8万条《网易云音乐》歌曲数据爬取
目标:《网易云音乐》歌曲数据爬虫,爬取歌单下的列表页和详情页歌曲数据,总数近8万条,另外当爬虫涉及字段和数据信息较多的情况下,数据结构如何构建问题

本文内容分两部分爬虫网站分析和源码解读两部分
一:爬虫分析
1、语种分类数据接口如何查找?
找接口以真正的response返回的数据为准,我们抓包找到playlist,发现其response中有我们想要的分类数据,并查看其真实的headers,可以找到真正的url接口,注意url要以headers中的为准,地址栏中的往往会设置一些反爬手段,故不要以地址栏为准

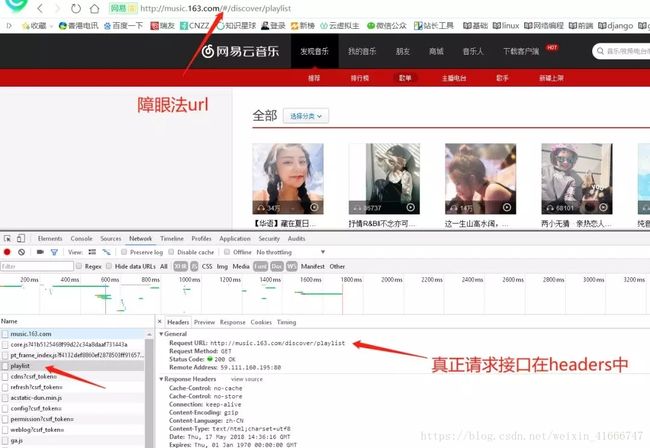
2、每个语种分类下的数据列表页接口如何查找?
我们请求以下语种分类,抓包分析,看到箭头所指这个包就是列表页请求的接口,其实无非也就是后面请求的cat参数进行了加密,我们需要找到响应中对应的参数

当然找这个参数,我们肯定首先想到的就是playlist这个包返回的数据,通过查看,发现确实在response中存在cat后面的参数,并且是我们要的正确参数,存在于href中
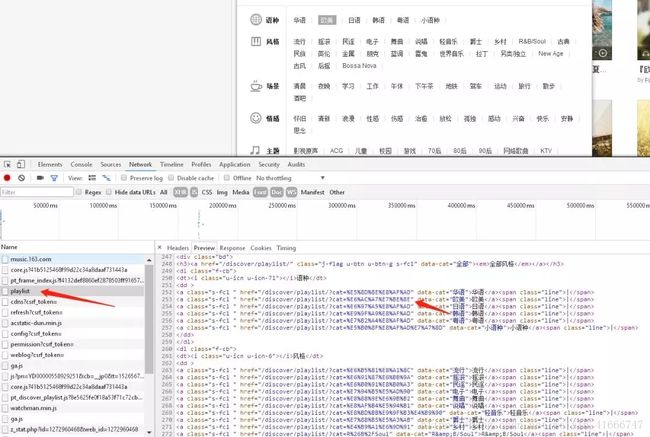
那么我们如何得到真实的
http://music.163.com/discover/playlist/?cat=%E5%8D%8E%E8%AF%AD
这样的请求接口呢?
答案就是拼接,获取该接口,在程序中有该拼接步骤,构造列表页请求url

3、当前列表页接口找到了,那么问题又来了,如何把所有页码的接口都找到呢?
找的方法和上面的类似,在response中有下一页地址的参数,我们也是需要进行拼接成真实的请求url,代码中实现也已经注明
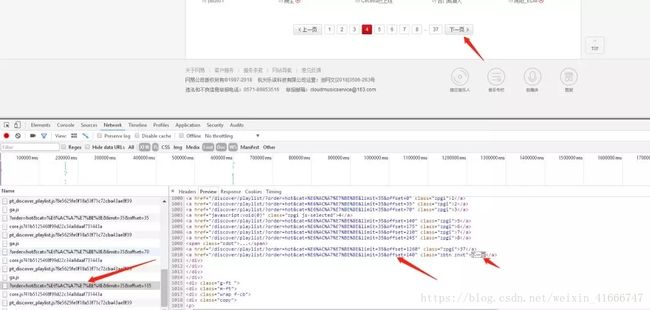

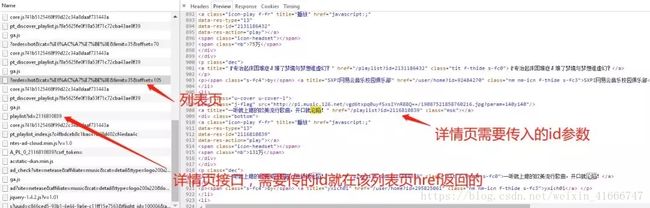
4、最后是不是该详情页了
同样,详情页需要传入的id参数,也是在列表页返回的,所以我们需要获取该数据也与上面类似一样,作拼接

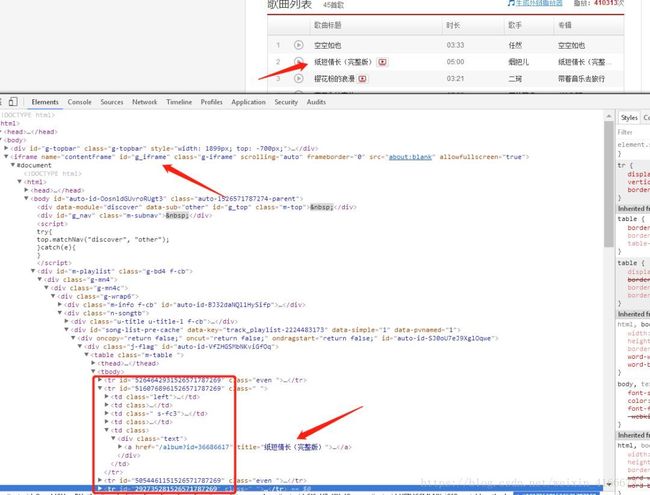
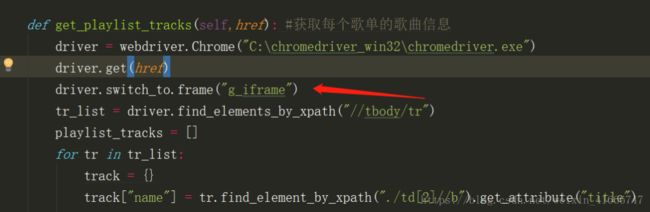
当然,顺便提下,详情页中我多提取了这些歌单列表数据,这些数据在iframe中,所以代码中用到了我iframe转换,swith_to,根据id或者name来找frame,这一步用selenium做很慢,为什么用selenium做,因为当前页没有返回时长、歌手等信息,其详情页也没有返回,所以就用selenium做了

二、源码解读
5、请求url和headers

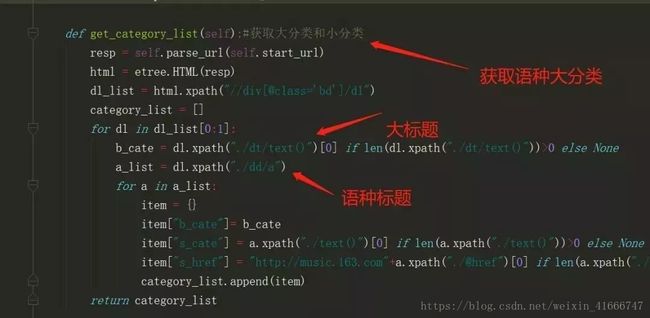
6、获取语种分类列表
语种数据提取
构造列表页url地址,需拼接
7、获取每个语种的歌曲列表数据
列表页数据提取
构造详情页请求url,需拼接
构造next_url下一页地址,需拼接

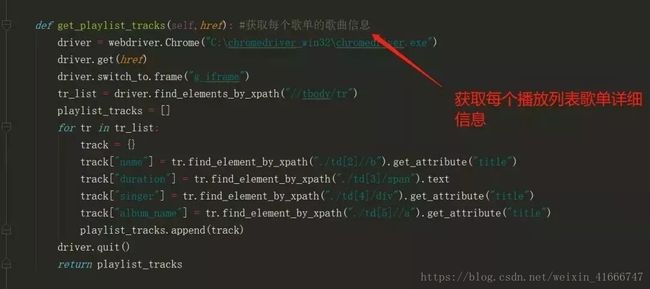
8、详情页歌曲播放信息
详情页数据提取

9、详情页歌曲列表播放信息
当前页面没有返回时长、歌手信息,发现是在iframe中,相当于是另外的页面,所有,用selenium来爬取,比较慢,属于掌握iframe这个知识点多做的一个步骤
10、最终数据大概就是这种样子

经验有限,不足之处欢迎指正