【机器学习之路】十三种回归模型预测房价
数据:https://www.kaggle.com/santibermejo/xgboost-for-house-price-prediction
这篇文章汇总了13个机器学习的回归算法,对比它们在同一个数据下的预测的效果。其实就是为了选模型的时候方便一点,一个一个试太麻烦了
- 导入需要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import warnings
# filter warnings
warnings.filterwarnings('ignore')
# 正常显示中文
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 正常显示符号
from matplotlib import rcParams
rcParams['axes.unicode_minus']=False
- 导入数据
os.chdir('E:\\kaggle\\house_price')
data=pd.read_csv('train.csv')
- 数据预处理
data['MSSubClass']=data['MSSubClass'].astype(str) #MSSubClass是一个分类变量,所以要把他的数据类型改为‘’str‘’
Id=data.loc[:,'Id'] #ID先提取出来,后面合并表格要用
data=data.drop('Id',axis=1)
x=data.loc[:,data.columns!='SalePrice']
y=data.loc[:,'SalePrice']
mean_cols=x.mean()
x=x.fillna(mean_cols) #填充缺失值
x_dum=pd.get_dummies(x) #独热编码
x_train,x_test,y_train,y_test = train_test_split(x_dum,y,test_size = 0.3,random_state = 1)
#再整理出一组标准化的数据,通过对比可以看出模型的效果有没有提高
x_dum=pd.get_dummies(x)
scale_x=StandardScaler()
x1=scale_x.fit_transform(x_dum)
scale_y=StandardScaler()
y=np.array(y).reshape(-1,1)
y1=scale_y.fit_transform(y)
y1=y1.ravel()
x_train1,x_test1,y_train1,y_test1 = train_test_split(x1,y1,test_size = 0.3,random_state = 1)
- 导入模型
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.neural_network import MLPRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.tree import ExtraTreeRegressor
from xgboost import XGBRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import BaggingRegressor
将模型和他们的名字分别放到两个列表里,然后建一个空列表保存他们的得分
models=[LinearRegression(),KNeighborsRegressor(),SVR(),Ridge(),Lasso(),MLPRegressor(alpha=20),DecisionTreeRegressor(),ExtraTreeRegressor(),XGBRegressor(),RandomForestRegressor(),AdaBoostRegressor(),GradientBoostingRegressor(),BaggingRegressor()]
models_str=['LinearRegression','KNNRegressor','SVR','Ridge','Lasso','MLPRegressor','DecisionTree','ExtraTree','XGBoost','RandomForest','AdaBoost','GradientBoost','Bagging']
score_=[]
写一个训练模型的循环
for name,model in zip(models_str,models):
print('开始训练模型:'+name)
model=model #建立模型
model.fit(x_train,y_train)
y_pred=model.predict(x_test)
score=model.score(x_test,y_test)
score_.append(str(score)[:5])
print(name +' 得分:'+str(score))
看一下训练的结果

SVR的得分是负值,原因是SVR训练数据需要标准化处理。
得分最高的是’XGBoost’和’GradientBoost’,他们都是集成学习,得分都超过了百分之九十,如果再分别进行调参的话,效果可能会更好,这里调参过程就不给大家演示了。
- 平滑处理预测值y
平滑处理y值,x不处理。(x代表特征,y代表预测值)
y_log=np.log(y)
x_train,x_test,y_train_log,y_test_log = train_test_split(x_dum,y_log,test_size = 0.3,random_state = 1)
得到结果对比
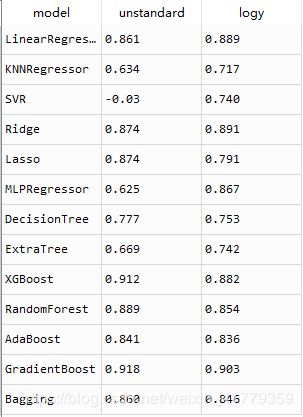
SVR(),MLP,等一些模型的效果明显提升,集成学习的算法都出现了轻微的下降,看样子集成学习不太适合将预测值平滑处理。
如果所有的模型都用标准化过的数据来训练效果会怎么样呢?
models=[LinearRegression(),KNeighborsRegressor(),SVR(),Ridge(),Lasso(),MLPRegressor(alpha=20),DecisionTreeRegressor(),ExtraTreeRegressor(),XGBRegressor(),RandomForestRegressor(),AdaBoostRegressor(),GradientBoostingRegressor(),BaggingRegressor()]
models_str=['LinearRegression','KNNRegressor','SVR','Ridge','Lasso','MLPRegressor','DecisionTree','ExtraTree','XGBoost','RandomForest','AdaBoost','GradientBoost','Bagging']
score_1=[]
for name,model in zip(models_str,models):
print('开始训练模型:'+name)
model=model
model.fit(x_train1,y_train1)
y_pred=model.predict(x_test1)
score=model.score(x_test1,y_test1)
score_1.append(str(score)[:5])
print(name +' 得分:'+str(score))
训练结果如下图所示:
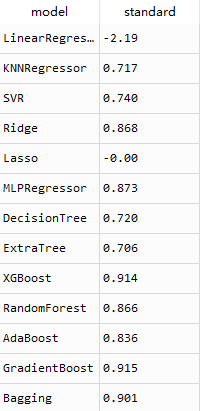
由结果可以看出来线性回归和Lasso回归并不适合用标准化的数据来训练模型。把两种结果对比你一下,看一看哪些模型需要把数据标准化处理,哪些不需要。

三个结果一起看
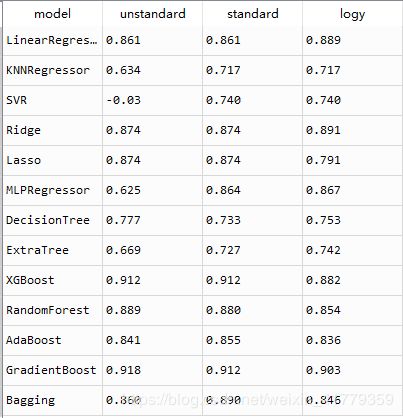
需要标准化的模型:[‘SVR’,‘MLPRegressor’,‘Bagging’,‘AdaBoost’,‘KNNRegressor’]
需要平滑处理y的模型:[‘LinearRegression’,‘Ridge’,‘ExtraTree’]
剩下的模型就不需要对数据进行处理了
下面就分别来训练这些模型,得到最后的结果。
models=[LinearRegression(),KNeighborsRegressor(),SVR(),Ridge(),Lasso(),MLPRegressor(alpha=20),DecisionTreeRegressor(),ExtraTreeRegressor(),XGBRegressor(),RandomForestRegressor(),AdaBoostRegressor(),GradientBoostingRegressor(),BaggingRegressor()]
models_str=['LinearRegression','KNNRegressor','SVR','Ridge','Lasso','MLPRegressor','DecisionTree','ExtraTree','XGBoost','RandomForest','AdaBoost','GradientBoost','Bagging']
score_adapt=[]
for name,model in zip(models_str,models):
if name in ['LinearRegression','Ridge','ExtraTree']:
print('开始训练模型:'+name+' 平滑处理')
model=model
model.fit(x_train,y_train_log)
y_pred=model.predict(x_test)
score=model.score(x_test,y_test_log)
score_adapt.append(str(score)[:5])
print(name +' 得分:'+str(score))
elif name in ['SVR','MLPRegressor','Bagging','AdaBoost','KNNRegressor']:
print('开始训练模型:'+name+' 标准化处理')
model=model
model.fit(x_train1,y_train1)
y_pred=model.predict(x_test1)
ypred_original=scale_y.inverse_transform(y_pred)
score=model.score(x_test1,y_test1)
score_adapt.append(str(score)[:5])
print(name +' 得分:'+str(score))
else:
print('开始训练模型:'+name+' 普通')
model=model
model.fit(x_train,y_train)
y_pred=model.predict(x_test)
ypred_original=scale_y.inverse_transform(y_pred)
score=model.score(x_test,y_test)
score_adapt.append(str(score)[:5])
print(name +' 得分:'+str(score))
得到最后结果:
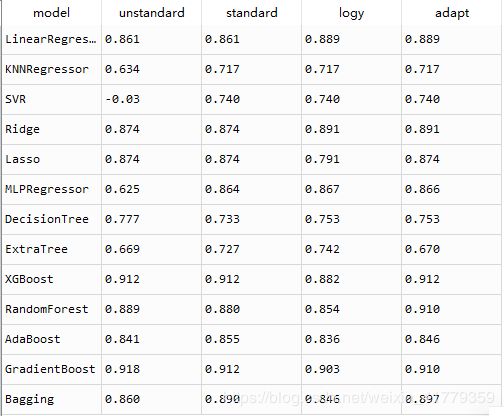
基本上每个模型都找到了效果最好的数据形式,得到了相对其他数据形式更好的效果。
下面是每组模型拟合的图像
- 还有可以改进的地方
对于标准化处理的模型,其他模型的训练数据形式不变。只将连续型变量标准化处理,分类变量热码处理得到训练结果如下所示
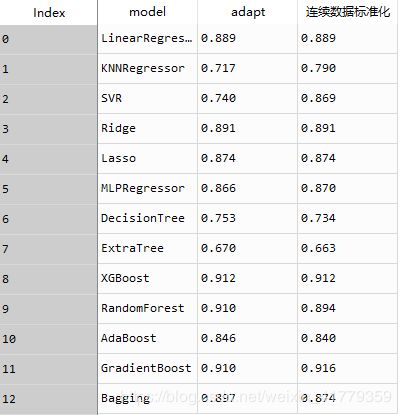
KNN和SVR 都有明显的提升
score_x=[]
for name,model in zip(models_str,models):
if name in ['MLPRegressor','AdaBoost','Bagging','ExtraTree']:
print('开始训练模型:'+name+' 标准化处理')
model=model
model.fit(x_train1,y_train1)
y_pred=model.predict(x_test1)
ypred_original=scale_y.inverse_transform(y_pred)
score=model.score(x_test1,y_test1)
score_x.append(str(score)[:5])
print(name +' 得分:'+str(score))
elif name in['SVR','KNNRegressor']:
print('开始训练模型:'+name+' 分开标准化处理')
model=model
model.fit(x_trainx,y_train1)
y_pred=model.predict(x_testx)
ypred_original=scale_y.inverse_transform(y_pred)
score=model.score(x_testx,y_test1)
score_x.append(str(score)[:5])
print(name +' 得分:'+str(score))
elif name in ['LinearRegression','Ridge']:
print('开始训练模型:'+name+' 平滑处理')
model=model
model.fit(x_train,y_train_log)
y_pred=model.predict(x_test)
score=model.score(x_test,y_test_log)
score_x.append(str(score)[:5])
print(name +' 得分:'+str(score))
else:
print('开始训练模型:'+name+' 普通')
model=model
model.fit(x_train,y_train)
y_pred=model.predict(x_test)
ypred_original=scale_y.inverse_transform(y_pred)
score=model.score(x_test,y_test)
score_x.append(str(score)[:5])
print(name +' 得分:'+str(score))
汇总所有数据
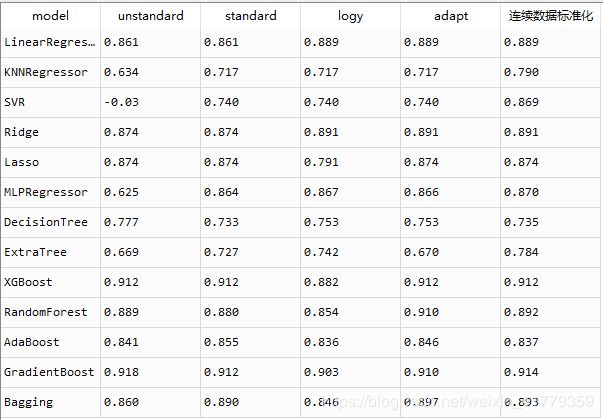
你可以看到每个模型的精度变化
总结:不同的模型需要训练数据的形式是不同的
需要对x,y都标准化处理的模型有:[‘MLPRegressor’,‘AdaBoost’,‘Bagging’,‘ExtraTree’]
需要只对y平滑处理的有:[‘LinearRegression’,‘Ridge’]
需要对y和x中的连续型数据标准化处理的模型:[‘SVR’,‘KNNRegressor’]
剩下的5个模型不需要对x和y进行处理:[‘Lasso’,‘DecisionTree’,‘XGBoost’,‘RandomForest’,‘GradientBoost’]
准确率最高的模型为【‘XGBoost’,‘RandomForest’,‘GradientBoost’】,都是集成学习算法。
线性回归模型

KNN

Ridge

Lasso
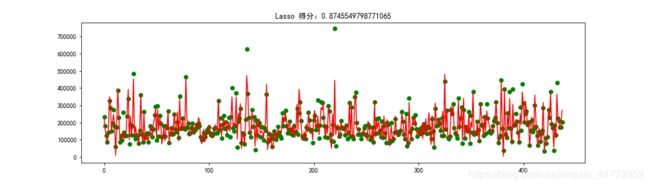
XGBoost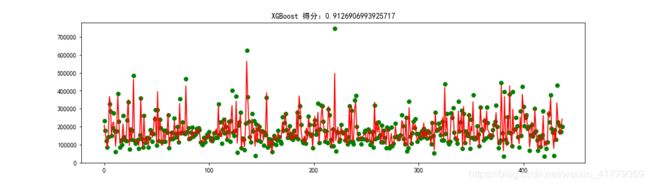
Bagging

GradientBoost

剩下的图片就不一一展示了。
- 基展开
基展开就是增加维度
原始数据共有79个特征,但是这些特征可能还不足以预测房价,房价的高低可能还有这些特征的两两组合有关系,所以我们可以尝试一下。
步骤
1.将原始数据的 连续型变量和分类型变量拆开。
2.将连续型变量基展开(用到PolynomialFeatures函数),将分类型变量独热编码。
3. 最后合在一起
#将连续型变量和分类型变量分开
numeric_cols=x.columns[x.dtypes !='object']
object_cols=x.columns[x.dtypes =='object']
x_num=x.loc[:,numeric_cols]
x_object=x.loc[:,object_cols]
#将连续型变量积展开,将分类变量热码处理
from sklearn.preprocessing import PolynomialFeatures
pf = PolynomialFeatures(degree=2)
x_num_big=pf.fit_transform(x_num)
x_num_big=pd.DataFrame(x_num_big)
x_object_big=pd.get_dummies(x_object)
x_num_big['id']=Id
x_object_big['id']=Id
x_ji=pd.merge(x_num_big,x_object_big,on='id',how='left')
x_ji=x_ji.drop('id',axis=1)
x_train_ji,x_test_ji,y_train,y_test = train_test_split(x_ji,y,test_size = 0.3,random_state = 1)
x_ji 是我们对连续型变量基展开和对分类型变量独热编码后最后的到的数据,通过下图可以看出,原始数据由原来的79个特征,转化为933个特征

对于神经网络和SVR也同样需要一组标准化的测试集和训练集,y1就不需要处理了,直接用上面被处理过的。x_jin表示被标准化后的基展开数据
scale_xji=StandardScaler()
x_jin=scale_xji.fit_transform(x_ji)
scale_y=StandardScaler()
x_train_jin,x_test_jin,y_train1,y_test1 = train_test_split(x_jin,y1,test_size = 0.3,random_state = 1)
然后再一次开始训练模型
代码还是个上面的基本一样,只不过将x_train改成x_train_ji,x_test改成x_test_ji。else语句下面的改成x_train_jin,x_test_jin。
models=[LinearRegression(),KNeighborsRegressor(),SVR(),Ridge(),Lasso(),MLPRegressor(alpha=20),DecisionTreeRegressor(),ExtraTreeRegressor(),XGBRegressor(),RandomForestRegressor(),AdaBoostRegressor(),GradientBoostingRegressor(),BaggingRegressor()]
models_str=['LinearRegression','KNNRegressor','SVR','Ridge','Lasso','MLPRegressor','DecisionTree','ExtraTree','XGBoost','RandomForest','AdaBoost','GradientBoost','Bagging']
score_ji=[]
for name,model in zip(models_str,models):
if name not in ['KNNRegressor','SVR','MLPRegressor','ExtraTree','AdaBoost']:
print('开始训练模型:'+name)
model=model
model.fit(x_train_ji,y_train)
y_pred=model.predict(x_test_ji)
score=model.score(x_test_ji,y_test)
score_ji.append(str(score)[:5])
print(name +' 得分:'+str(score))
else:
print('开始训练模型:'+name)
model=model
plt.figure(figsize=(14,4)
score=model.score(x_test_jin,y_test1)
score_ji.append(str(score)[:5])
print(name +' 得分:'+str(score))
看一下效果
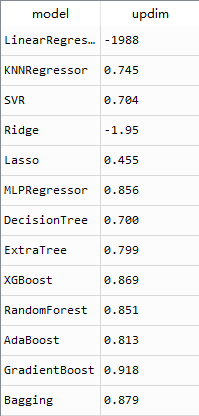
线性模型和岭回归模型出现了负值,应该是线性回归模型不适合高维特征,除了GradientBoost其它模型的结果都没有向好的方向发展,下面将这两次的预测结果对比一下就知道了
accuray_stats=pd.DataFrame({'model':models_str,'score':score_,'score2':score_2})
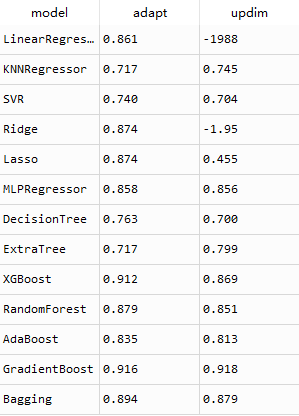
线性回归和岭回归模型出错,Lasso回归精度明显下降,DecisionTree精度轻微下降,ExtraTree模型精度提高,其他模型预测效果没有明显的变化。集成学习模型的效果普遍好于其他模型。
- 总结
这篇文章展示了不同回归模型在同一数据集下的预测效果。集成学习模型普遍优于其他简单模型。文章并没有涉及调整参数来提高训练精度的内容,大家有兴趣可以自己尝试,通过.get_params()来查看模型的参数,让后通过GridSearchCV进行网格搜索。
本文主要展示了不同模型和增加维度的方法来找到一个高精度的训练模型,由上文的结果可以看出,同一数据集在不同的模型下的到的预测结果是有很大差别的。通过增高维度并没有明显影响预测的精度,但这并不代表增加维度是一个没有多大用处的方法。