903.646, 3525304.60377],
[13374661.6781, 3524712.01646], [13375057.442, 3525660.41439], [13374502.5452, 3525552.54492],
[13376082.0145, 3524429.07186],
[13375740.2411, 3525151.68925], [13375724.1394, 3524172.62747], [13375485.9677, 3524078.1459],
[13381928.9905, 3528752.84811], [13380739.2727, 3529288.85126], [13383135.3435, 3530223.4974],
[13383131.8223, 3529049.10112], [13382549.9076, 3528910.15209], [13381574.0822, 3528326.55367],
[13380507.399, 3528553.56851], [13382956.2103, 3529157.62372],
[13381909.7132, 3529359.24497], [13380893.5603, 3529326.64155], [13382520.1272, 3530424.96703],
])
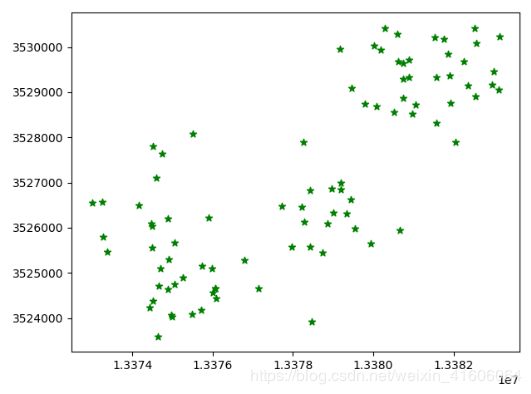
plt.scatter(x[:, 0], x[:, 1], c='g', marker='*')
plt.show()
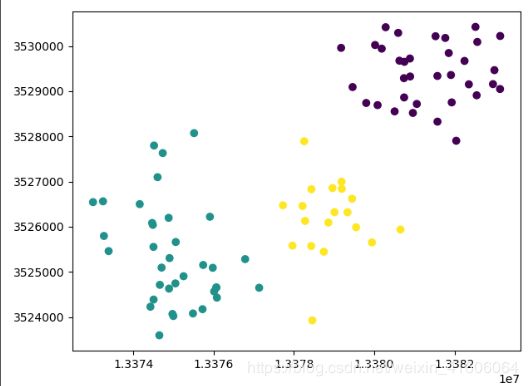
k = 3
y_pred = MiniBatchKMeans(n_clusters=k, batch_size=89, random_state=9).fit_predict(x)
l = 0
m = 0
n = 0
for i in range(0, len(y_pred)):
if y_pred[i] == 0:
l += 1
elif y_pred[i] == 1:
m += 1
elif y_pred[i] == 2:
n += 1
print('l=%d, m=%d, n=%d' % (l, m, n))
print(y_pred)
print(len(y_pred))
样本数据的散点图:
经过k-means聚类后的效果图:
统计每个簇内的样本点的数目: