Python3入门与进阶_知识点系统归纳
目录
- 1 介绍
- 1.2 用途
- 1.3 特点
- 2 基础
- 2.1 基本数据类型
- 2.1.1 Number
- 2.1.2 String
- 2.1.3 List
- 2.1.4 Tuple
- 2.1.5 Set
- 2.1.6 Dictionary
- 2.1.7 数据类型转换
- 2.2 运算符
- 2.2.1 成员运算符
- 2.2.2 算术运算符
- 2.2.3 赋值运算符
- 2.2.4 逻辑运算符
- 2.2.5 身份运算符
- 2.3 语句
- 2.3.1 条件控制
- 2.3.2 while循环
- 2.3.3 for循环
- 2.4 模块
- 2.4.1 项目结构
- 2.4.2 模块导入
- 2.5 函数
- 2.5.1 函数定义
- 2.5.2 函数参数
- 2.5.3 内置函数
- 2.6 其他
- 3 高级
- 3.1 面向对象
- 3.1.1 类
- 3.1.2 变量
- 3.1.3 方法
- ① 类方法
- ② 实例方法
- ③ 静态方法
- 3.1.4 构造函数
- 3.1.5 成员私有
- 3.1.6 内建属性
- 3.1.7 继承
- 3.1.8 枚举类
- 3.2 正则表达式
- 3.2.1 正则函数
- ① 匹配 findall
- ② 替换 sub
- ③ 匹配 match/search
- 3.2.2 正则实例
- 3.2.3 正则模式
- 3.2.4 正则数量词
- 3.3 JSON
- 3.3.1 JSON函数
- 3.3.2 JSON与Python类型的对照
- 3.4 函数式编程
- 3.4.1 闭包
- ① global/nonlocal
- 3.4.2 匿名函数
- 3.4.3 高阶函数
- ① 映射 map
- ② 累积 reduce
- ③ 过滤 filter
- 3.5 装饰器
- 4 实战爬虫总结
- 5 Pythonic
- ① 字典取代switch
- ② 列表推导式
1 介绍
1.2 用途
爬虫、大数据与数据分析(Spark)、自动化运维与测试、web开发(Flask、Django)、机器学习(Tensor Flow)、胶水语言。
1.3 特点
面向对象、丰富的第三方库、跨平台、解释型语言。
python一切皆对象
2 基础
2.1 基本数据类型
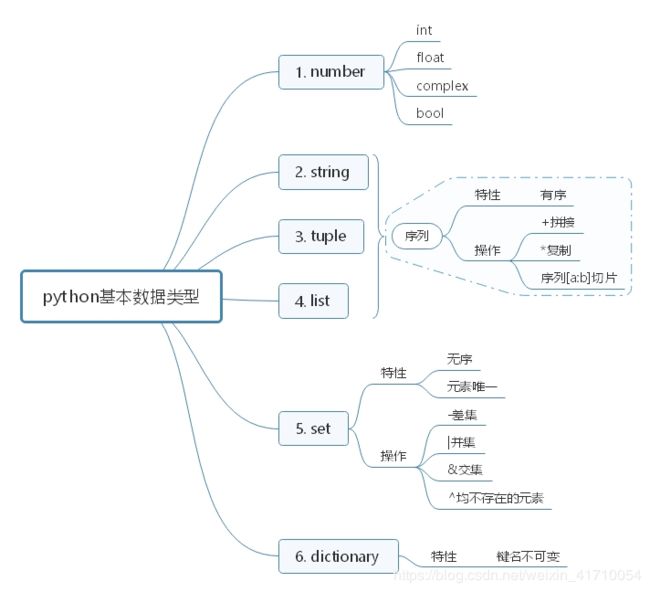
值类型,不可变:Number、String、Tuple;
引用类型,可变:List、Dictionary、Set。
注意元组内嵌套的列表可改变
2.1.1 Number
int、float、bool、complex
注意:Python没有short、long、double类型。
数值运算
- 在加减乘计算时,Python会把整型转换成为浮点数。
- 除法中,
/返回浮点数,//返回整数(只保留整数部分)。
进制
二进制0b开头,八进制0o开头,十六进制0x开头
2.1.2 String
① 特性
如果不想让\发生转义,可以在字符串前面添加一个 r或R
② 操作序列
序列:String、List、Tuple
| 操作 | 功能 | 备注 |
|---|---|---|
序列1+序列2 |
拼接 | |
序列*n |
复制n次 | |
序列[下标a:下标b] |
截取序列的[a,b) | 从左往右以0开始,反之以-1开始 |
序列[i] |
访问 |
2.1.3 List
① 格式
[元素1,元素2...]
2.1.4 Tuple
① 格式
(元素1,元素2...)
② 元组和列表的区别
元组的元素不能修改,列表的元素可以修改。
注意:当元组内只有一个元素时,其类型单个元素对应的类型。如(1)为int,(‘asd’)为str。而当列表内只有一个元素时,仍然是list类型。
2.1.5 Set
① 格式
{元素1,元素2...}或set('元素1元素2元素3...')
② 特性
集合是无序的,且元素不重复。
注意:创建空集合必须用 set()而不是 { },因为 { } 是用来创建一个空字典。
③ 操作集合
| 运算符 | 功能 |
|---|---|
- |
差集 |
\| |
并集 |
& |
与集 |
a ^ b |
a和b不同时存在的元素 |
2.1.6 Dictionary
① 格式
{'键1':'值1','键2':'值2'...}
② 特性
- 键名不可以重复;
- 键名为不可变,可以为number、string、tuple类型。
③ 操作字典
| 操作 | 功能 |
|---|---|
字典['键名'] |
访问字典中的某个元素值 |
字典和集合的区别
字典当中的元素是通过键来存取的,而集合通过偏移存取。
2.1.7 数据类型转换
| 函数 | 描述 |
|---|---|
int() |
转十进制 |
bin() |
转二进制 |
oct() |
转八进制 |
hex() |
转十六进制 |
ord() |
转ascii |
bool() |
转bool(非空、非0、非None,则为True) |
2.2 运算符
2.2.1 成员运算符
| 运算符 | 用法 | 功能 |
|---|---|---|
in |
元素 in 序列 |
检测序列中是否包含指定元素 |
not in |
元素 not in 序列 |
检测序列中是否不包含指定元素 |
注意:字典的成员运算符是针对键
2.2.2 算术运算符
+加、-减、*乘、/除、//取整除、%取余、**幂
2.2.3 赋值运算符
+=、-=、*=、/=、//=、%=、**=
注意:python中没有自增/自减运算符
2.2.4 逻辑运算符
and与、or或、 not非
2.2.5 身份运算符
| 运算符 | 用法 | 功能 |
|---|---|---|
is |
元素 is 序列 |
检测两个变量身份(内存地址)是否全等 |
not is |
元素 not is 序列 |
检测两个变量身份(内存地址)否不全等 |
注意:python中没有===运算符
2.3 语句
python中没有switch
2.3.1 条件控制
if 条件:
语句
elif 条件:
语句
else:
语句
pass空语句/占位语句
2.3.2 while循环
while 条件:
语句
else:
语句
说明:在条件语句为 false 时,执行 else 的语句块
2.3.3 for循环
# 第一种情况
for 元素 in 序列/集合/字典:
语句
else:
语句
# 第二种情况
for 变量 in range(范围):
语句
else:
语句
说明:在for语句遍历完毕时,执行 else 的语句块
range()的参数说明:
- range(x):从0遍历到x,默认偏移量为1
- range(x,y):从x遍历到y,默认偏移量为1
- range(x,y,z):从x遍历到y,偏移量为z。若x>y,则为递减,反之递增
2.4 模块
2.4.1 项目结构
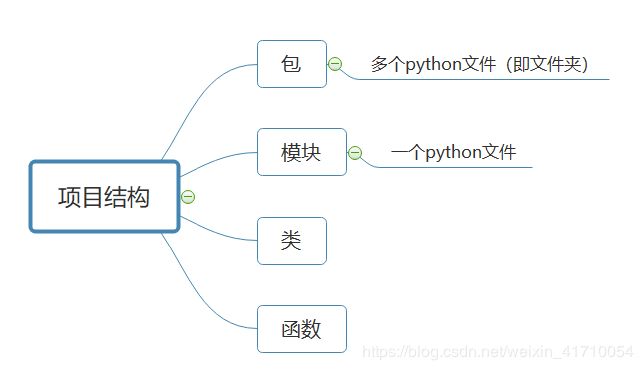
2.4.2 模块导入
| 语句 | 功能 |
|---|---|
import 模块 |
引入模块 |
from 包 import 模块/* |
引入指定/全部模块 |
from 模块 import 部分/* |
引入模块的指定/全部部分 |
分析:from后面写了什么,之后在用的时候都不用写了
说明:可以设置星号*所涵盖的内容,在被导入的文件中,设置__all__=['name1','name2'...]
2.5 函数
2.5.1 函数定义
def 函数名(参数列表):
...
return 返回值1,返回值2....
- 若没写return,则返回None
- 若return返回多个值,则返回类型为元组
- 推荐使用
变量1,变量2...=函数()的形式获取返回值(序列解包),不推荐使用元组[索引]获取,会降低代码可读性
2.5.2 函数参数
| 类型 | 格式 | 说明 |
|---|---|---|
| 必须参数 | 调用时函数(实参) |
|
| 关键字参数 | 调用时函数(形参=实参) |
形参和实参顺序可以不一致 |
| 默认参数 | 函数定义时def 函数名(形参=值) |
实参可覆盖默认参数 |
注意:默认参数需写在形参列表的最后
2.5.3 内置函数
| 函数 | 功能 |
|---|---|
len() |
返回元素个数 |
id() |
查看变量内存地址 |
type() |
类型判断 |
isinstance(变量名,(类型1,类型2..)) |
变量是否属于其中的一个类型 |
input(['提示语']) |
接收用户输入的信息,返回为 string 类型 |
round(数值,保留位数) |
四舍五入 |
字符串.index(子串,起始位置,结束位置) |
返回开始的索引值,没找到则抛出异常。 |
主串.replace('旧子串','新子串',匹配次数) |
替换 |
字典.get(键名, 默认值) |
返回指定键的值,如果不存在则返回默认值。 |
2.6 其他
None不是False、''、0、[],尤其在判空时需要注意- 对象存在不代表其一定为
True,对象的bool值由__bool__或__len__内置函数决定 - 使用
\或()可实现跨行书写
3 高级
3.1 面向对象
3.1.1 类
① 类定义
class 类名:
pass
② 类实例化
对象名=类名([实参]) # 形参写在类的构造函数中
3.1.2 变量
| 变量 | 访问 |
|---|---|
| 实例变量 | 通过self.变量名访问 |
| 类变量 | 通过cls.变量访问 |
说明:
- 如果在实例化对象中找不到变量,则会去相应的类中寻找,若也没有,则去所在类的父类中寻找…
- 在构造函数内,直接通过
变量名访问的是形参,而非实例对象。
3.1.3 方法
① 类方法
# 定义
@classmethod
def funcname(cls):
pass
# 调用
类.方法()
类方法与函数的区别:第一个参数必须是self,self 代表的是类的实例
② 实例方法
# 定义
def funcname(self):
pass
# 调用
实例.方法()
③ 静态方法
# 定义
@staticmethod
def funcname():
pass
# 调用
类.方法()或实例.方法()
3.1.4 构造函数
- 构造函数
__init__在实例化类时,将自动调用 - 构造函数是个实例方法
- 构造函数只能返回
None - 对象的参数由构造函数接收,构造函数的第一个参数为
self
3.1.5 成员私有
在变量或方法名前加
__,则变为私有
细节理解:在创建私有的实例变量时,实际python会把变量名改为_类名__变量名,所以在外部访问私有变量__变量名时,实际是创建了新变量_类名__变量名。但是通过_类名__变量名可以修改和访问!
建议:对类变量,建议不要直接修改,而是通过方法来修改,这样有利于保护变量
3.1.6 内建属性
| 内建属性 | 说明 |
|---|---|
__class__ |
表示实例所在的类 |
__dict__ |
查看类或实例的自定义属性 |
3.1.7 继承
# 子类的定义
class 子类(父类):
pass
- 建议:一个文件夹只写一个类,那么只需在子类文件上写
from 文件 import 父类 - 多继承:一个子类继承多个父类。python支持多继承
① 调用父类构造函数
方法一(理解即可,可跳过不看)
class 子类(父类):
# 子类构造函数的定义。(如果子类没有自己的实例变量,则可以不必写构造函数,会直接继承父类的实例变量)
def __init__(self[,子类及父类形参]): # 注意:这里包含了子类形参和父类形参
self.子类变量=值
父类.__init__(self[,父类形参]) # 注意:这里包含了父类的self及父类形参
- 细节理解:为什么在上述代码中,父类的构造函数调用需要写
self形参,但是实例化父类时,参数中却不需要写self? - 原因:实例化父类过程中,对于
self的指向,会由python帮我们自动完成。而上述代码,并没有实例化父类,python不会帮我们自动完成,而需要我们显式地写出self。* - 代码示例:比如下面的代码,第一种情况,进行了实例化类,则无需写
self,而第二种情况,是直接由类调用的,则需要显式写出实例human1(因为self指向的是实例)。其实第二种情况不一定非要human1,任意写一个其他实参也可以的,只是这时候get_name函数中的self参数没有不代表实例,而是一个普通的参数
class Human:
def get_name(self):
pass
human1 = Human() #实例化类
# 第一种情况
human1.get_name()
# 第二种情况
Human.get_name(human1)
方法二(推荐)
class 子类(父类):
def __init__(self[,子类及父类形参]):
self.子类成员变量=值
super(子类,self).__init__(父类形参)
② 父子方法同名问题
若父类和子类具有同名的实例方法,则在调用的是子类的。
如果想调用父类同名实例方法,需要在定义子类方法时,加上super(子类,self).方法()
3.1.8 枚举类
- 其标签值不可修改
- 其不允许相同标签
- 其标签不支持大于小于比较符
- 其若有多个标签是同值的,则后续的都看做第一个标签的别名。在遍历枚举类时,别名不会被打印出来
- 其不允许实例化
@unique装饰器,则不允许标签同值
from enum import Enum, unique
# 如果枚举类继承的是IntEnum,则标签值只允许为int类型
from enum import IntEnum
# @unique 加上这个,则不允许标签同值
class VIP(Enum):
Yellow = 1
Yellow_ALIAS = 1
# Yellow = 2 # 报错,枚举类不允许相同标签
Green = 2
Black = 3
class VIP1(Enum):
Yellow = 1
Yellow_ALIAS = 1
Green = 2
Black = 3
class Common:
Yellow = 1
Black = 3
Red = 4
print('-------枚举类型及值-------')
print(VIP.Yellow)
print(VIP['Yellow'])
print(VIP.Yellow.name)
print(type(VIP.Yellow))
print(type(VIP['Yellow']))
print(type(VIP.Yellow.name))
print('-------枚举类型与普通类对比-------')
print(VIP.Yellow.value)
print(Common.Yellow)
Common.Yellow = 2
# VIP.Yellow=2 # 报错,枚举类不可修改
# 遍历枚举类——Yellow_ALIAS不会被打印
print('-------for v in VIP-------')
for v in VIP:
print(v)
# Yellow_ALIAS会被打印
print('-------for v in VIP.__members__-------')
for v in VIP.__members__:
print(v)
print('-------for v in VIP.__members__.items()-------')
for v in VIP.__members__.items():
print(v)
print('-------成员变量的别名及比较运算符-------')
print(VIP.Yellow_ALIAS)
print(VIP.Yellow is VIP.Yellow_ALIAS)
print(VIP.Yellow == VIP.Yellow_ALIAS)
print(VIP.Yellow == VIP1.Yellow_ALIAS)
# print(VIP.Yellow# 输出结果
-------枚举类型及值-------
VIP.Yellow
VIP.Yellow
Yellow
-------枚举类型与普通类对比-------
1
1
-------for v in VIP-------
VIP.Yellow
VIP.Green
VIP.Black
-------for v in VIP.__members__-------
Yellow
Yellow_ALIAS
Green
Black
-------for v in VIP.__members__.items()-------
('Yellow', )
('Yellow_ALIAS', )
('Green', )
('Black', )
-------成员变量的别名及比较运算符-------
VIP.Yellow
True
True
False
-------枚举转换-------
VIP.Yellow
3.2 正则表达式
3.2.1 正则函数
| 函数 | 功能 |
|---|---|
.group() |
用来提取出分组截获的字符串 |
.span() |
返回匹配到的子串在主串中的位置 |
① 匹配 findall
格式:
re.findall(子串,主串[,模式|模式2...])
功能:匹配
返回:以列表形式,返回匹配到的子串
说明:模式中\|表示且
② 替换 sub
格式:
re.sub(原内容,新内容/函数,主串,替换次数)
功能:替换
返回:返回新的主串
说明:替换次数为0表全体换,为n表示替换n个
示例代码:(一)
import re
a = 'C#PythonC#'
# 处理函数:对sub的第一参数C#进行处理,value即C#
def convert(value):
print(value)
matched=value.group()
return '|'+matched+'|'
r=re.sub('C#',convert,a)
print(r)
# 输出结果
|C#|Python|C#|
示例代码:(二)
import re
a = 'A8C3721D86'
def convert(value):
matched = value.group()
if int(matched) >= 5:
return '9'
else:
return '0'
r = re.sub('\d', convert, a)
print(r) # A9C0900D99
③ 匹配 match/search
match
格式:
re.match(子串,主串)
功能:匹配(仅匹配一个)
说明:从首字符开始匹配
search
格式:
re.search(子串,主串)
功能:匹配(仅匹配一个)
match、search的比较示例代码:
import re
a = 'A8C3721D86'
r1 = re.match('\d', a)
print(r1)
r2 = re.search('\d', a)
print(r2)
# 输出结果
None
match、search、findall的比较示例代码:
import re
a = '8C3721D86'
r1 = re.match('\d', a)
print(r1)
r2 = re.search('\d', a)
print(r2)
r3 = re.findall('\d', a)
print(r3)
# 输出结果
['8', '3', '7', '2', '1', '8', '6']
search和findall,以及group和group的比较示例代码:
import re
a = 'life is short , i use python.i love python'
r1 = re.search('life(.*)python(.*)python', a)
print(r1)
print(r1.group(0)) # 全打印
print(r1.group(1)) # 打印第一个组
print(r1.group(2)) # 打印第二个组
print(r1.group(0, 1, 2)) # group可以连续打印
# groups等价于group(1,2,...,n)
print(r1.group(1, 2))
print(r1.groups())
print(type(r1.groups()))
# findall等价于groups,只不过返回的是列表
r2 = re.findall('life(.*)python(.*)python', a)
print(r2)
print(type(r2))
# 输出结果
life is short , i use python.i love python
is short , i use
.i love
('life is short , i use python.i love python', ' is short , i use ', '
.i love ')
(' is short , i use ', '.i love ')
(' is short , i use ', '.i love ')
[(' is short , i use ', '.i love ')]
3.2.2 正则实例
| 字符 | 含义 |
|---|---|
. |
除换行之外的所有字符 |
\d |
数字 |
\D |
非数字 |
\s |
空白字符 |
\S |
非空白字符 |
\w |
下划线、字母、数字 |
\W |
非下划线、字母、数字 |
| 字符 | 含义 |
|---|---|
[] |
或 |
() |
分组,且 |
[^] |
非 |
^ |
开头 |
$ |
结尾 |
[a-b] |
数字或字母范围 |
3.2.3 正则模式
| 字符 | 含义 |
|---|---|
re.I |
忽视大小写 |
re.S |
使 . 匹配包括换行在内的所有字符 |
3.2.4 正则数量词
| 字符 | 含义 |
|---|---|
{a,b} |
指定前一个字符的出现次数(贪婪) |
* |
前面的一个字符出现0到n次 |
+ |
前面的一个字符出现1到n次 |
? |
前面的一个字符出现0到1次 |
贪婪:按照数值大的配匹。反之,则为非贪婪,写为{a,b}?
import re
a='pythonn python pytho pyth pyt py'
r1=re.findall('python{0,2}',a) # ['pythonn', 'python', 'pytho']
r2=re.findall('python*',a) # ['pythonn', 'python', 'pytho']
r3=re.findall('python+',a) # ['pythonn', 'python']
r4=re.findall('python?',a) # ['python', 'python', 'pytho']
print(r1)
print(r2)
print(r3)
print(r3)
3.3 JSON
JSON是一种轻量级的数据交换格式。
- JSON载体:JSON字符串
- JSON优势:易于阅读、易于解析、网络传输效率高,适合跨语言交换数据
JSON字符串:是指符合JSON格式的字符串
注意:JSON中只能使用双引号
3.3.1 JSON函数
| 函数 | 功能 |
|---|---|
json.loads(json字符串) |
反序列化,JSON字符串转Python对象 |
json.dumps(python对象) |
序列化,Python对象转JSON字符串 |
3.3.2 JSON与Python类型的对照
| JSON | Python |
|---|---|
object |
dict |
array |
list |
string |
str |
number(int) |
int |
number(real) |
float |
true |
True |
flase |
False |
null |
None |
3.4 函数式编程
3.4.1 闭包
闭包 = 函数 + 环境变量
(环境变量必须函数定义时的外部变量,且不为全局变量)
闭包示例代码:
def curve_pre():
a = 25
b = 2
def curve():
return b * a
return curve # 实质是返回了函数及现场环境变量
a = 10 # a并没有在调用curve函数中起到作用
r = curve_pre()
print(r())
print(r.__closure__)
print(r.__closure__[0].cell_contents)
print(r.__closure__[1].cell_contents)
# 输出结果
50
(, | )
25
2
| | 代码示例:
如果没有在函数中引用全局变量,或者仅引用局部变量,都不会形成闭包

① global/nonlocal
global
| 作用 | 使用范围 |
|---|---|
| 标识该变量是全局变量 | 任何地方 |
nonlocal
| 作用 | 使用范围 |
|---|---|
| 标识该变量是上一级函数中的局部变量 | 只能用于嵌套函数中 |
示例代码:
闭包优势:没有改变全局变量


3.4.2 匿名函数
匿名函数:
lambda 参数:表达式(不能是语句或代码块)
三元表达式:真值结果 if 条件 else 假值结果
3.4.3 高阶函数
① 映射 map
格式:
map(函数,序列[,函数其他参数1,函数其他参数2..])
功能:通过参数函数对参数序列一一做映射
返回值:迭代器对象
# 注意:map最终得到结果的元素个数,取决于此三者最短长度
list_x = [1, 2, 3, 4, 5]
list_y = [2, 4, 6, 8, 9]
list_z = [2, 4, 6, 8, 9]
def square(x, y, z):
return x * x + y + z
# def函数
m1 = map(square, list_x, list_y, list_z)
# 匿名函数
m2 = map(lambda x, y, z: x * x + y + z, list_x, list_y, list_z)
print(list(m1))
print(list(m2))
# 输出结果
[5, 12, 21, 32]
[5, 12, 21, 32]
② 累积 reduce
格式:
reduce(函数,序列,初始参数)
功能:对参数序列中元素进行累积
注意:参数函数应至少有两个参数
from functools import reduce
list_x = ['1', '2', '3', '4', '5']
r1 = reduce(lambda x, y: x + y, list_x)
r2 = reduce(lambda x, y: x + y, list_x, 'hello')
print(r1)
print(r2)
# 输出结果
12345
hello12345
③ 过滤 filter
格式:
filter(函数,序列)
功能:过滤序列
注意:参数函数返回值必须为真值或假值
返回值:迭代器对象
list_x = [1, 0, 2, 0, 5, 0, 0]
f = filter(lambda x: True if x!=0 else False , list_x)
print(list(f))
# 输出结果
[1, 2, 5]
3.5 装饰器
优点:提高代码复用性,不破坏代码实现
说明:一个函数可以使用多个装饰器
import time
# 装饰器
def decorator(func):
def wrapper(*args, **kw): # *args可变参数,**kw关键字参数
print(time.time())
func(*args, **kw)
return wrapper
# @语法糖
@decorator
def f1(func_name):
print(func_name)
@decorator
def f2(func_name1, func_name2):
print(func_name1, func_name2)
@decorator
def f3(func_name1, func_name2, **kw):
print(func_name1, func_name2, kw)
f1('boom')
f2('boom', 'chen')
f3('boom', 'chen', a=1, b='2')
# 输出结果
1569060825.7342236
boom
1569060825.7342236
boom chen
1569060825.7352095
boom chen {'a': 1, 'b': '2'}
4 实战爬虫总结

爬虫库/框架
- Beautiful Soup
- Scrapy
5 Pythonic
① 字典取代switch
def sunday():
print('俺是星期天')
def monday():
print('俺是星期一')
def tuesday():
print('俺是星期二')
def default():
print('俺是default')
switcher = { # 注意:()如果直接写在键值中,会导致所有函数都执行
0: sunday,
1: monday,
2: tuesday
}
day = 8
day_name = switcher.get(day, default)()
② 列表推导式
[操作 for语句 if语句]
遍历列表
a = [1, 2, 3, 4, 5, 6] # 也可以用()、{}
b = [i ** 2 for i in a if i<=5]
print(b) # 如果b是元组,则需要使用for循环打印出来
# 输出结果
[1, 4, 9, 16, 25]
遍历字典
student = {
'boom': 18,
'chen': 19,
'cyl': 20
}
b = {value: key for key, value in student.items()}
print(b)
# 输出结果
{18: 'boom', 19: 'chen', 20: 'cyl'}