pytorch实战(三)CIFAR-10、DenseNet
1.DenseNet介绍
文章链接:https://arxiv.org/pdf/1608.06993.pdf
参考链接:https://cloud.tencent.com/developer/article/1451521
1)ResNet用了加法来做shortcut,这会阻碍信息传播,所以DenseNet用了concat;
2)直接concat会导致输入数据channel爆炸,所以做了bottleneck;
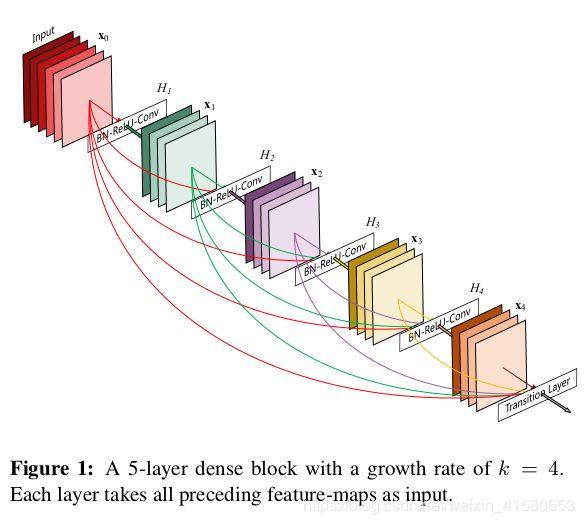
2.DenseNet实现(pytorch官方版本)
实现DenseNet主要需要实现以下几个功能:
1)DenseLayer
实现non-linear transformation和concat
# BN+Relu ——> 1x1conv降维channel ——> BN+Relu ——> 3X3conv特征提取
class _DenseLayer(nn.Sequential):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features))
self.add_module("relu1", nn.ReLU(inplace=True))
self.add_module("conv1", nn.Conv2d(num_input_features, growth_rate*bn_size, kernel_size=1, stride=1, bias=False))
self.add_module("norm2", nn.BatchNorm2d(growth_rate*bn_size))
self.add_module("relu2", nn.ReLU(inplace=True))
self.add_module("conv2", nn.Conv2d(growth_rate*bn_size, growth_rate, kernel_size=3, stride=1, padding=1, bias=False))
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)注:
1.整个layer中featuremap采用padding = 1, kernel_size = 3,保证featuremap的维度不变(nxn);
2.两个conv层有可训练参数;
3. BN+Relu ——> 1x1conv降维channel ——> BN+Relu ——> 3X3conv特征提取,实现bottle-neck结构;
4. 最后通过return实现concat.
2)DenseBlock
根据参数按照逻辑顺序组合DenseLayer生成DenseBlock
class _DenseBlock(nn.Sequential):
"""DenseBlock"""
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,
drop_rate)
self.add_module("denselayer%d" % (i+1,), layer)相对于ResNet中的:
# 这句相当于 non-linear transform
out = self.left(x)
# 这句相当于concat
out += self.shortcut(x)DenseBlock的实现主要就是这个concat规则:
# 遍历num_layers,创建“层”
for i in range(num_layers):
# i=0,输入为k0,输出为k
# i=1,输入为k0+k,输出为k
# i=2,输入为k0+2k,输出为k
# i=3,输入为k0+3k,输出为k
# ...
layer = _DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size, drop_rate)对于一个DenseBlock,只要最初输入的channel确定了(num_input_features),因为每个DenseLayer输出channel都是growth_rate,所以可以递归地计算出每个DenseLayer的输入channel(num_input_features+i*growth_rate)
最后一个DenseLayer输出channel为k0+(l-1)k
3)transition

# 这个模块主要实现 channel 与 featuremap两个方向上的降维,channel数通过 1x1 conv 进行改变,featuremap通过pooling改变。
class _Transition(nn.Sequential):
"""Transition layer between two adjacent DenseBlock"""
def __init__(self, num_input_feature, num_output_features):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_feature))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(num_input_feature, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module("pool", nn.AvgPool2d(2, stride=2))注:
1. BN+Relu ——> 1x1conv降维channel ——> AvgPool降低featuremap维度(n/2xn/2);
2.transiton的输入要根据DenseBlock的输出确定,即为k0+(l-1)k;
3.有一个可学习的1x1conv层.
4)DenseNet
1.开头一个conv层提取特征;
2.接下来按照 block_config=(6, 12, 24, 16) 创建DenseBlock;
3.最后展开成向量全连接层分类.
5)代码及测试:
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import OrderedDict
# step1:实现non-linear transformation:bn-relu-conv1x1-bn-relu-conv3x3
# feature维度变化: l*K->bn_size*k->k
# 传入参数有: num_input_features 输入特征数channel
# growth_rate 输出特征数channel
# bn_size bottleneck结构需要先把k*l个通道变成4k个通道,用1x1conv变成k个通道,整体看来是一个降维过程
# drop_rate 进行drop_out时的比例
class _DenseLayer(nn.Sequential):# 继承Sequential类
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
# bn+relu这里和之前的网络先卷积再bn、relu的顺序不同
self.add_module("norm1", nn.BatchNorm2d(num_input_features))
self.add_module("relu1", nn.ReLU(inplace=True))
# 1x1conv降维到4k
self.add_module("conv1", nn.Conv2d(num_input_features, growth_rate*bn_size, kernel_size=1, stride=1, bias=False))
# bn+relu
self.add_module("norm2", nn.BatchNorm2d(growth_rate*bn_size))
self.add_module("relu2", nn.ReLU(inplace=True))
# 3x3conv提取特征
self.add_module("conv2", nn.Conv2d(growth_rate*bn_size, growth_rate, kernel_size=3, stride=1, bias=False))
# 用于drop_out
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
# 输出为输入channel加上k,作为transition的输入
return torch.cat([x, new_features], 1)
# step2:实现连接两个DenseBlock的_Transition
# 输入参数有:num_input_feature 上一个DenseBlock的输出,(l-1)*k+k0
# num_output_features 下一个DenseBlock的输入
class _Transition(nn.Sequential):#继承Sequential类
"""Transition layer between two adjacent DenseBlock"""
def __init__(self, num_input_feature, num_output_features):
super(_Transition, self).__init__()
# bn+relu
self.add_module("norm", nn.BatchNorm2d(num_input_feature))
self.add_module("relu", nn.ReLU(inplace=True))
# 两个方向的降维度:channel降为num_output_features设定值
# featuremap降为一半AvgPool2d
self.add_module("conv", nn.Conv2d(num_input_feature, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module("pool", nn.AvgPool2d(2, stride=2))
# step3:根据non-linear transformation创建_DenseBlock
# 输入参数有:num_layers DenseBlock里有多少个提取特征的“层”
# 接下来这几个参数都是non-linear transformation需要的
# num_input_features k0+k(l-1)
# bn_size 默认为4
# growth_rate k
# drop_rate
class _DenseBlock(nn.Sequential):# 继承Sequential类
"""DenseBlock"""
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
# 遍历num_layers,创建“层”
for i in range(num_layers):
# i=0,输入为k0,输出为k
# i=1,输入为k0+k,输出为k
# i=2,输入为k0+2k,输出为k
# i=3,输入为k0+3k,输出为k
# ...
layer = _DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size, drop_rate)
# 把“层”添加到序列模型中
self.add_module("denselayer%d" % (i+1,), layer)
# step4:根据DenseBlock和transition创建DenseNet
# 输入参数有:growth_rate 每个denseblock输出维度k
# block_config 存放每个denseblock中有多少"层"(num_layers)
# num_init_features 初始卷积层输出channel数
# 其余参数上边有说明
class DenseNet(nn.Module):
"DenseNet-BC model"
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64,
bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=1000):
"""
:param growth_rate: (int) number of filters used in DenseLayer, `k` in the paper
:param block_config: (list of 4 ints) number of layers in each DenseBlock
:param num_init_features: (int) number of filters in the first Conv2d
:param bn_size: (int) the factor using in the bottleneck layer
:param compression_rate: (float) the compression rate used in Transition Layer
:param drop_rate: (float) the drop rate after each DenseLayer
:param num_classes: (int) number of classes for classification
"""
super(DenseNet, self).__init__()
# 初始卷积层,这个是独立于DenseBlock的
# 7X7conv -> BN+Relu -> maxpool
# 输出channel为num_init_features,featuremap需要计算((n+2p-f)/s+1)
self.features = nn.Sequential(OrderedDict([
("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(3, stride=2, padding=1))
]))
# 根据block_config中的数据创建DenseBlock
# 例如这里会创建四个DenseBlock,以第一个为例
num_features = num_init_features
for i, num_layers in enumerate(block_config):
# num_layers为6,会创建6个“层”每层输入都是之前层输出的concat
#i=0,输入为num_features,输出为k
#i=1,输入为num_features+k,输出为k
#i=2,输入为num_features+2k,输出为k
#i=3,输入为num_features+3k,输出为k
#...
block = _DenseBlock(num_layers, num_features, bn_size, growth_rate, drop_rate)
# 把创建好的_DenseBlock接到最开始创建的序列模型后边
self.features.add_module("denseblock%d" % (i + 1), block)
# 更新num_features为6k,作为接下来的transition的输入
num_features += num_layers*growth_rate
# 如果不是最后一个DenseBlock,就需要创建transition连接
if i != len(block_config) - 1:
transition = _Transition(num_features, int(num_features*compression_rate))
self.features.add_module("transition%d" % (i + 1), transition)
# 更新num_features
num_features = int(num_features * compression_rate)
# 最后的BN+Relu
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
self.features.add_module("relu5", nn.ReLU(inplace=True))
# 分类器
self.classifier = nn.Linear(num_features, num_classes)
# 参数初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
# 从输入图片传到通过所有DenseBlock
features = self.features(x)
# 最后还进行了一次avg_pool2d,并展开为vector
out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1)
# 分类
out = self.classifier(out)
return out
# 生成一个densenet,所有可选参数
# growth_rate=32 每个DenseBlock输出channel,有推荐值
# block_config=(6, 12, 24, 16) DenseBlock数量以及每个DenseBlock中层数
# num_init_features=64,
# bn_size=4
# compression_rate=0.5
# drop_rate=0
# num_classes=1000
# 121 = 1 + 2*(6+12+24+16) + 3 + 1
# 开头一个卷积,每个DenseBlock里有两个卷积,每个transiton中一个卷积,最后一个分类器
densenet121 = DenseNet(32, (6, 12, 24, 16), 64)
print(densenet121)经过100个epoch训练,训练准确率达到98.80%,验证准确率达到96.48%,测试准确率为90.23%,不知道为什么已经把drop_out调到0.5了,也用了weight_decay,过拟合还会这么严重。
3.总结
1)DenseNet121参数比ResNet18多了不少,拟合能力增强,但是对于CIFAR10来说似乎不需要再加强拟合能力了,主要问题是过拟合;
2)由于参数多,网络层数多,所以训练速度慢,一个epoch要花2分钟;
3)理解网络结构设计的规则,例如本网络中DenseLayer间输入输出间的递归关系、DenseBlock与transition间连接关系,通过逻辑语句批量创建这些”层“。