信贷评分卡--开发流程篇
目录
一、评分卡介绍
二、数据收集
三、数据准备
3.1. 数据准备包括:处理异常值、缺失值、定义好坏客户、样本量、定义样本窗口期等。
3.2. 变量可视化:可助于寻找特征数据之间的关系和发现问题。
四、变量筛选
4.1. IV和WOE
4.2. 第二次筛选:相关性分析
4.3. 衍生变量(组合变量)
五、变量分箱
六、建立模型
6.1. logit变换函数推导
6.2. 如何将logistic回归系数转化为信用评分
七、模型验证
八、模型部署
九、模型监控
一、评分卡介绍
信用评分是通过统计模型对潜在客户和已有客户在贷款时的风险通过打分的方式进行评估的一种方法。比如:年龄变量,25岁以下打分120,25-35岁打分150,35-50岁打分180,50岁以上则打分150。通过对申请人特征打分,相加之和再进行决策。评分卡模型建立可做多种决策,如:是否同意放款;是否同意其提升信用额度;给其发放哪一种信用卡;以及客户逾期后,如何催讨。
评分卡开发流程:
- 数据收集
- 数据准备
- 变量筛选
- 粗分类
- 模型开发
- 模型验证(很重要!很多模型开发好后,并不代表是好的模型)
- 评分卡拉伸
- 部署模型
模型部署完成后,不代表项目就可以安枕无忧了,后续要需要做模型的监控,随着时间的推移(因为市场的变动,又或者黑中介对模型的检测),模型的表现力会慢慢的的下降。
二、数据收集
数据收集分为:内部数据源和外部数据源。内部数据源:①、申请数据(Application Data):身份证、年龄三要素等;②、行为数据(Behavioural Data):贷款后还款情况等。外部数据源:芝麻分、同盾分等第三方大数据。
| 数据收集流程 | |
| 第一阶段 | 原始数据(Origination):贷前收集的申请数据 |
| 第二阶段 | 行为数据(Behaviour):用户还款历史、产品使用情况 |
| 第三阶段 | 催收数据(Collection):逾期的客户的行为数据,推测成为呆账坏账的概率 |
根据数据的收集流程,我们也可以将评分卡分为三类卡:A卡、B卡、C卡
| 评分卡名称 | 评分卡概述 |
| A卡(Application scorecard) | 贷前审批阶段对借款申请人的量化评估 |
| B卡 (Behaviour scorecard) | 贷后管理,通过借款人的还款行为,及其他维度,预测借款人未来的还款能力和意愿 |
| C卡(Collection scorecard) | 催收管理,借款人当前逾期前提下,预测该笔贷款未来变为坏账的概率,由此衍生出:滚动率、还款率、失联率等细分模型 |
注意:不同的产品要开发不同的评分卡,数据不能混合着用。(比如:信用贷和抵押贷产品对逾期宽容程度是不同的,开发抵押贷产品C卡时,不能将信用贷数据并在一起开发。)
数据获取方法:①、购买(同盾、聚信立、公安OCR);②、爬虫(法院执行名单、黑名单);③、和第三方公司合作
三、数据准备
3.1. 数据准备包括:处理异常值、缺失值、定义好坏客户、样本量、定义样本窗口期等。
- 定义好坏客户是灵活的,需要和业务线紧密沟通,一般逾期M1+(M:months,逾期超过1个月或30天以上)为坏客户,基本逾期M3+客户还款率极低。但如何定义好坏客户最重要还是要结合产品特性及业务,不同产品的逾期宽容度是不一样的,开发模型仓促也会受到影响。
- 样本量多少适合做模型?这个取决于数据质量和算法选取,参考某谷歌工程师说的,模型开发训练数据量需求是模型参数的10倍以上。如模型开发有10个维度,则需要100条数据量。亦可参考信贷行业公认经验,1000条以上好客户和1000条坏客户。刚上线的模型准确率不高有可能是因为坏客户数太少,前期强规则和反欺诈规则过滤掉大量的坏客户,导致模型会由偏差,这段期间模型可不做决策,用来累计收集数据。如果遇到样本极度不均衡的情况下(好客户数达到20多万,而坏客户数才1000左右),通常处理方法有两个:过采样和下采样。又或者我们可以先开发模型再进行测试,如果测试结果准确性高,表现力好,稳定性良好,也是一个好的模型。
- 样本的观察期和表现期:①、观察期:搜集特征的时间窗口,通常为3年内;②、表现期:预估客户表现时间段,通常6个月、12个月或18个月。观察点不一定是哪天,可以是某个时间段。如2019年1月1日有个客户过来申请贷款,机构用模型评估他未来1年的还款情况再决定是否贷款。那么应该选取哪个时间段的数据来建模呢?我们要评估1年的表现期,那么可以用2018年1月1日前贷款的客户,在2018年至2019年还款行为来预测他未来行为。而2018年1月1日前贷款客户有很多,我们可以设个观察期3年,即可选取2015年1月1日至2018年1月1日贷款客户的特征(X)在2018年至2019年还款行为(Y)建模。由此可看评分卡模型是有滞后性的,我们需要对其进行实时监控。
- 异常值处理:在建模的时候可剔除异常值,而在分析问题和改善决策契机的时候需要保留异常值。寻找异常值的方法:①、K-mean(无监督学习方法);②、箱型图(上下限以外的数据点即是异常值)
- 缺失值处理方法:①、平均值填充(会带来比较大的波动);②、中位数填充;③众数填充(常用);④、根据现有特征建简单回归预测缺失值(复杂)。缺失值处理比较灵活,更多要根据业务知识和经验来填充。
3.2. 变量可视化:可助于寻找特征数据之间的关系和发现问题。
标准化绘图公式:某分组坏客户比例 = 某分组坏客户数 ÷ 某分组总客户数
| 年龄段 | 总客户 | 坏客户数 | 好客户数 | 坏客户比例 |
| <21 | 10 | 5 | 5 | 0.5 |
| 21-30 | 2500 | 1000 | 1500 | 0.4 |
| 31-40 | 5000 | 1500 | 3500 | 0.3 |
| 41-50 | 3500 | 700 | 2800 | 0.2 |
| 51-60 | 2000 | 300 | 1700 | 0.15 |
| >=60 | 20 | 2 | 18 | 0.1 |
(数据不是真实数据,做个例子)从上图可看,年龄越大,逾期率越低。
四、变量筛选
变量筛选步骤(适合逻辑回归):1.原始变量集 —> 2.计算变量预测能力 —> 3.筛选预测能力强的变量 (数据预处理可以省掉很多步骤,可看:https://blog.csdn.net/weixin_41712808/article/details/85323417 中的特征相关性和预处理 )
具体方法:①、初步筛选:iv(适合逻辑回归评分卡);②、第二次筛选:相关性分析
其他方法有:F score 、信息增益等
4.1. IV和WOE
公式:
- odds:是指某事件发生的可能性(概率)与不发生的可能性(概率)之比。 公式:
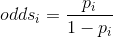 (
( :发生i事情概率)
:发生i事情概率) - OR :Odds rate 比值比,风险比,优势比。其计算公式为两个odds之比。 公式:
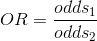
- WOE:Weight of Evidence 证据权重值 公式:
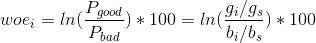 (i:第i组,
(i:第i组, =第i组坏客户数,
=第i组坏客户数,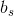 =总坏客户数,
=总坏客户数, =第i组好客户数,
=第i组好客户数,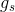 =总好客户数,
=总好客户数,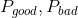 )
) - IV:Information Value 信息价值 公式:
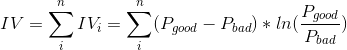
例子:计算各组年龄的woe及年龄IV值
| Age | good | bad | ||
| <18 | 50 | 40 | ||
| 18-30 | 100 | 60 | ||
| 30-60 | 100 | 80 | ||
| >60 | 80 | 40 | ||
| All | 330 | 220 | 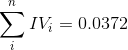 |
年龄IV是将各组的![]() 相加之和,等于0.0372。根据经验:
相加之和,等于0.0372。根据经验:
- IV<0.02时,该变量对预测目标变量(预测好坏客户)几乎无帮助(建模时可剔除该变量)
- 0.02 ≦ IV <0.1,该变量对预测目标变量有微弱帮助
- 0.1 ≦ IV < 0.3,该变量对预测目标变量有一定帮助
- 0.3 ≦ IV ≦ 0.5,该变量对预测目标变量有很大帮助
- IV>0.5, 该变量对目标变量有过度预测倾向,应该仔细检查是否选了和目标变量有很强因果关系的变量,再结合实际场景是否可用该变量来预测目标变量。
由例子来看,年龄这个变量用来预测是否好坏客户有帮助的,可用做建模特征。
拓展:从其他帖子和课程中有提到,odds和woe的关系,大多讲的不是很清楚,都是说![]() 。但我翻阅了一些资料,odds是机率,可能发生概率除以不发生概率,公式:
。但我翻阅了一些资料,odds是机率,可能发生概率除以不发生概率,公式:![]() ,前后思考和woe并无关系呀,后来找呀,发现了比值比(OR)的东西。我的推断是这样的,某变量分3组预测好坏客户是否有帮助:
,前后思考和woe并无关系呀,后来找呀,发现了比值比(OR)的东西。我的推断是这样的,某变量分3组预测好坏客户是否有帮助:
| 好客户(个数) | 坏客户(个数) | 和 | |
| 1组 | a | d | |
| 2组 | b | e | |
| 3组 | c | f | |
| 和 | 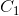 |
 |
假设![]() 是1组好坏客户比率,
是1组好坏客户比率,![]() 是总好坏客户比率。
是总好坏客户比率。
![]()
![]()
![]()
有木有发现这个结果很眼熟呢,就是我们之前写的WOE公式,![]() 就是1组好客户占比,
就是1组好客户占比,![]() 则是1组坏客户占比:
则是1组坏客户占比:![]() 。统计学中还有个公式赔率odd:获胜概率除以失败概率,和OR比值比是一样的事情,so,化简后:odds=好客户占比/坏客户占比。
。统计学中还有个公式赔率odd:获胜概率除以失败概率,和OR比值比是一样的事情,so,化简后:odds=好客户占比/坏客户占比。
另一个心得:IV公式其实就是各组woe加权后累加之和。
4.2. 第二次筛选:相关性分析
变量之间相关性分析,如果两两之间相关性显著,会影响模型的预测效果。我们希望选择的变量是该变量和预测目标变量尽可能高度相关,而和其他信息维度尽可能低度相关。计算变量之间相关性有两个方法:皮尔斯和斯皮尔曼。皮尔斯方法计算相关性准确性更高,但这个方法只适合服从正态分布的变量,而斯皮尔曼则没有这个要求。如果使用皮尔斯方法,还需要检验变量是否服从正态分布,工作是比较繁琐的,所以折中可以用斯皮尔曼方法。(之前写过一篇用python处理特征相关性,用corr函数亦可:https://blog.csdn.net/weixin_41712808/article/details/85323417)
4.3. 衍生变量(组合变量)
衍生变量就是由两个或两个以上的变量变换所得,使得衍生出来的新变量和其他变量相关性较低,避免发生多重共线性问题。比如:我们发现年龄和收入的相关系数是0.76,相关性是较高的。而固定债务和收入比率(FOIR)和年龄相关性只有0.18,我们可以用收入和债务变量变换后的变量来代替收入和债务,从而可降低变量间相关性。
如何处理变量转换需要由良好的领域知识和开发模型的经验,我个人心得是,多问风控人员,和业务线紧密沟通。比如上面说的FOIR是不是很像风控员做的负债表中一个指标。
五、变量分箱
为了信用评分模型的结果形式是可以打分的,需要将变量分类。变量分两种:连续变量和离散变量,对连续型变量进行分段再统计学上称为分箱。离散型变量取值较少(如:性别只有两类)可不需要对其处理,如果离散变量取值较多时,需要对其类别归并,归并方法,可以按woe值接近原则,woe相近归一类(如:职业有很多,外科医生和内科医生可以归为一类)。
前面用IV值筛选变量,我们判断变量对预测目标变量是否重要的同时,可以分析分箱是否合理。分箱一般遵循以下原则:
- 分箱数应当适中,不宜过多或过少,一般3-6个。
- 每个分箱数据量合理,一般是总量5%以上,且目标变量取值都有。(如:客户量共2000条,若想要年龄20-25岁为一段分箱,这段数据量需100条以上,且既有好客户也有坏客户。)
- 结合目标变量,分箱应该能表现出明显的趋势特征,趋势可以单调上升(或下降),亦可表现出中间低(或高),两头高(或低)的U(倒U)型趋势。
- 邻近的分箱woe差值较大(亦可看作,邻近的分箱目标变量分布差异较大)(邻近分箱:如20-25岁,25-30岁就是邻近的)

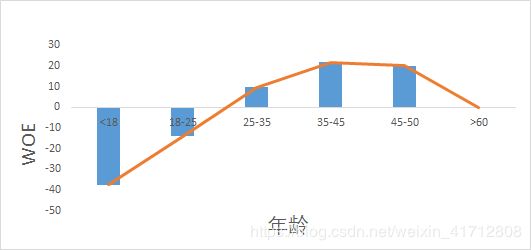
从上图可看,作图的分箱是不合理的,而右图是优化后的分箱。通过右图可得违约率(woe)随着年龄的增加而下降,但60岁以后违约率又开始上升。
分箱优化方法:①、卡方;②、kmean;③、平均法
好的分箱可以提高变量IV值,从而增大变量对目标变量的预测能力。
六、建立模型
数据处理后,我们可以终于可以进行建模了,建模的算法有很多,比如神经网络、决策树、逻辑回归等。我们这里选用的是逻辑回归。Logistic回归常用于预测离散型目标变量,它的优点:稳定,广泛用于评分卡开发;解释性强,评分卡易于理解。Logistict回归详细介绍:https://blog.csdn.net/weixin_41712808/article/details/85788687
6.1. logit变换函数推导
Logistict回归的模型形式为:![]()
sigmoid函数: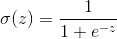
目标函数![]() 推导过程:
推导过程:
![]()
sigmoid函数得到的是预测值概率,如预测某客户是坏客户的概率是多少。而odds则是预测客户赔率是多少:
![]()
看到上面的化简后结果是不是很眼熟,所以logit变换函数:![]()
6.2. 如何将logistic回归系数转化为信用评分
目前行业常用此方程表示信用评分取值关系:![]() ——①式
——①式
我们通常希望评分卡满足以下要求:
- 将分数控制再一定范围,比如FICO评分是在300-900之间
- 在特定分数时,好坏客户有一个特定刻度比,如:在500分时,好客户:坏客户=50:1。(这里的刻度比我们用
 来表示,在统计学来说这个可以用优比——odds来表示,但我觉得这很容易和上面的odds混淆,记住:=好客户占比/坏客户占比)
来表示,在统计学来说这个可以用优比——odds来表示,但我觉得这很容易和上面的odds混淆,记住:=好客户占比/坏客户占比) - 评分增加能反映好坏客户比例关系的变化,例如当评分增加50分时,能增加一倍。
为了满足以上条件,那么评分卡方程需满足:
![]() ——②式
——②式
pdo:表示为了使增加一倍需增加得评分值
解①、②方程,可得:
![]()
![]()
![]()
![]() :基本分数,即在特定刻度比时对应的特定分数。
:基本分数,即在特定刻度比时对应的特定分数。![]() :定义好坏客户得评分临界值,高于offset则是好客户,反之坏客户。Factor:系数,回归方程转为信用评分得系数。
:定义好坏客户得评分临界值,高于offset则是好客户,反之坏客户。Factor:系数,回归方程转为信用评分得系数。
从上面公式,我们已经得到offset和factor值,那么我们也可推导出该客户得评分是多少:
![]()
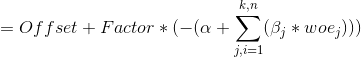
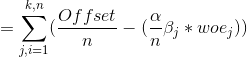
k:各变量得分箱数;n:变量个数;i:第i个样本;j:第i个样本的第j个变量; :logistic回归常数项系数;
:logistic回归常数项系数;![]() :logistic回归第j个变量系数;
:logistic回归第j个变量系数;![]() :代表第j个变量的各分箱woe值,如下图:
:代表第j个变量的各分箱woe值,如下图:
| 样本序号 | 变量a | 变量a的woe |
| 0 | 18 | 0.102857 |
| 1 | 9 | -0.49062 |
| 2 | 12 | -0.49062 |
| 3 | 12 | -0.49062 |
| 4 | 12 | -0.49062 |
| 8 | 18 | 0.102857 |
| 10 | 11 | -0.49062 |
| 14 | 18 | 0.102857 |
变量a有两个分箱,9-12段woe: -0.49062,13-18段woe:0.102857,变量值在哪个阶段,该样本j变量的woe值是对应分箱的woe值。
从公式看,预测的信用评分Score值是好坏客户临界分数减各个变量的woe代入logistic回归方程的和。除此我们还可以变换得到各变量、各分箱对应的评分值:
分箱对应评分值=![]() (这里的woe是j变量的各分箱woe,没指定哪个样本)
(这里的woe是j变量的各分箱woe,没指定哪个样本)
七、模型验证
模型开发前,我们一般会将数据分为:训练集train、测试集test、跨时间数据oot(train和test是同一时间段数据,一般三七分,oot是不同时间段的数据,用来验证模型是否适用未来场景),除此还可以用交叉验证方法,交叉验证是防止某数据过度集中。验证指标有:
- 混淆矩阵(accuracy:准确性;sensitivity:阳性过滤能力即坏客户过滤能力;precision坏客户预测准确性;F1 score:前两个权重指标)(如果好坏客户数据量不均衡的状态下,sensitivity和precision值会偏小)
- 区分能力(KS,AUC)(一般KS大于0.3,AUC大于0.7算合格)
- 稳定性(PSI)(PSI小于0.2能接受,不过还可以优化,小于0.1稳定性良好)
- 排序能力(lift table)(良好是呈单调性,若图形有上下波动说明样本量不均衡或模型有问题)
八、模型部署
这步骤主要工作在于如何设置阈值,即设定坏客户概率大于多少时定为坏客户,拒绝放款。这部分结合产品特性,和业务线沟通可以更好的确定阈值,当然也可以用recall函数进行调整。
九、模型监控
模型部署完不代表工作就完成,还需要不断的监控,部署的时候可以设定几个指标,如:区分能力、稳定性及单调性,可以每天返回这几个指标,如果指标出现异常的时候,可以自动发送邮件或者出现红色指标提示。进而再寻找问题,优化模型。
End……后面努力再写关于评分卡的python应用篇
参考文献及资料,感谢前辈们的经验传授:
- 《IBM SPSS 数据分析与挖掘实战案例精粹》张文彤 钟云飞 编著
- 《机器学习实战》Peter Harrington著
- 《python信用评分卡建模》视频 肥猫和大熊熊
- 《python数据分析与机器学习实战》视频 唐宇迪