Python3爬虫(1)--urllib请求库的基本方法、高级方法、异常处理
环境:python3
目录
一、urllib库基本使用
1.1、url库他是python内置的HTTP请求库,他主要包含4个模块
1.2、第一个简单的get请求
1.3、如何判断是get请求和post请求
1.4、post请求表单的提交
1.5、隐藏、请求超时、延时提交
二、urllib库高级应用
2.1、Handler和Opener简介
2.2、urllib库免费代理ip的使用
2.3、urllib库Cookies 的处理
三、urllib库异常处理
一、urllib库基本使用
语法:urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
注意:data参数,当给这个参数赋值时,HTTP的请求就使用POST方法,如果data=None或者不写,则使用get方法。
1.1、url库他是python内置的HTTP请求库,他主要包含4个模块
- request: 最基本的HTTP请求模块,可以用来模拟发送请求。只需要传入URL和额外参数,就可以模拟实现这个过程
-
import urllib.request url="https://me.csdn.net/column/weixin_41685388" response = urllib.request.urlopen(url) print(response.read().decode('utf-8')) # read()获取响应体的内容,内容是bytes字节流,需要转换成字符串 - error:异常处理模块。
- parse:一个工具模块提供了很多URL的处理方法,如:拆分、解析、合并、格式转换等。
- robotparser:主要用于识别网站的robots.txt文件,判断哪些链接可以爬。很少使用
1.2、第一个简单的get请求
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
url="https://me.csdn.net/column/weixin_41685388"
response = urllib.request.urlopen(url)
print(type(response)) #输出:
# 一个HTTPResponse类型的对象,
# 主要包含read()、readinto()、getheader(name)、getheaders()、fileno()等方法,
# 以及msg、version、status、reason、debuglevel、closed等属性。
# 常用status属性得到返回结果的状态码
print(response.status) #返回200 表示正常请求
# getheaders()返回头部信息
print(response.getheaders())
# 返回头部信息中'Server'的值,服务器的搭建相关信息
print(response.getheader('Server'))
# 常用.read().decode('utf-8')返回网页内容,read()获取响应体的内容,内容是bytes字节流,需要转换成字符串
print(response.read().decode('utf-8')) #网页内容 1.3、如何判断是get请求和post请求
问题来了,如何判断是get请求和post请求,谷歌浏览器为例:打开网页-->右击,检查(N)-->Network-->F5刷新,找到我们需要的Name,Method的值一看就知道了,注意往往第一次使用的时候检查功能的时候默认没有打开Method,需手动勾选一下。
get请求,如:https://blog.csdn.net/weixin_41685388/category_9426224.html链接
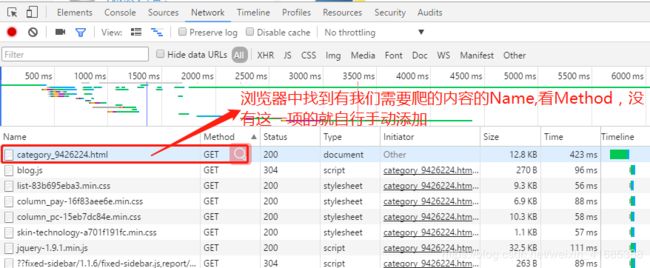
如何查看是否是我们需要的Name?
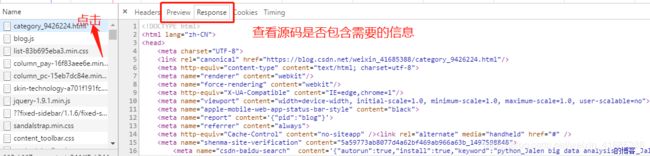
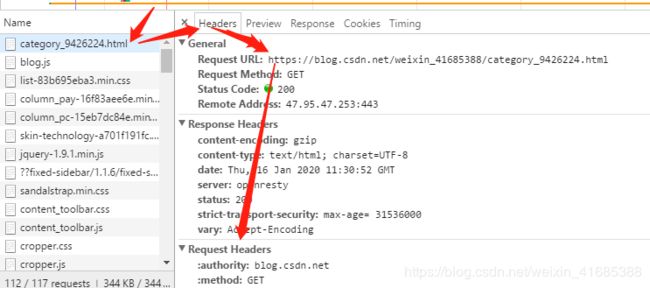
请求时需要的内容:
来一个post请求,看长啥样如:http://fanyi.youdao.com/
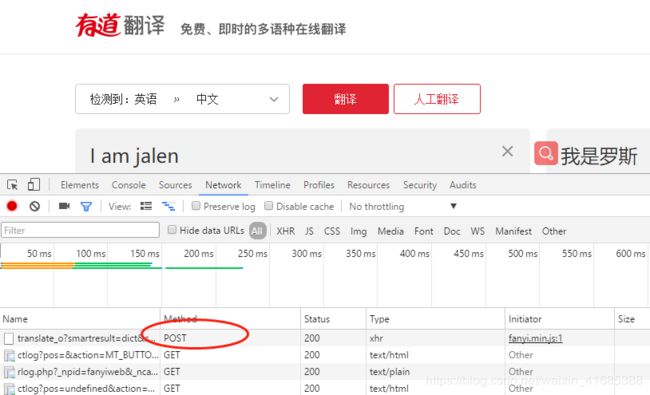
请求时需要的内容:具体看4中代码
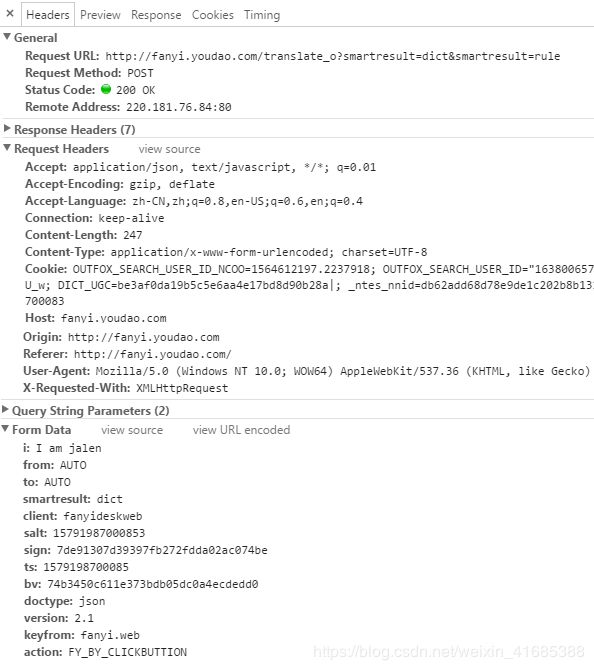
1.4、post请求表单的提交
在使用urllib.request.urlopen()函数有一个data参数,当给这个参数赋值时,HTTP的请求就使用POST方法,如果data=None或者不写,则HTTP的请求就使用get方法。data参数的格式必须符合application/x-www-form-urlencoded的格式。需要urllib.parse.urlencode()将字符串转化为这个格式。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import urllib.parse
import json
import time
def youdao(input):
#url=r"http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
# 调试后发现设置了反爬机制,需要将“_o”删除即可。
url=r"http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
#用于隐藏身份,Headers必须是字典,在网页检查的Request Headers中,常调用Cookie和User-Agent,
# 使用urllib.request.Request()才能调用该功能。
Headers = { }
Headers["Cookie"]=r'OUTFOX_SEARCH_USER_ID_NCOO=1564612197.2237918; OUTFOX_SEARCH_USER_ID="[email protected]"; _ga=GA1.2.269278628.1571982437; _ntes_nnid=db62add68d78e9de1c202b8b131b32a4,1579175684866; JSESSIONID=aaaGcKLB2j8UhdX6Q3V_w; SESSION_FROM_COOKIE=unknown; ___rl__test__cookies=1579203741289'
Headers["User-Agent"]=r"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36"
data = { } #post请求需要的data参数,在网页检查的Form Data中,
#data["i"]="I am jalen" #认真一点你会发现这就是我们输入的值,自己做一个简单的有道翻译只需要修改这里就可以实现
data["i"] = input #那就按照习惯在函数外单独输入经常变化的值
data["from"]="AUTO"
data["to"]="AUTO"
data["smartresult"]="dict"
data["client"]="fanyideskweb"
data["salt"]="15792037412906"
data["sign"]="324404ee89ccb63c2ea1efb7d311db26"
data["ts"]="1579203741290"
data["bv"]="74b3450c611e373bdb05dc0a4ecdedd0"
data["doctype"]="json"
data["version"]="2.1"
data["keyfrom"]="fanyi.web"
data["action"]="FY_BY_CLICKBUTTION"
data = urllib.parse.urlencode(data).encode("utf-8") #post请求的data参数格式转化
req = urllib.request.Request(url,data,Headers)
response = urllib.request.urlopen(req,timeout=30)
html = response.read().decode("utf-8") #返回网页内容
# print(type(html),html) #后面就可以解析了,解析部分在后面的文章中有单独讲解,但这里还是继续写完本例
target = json.loads(html) #json解析后面的文章会单独讲解
print("翻译结果:%s" % (target['translateResult'][0][0]['tgt']))
# 翻译结果:我是罗斯
if __name__ == '__main__':
input = "I am jalen"
time.sleep(5) #延时提交
youdao(input)1.5、隐藏、请求超时、延时提交
在4中得代码中已经有体现了,简单的回顾一下:
(1)隐藏:隐藏身份,Headers必须是字典,在网页检查的Request Headers中,常调用和修改Cookie和User-Agent,使用urllib.request.Request()才能调用该功能。如:req = urllib.request.Request(url,data,Headers)
(2)请求超时:在设定的时间范围内如果网页没有成功请求,则返回错误如:response = urllib.request.urlopen(req,timeout=0.3)
(3)延时提交:time.sleep(n) ,n表示秒数
二、urllib库高级应用
2.1、Handler和Opener简介
Handler类,可以把他理解为各种处理器,有处理登录验证的,有处理cookies的,有处理代理设置的等。
urllib.request模块里的 BaseHandler 类,是Handler 的父类 。它提供了如 default_open ()、 protocol_request ()等方法。
各种Handler子类继承这个BaseHandler类。如:
- HTTPDefaultErrorHandler: 用于处理HTTPError类型的异常。
- HTTPRedirectHandler:用于处理重定向。
- HTTPCookiesProcessor:用于处理cookies。
- ProxyHandler:用于设置代理,默认代理为空。
- HTTPpasswordMgr:用于管理密码,它维护了用户名和密码的表。
- HTTPBasicAuthHandler:用于管理认证,如果一个了解打开时需要认证,那么可以用它来解决认证问题。
- 其他,查看参考文档:https://docs.python.org/3/library/urllib.request.html#urllib.request.BaseHandler.
Opener类, 也就是OpenerDirector类 。 urlopen()这个方法,就是urllib提供的一个Opener 。Request 和 urlopen( )相当于类库已经封装好了常用来做get或post请求的方法,利用它们可以完成基本的请求。实现更高级的功能时,需要深入一层进行个性化配置,使用更底层的实例来完成操作,就用到了 Opener 。 通常利用 Handler 来构建 Opener 。Opener 可以使用 open ()方法,返回的类型和 urlopen ()一样。
案例说明:
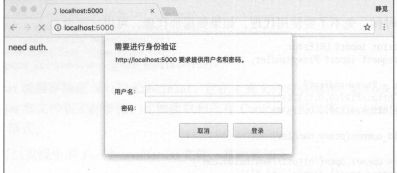
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from urllib.request import HTTPPasswordMgrWithDefaultRealm, HTTPBasicAuthHandler, build_opener
from urllib.error import URLError
username = 'username'
password = 'password'
url = 'http://localhost:5000/' #DB2默认端口号为:5000;
# 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码
p = HTTPPasswordMgrWithDefaultRealm()
# 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 Web服务器、用户名、密码
p.add_password(None, url, username, password)
# 3. 构建一个HTTP基础用户名/密码验证的HTTPBasicAuthHandler处理器对象,参数是创建的密码管理对象
auth_handler = HTTPBasicAuthHandler(p)
# 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler
opener = build_opener(auth_handler)
try:
result = opener.open(url)
html = result.read().decode("utf-8")
print(html)
except URLError as e:
print(e.reason)
'''
这里首先实例化 HTTPBasicAuthHandler 对象,其参数是 HTTPPasswordMgrWithDefaultRealm 对象,
它利用 add_password ()添加进去用户名和密码,这样就建立了一个处理验证的 Handler.
接下来,利用这个Handler 并使用 build_opener ()方法构建一个 Opener ,这个 Opener 在发送请求
时就相当于已经验证成功了 。
接下来,利用 Opener 的 open ()方法打开链接,就可以完成验证了 。 这里获取到的结果就是验证
'''2.2、urllib库免费代理ip的使用
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
proxy_handler = ProxyHandler({'http':'http://139.108.123.4:3128','https':'https://157.245.54.87:8080'})
opener = build_opener(proxy_handler)
try:
response = opener.open('https://www.baidu.com')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)2.3、urllib库Cookies 的处理
(1)获取Cookies
#网站的 Cookies 获取 import http.cookiejar, urllib.request cookie = http.cookiejar.CookieJar() handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open ('http://www.baidu.com') for item in cookie: print(item.name +'= '+ item.value) ''' 输出: BAIDUID= C8BD9A03380D17E0F44167FD4DCE452E:FG=1 BIDUPSID= C8BD9A03380D17E01BB36C142C466E1D H_PS_PSSID= 1431_21118_30495_26350_30481 PSTM= 157****043 delPer= 0 BDSVRTM= 0 BD_HOME= 0 '''#Cookies 实际上也是以文本形式保存 import http.cookiejar, urllib.request filename = 'cookies.txt' cookie = http.cookiejar.MozillaCookieJar(filename) handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open("http://www.baidu.com") cookie.save(ignore_discard=True, ignore_expires=True)
#保存成 libwww-perl(LWP)格式的 Cookies 文件 import http.cookiejar, urllib.request filename = 'cookies.txt' cookie = http. cookiejar. LWPCookieJar (filename) handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open("http://www.baidu.com") cookie.save(ignore_discard=True, ignore_expires=True)
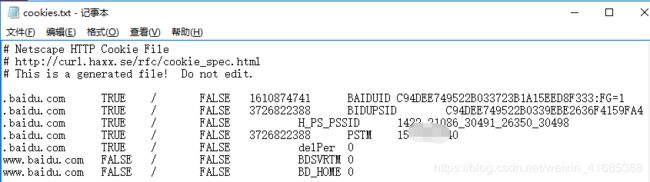
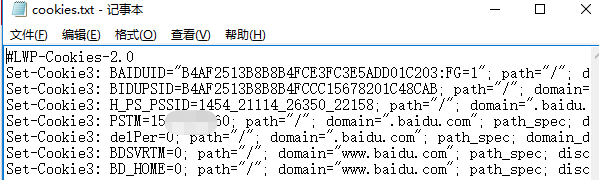
(2)使用cookie
#利用cookie
import http.cookiejar, urllib.request
cookie = http.cookiejar.LWPCookieJar( ) #LWPCookie格式
# cookie = http.cookiejar.MozillaCookieJar( ) #MozillaCookie格式
cookie.load(r'cookies.txt',ignore_discard=True,ignore_expires=True)
handler=urllib.request.HTTPCookieProcessor(cookie)
opener=urllib.request.build_opener(handler)
response=opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))三、urllib库异常处理
urllib的error模块定义了由request模块产生的异常。如果出现了问题,request模块便会抛出error模块中定义的异常。
#基本用法:
from urllib import request, error
from urllib.error import HTTPError ,URLError
try:
"代码块"
except error.URLError as e:
print(e.reason,e.code,e.headers,sep='\n')
except (HTTPError, URLError, socket.timeout, AttributeError,UnicodeEncodeError) as e1:
return
else:
print("Request Successfully")我们打开一个不存在的页面,照理来说应该会报错,但是这时我们捕获了URLError这个异常,运行结果程序没有直接报错,而是输出了指定输出的内容并跳过执行下一条。在很多请求链接的时候避免程序异常终止,同时异常得到了有效处理,通常我们会记录下异常的url,异常原因,单独将结果保存,然后先跳过继续下面的爬去,最后再进一步处理异常值(不同的异常采取不同的处理方法)。
常见异常:URLError, HTTPError, socket.timeout 等
- 属性reason:返回错误的原因。
- code:返回HTTP状态码,比如404表示网页不存在,500表示服务器内部错。
- headers:返回请求头。