KMP算法入门【详解+例题模板】
kmp算法的主要作用在于对next数组的运用
- 性质1:对于每一个长度len的子串,该子串的最小循环节为len-next[len]
- 性质2:kmp的next不断向前递归的过程可以保证对于每一个当前前缀,都有一段后缀与之对应
下面是求next数组的2种模板,第一种大部分题目已经够用,第二种是优化版
next[]数组的运用。
这里需要深刻理解next数组的含义,所以需要花费一定的功夫去弄懂这些。。
首先,求next数组有两种方法。第一种是严蔚敏教授那本数据结构上的求法。代码如下:
void getnext(const char *s){
int i = 0, j = -1;
nextval[0] = -1;
while(i != len)
{
if(j == -1 || s[i] == s[j])
nextval[++i] = ++j;
else
j = nextval[j];
}
}这种求法的含义是:
next[i]代表了前缀和后缀的最大匹配的值(需要彻底明白这点,相当重要)
另外一种是对这种算法的改进版本,代码如下:
void getnext(const char *p) {//前缀函数(滑步函数)
int i = 0, j = -1;
nextval[0] = -1;
while(i != len)
{
if(j == -1 || p[i] == p[j]) //(全部不相等从新匹配 || 相等继续下次匹配)
{
++i, ++j;
if(p[i] != p[j]) //abcdabce
nextval[i] = j;
else //abcabca
nextval[i] = nextval[j];
}
else
j = nextval[j]; //子串移动到第nextval[j]个字符和主串相应字符比较
}
}改进的地方在于-1的运用,关于怎么优化我已经写过了。自己看下就行了。。。但是一定要明白。
不同之处:
没有优化的getnext函数,next数组存的是前缀和后缀的最大匹配值,而优化后的getnext函数存的是在这个基础,进行更高效的改进。
比如abcabca
改进前最后一个字符next[7]=4,表示的是前缀和后缀最大匹配是4,即abca和abca。
改进后的next[7]=-1。这点也需要彻底搞懂,才能灵活的运用next函数。
总结一下:
在求前缀和后缀的最大匹配值时,要使用第一种,也就是未优化的算法。在运用KMP时,使用第二种算法,因为避免了多余的判断,更加高效。
YY:
其实我们可以发现KMP算法的精华部分是一个DP。每次右滑时,都是根据前面状态得到的有用信息进行的。相当于记忆化更新。这样算法才具有了很高的效率。
---------------------
原文:https://blog.csdn.net/niushuai666/article/details/6965517
求next数组的模板
static void getnext() {
int j=0,k=-1;
next[0] = -1;
while(jkmp的模板
static int kmp() {
int i=0,j=0;
while(i
hdu1711
模板题
问题描述
给出两个数字序列:a [1],a [2],......,a [N]和b [1],b [2],......,b [M] (1 <= M <= 10000,1 <= N <= 1000000)。你的任务是找到一个数字K,它使[K] = b [1],[K + 1] = b [2],......,a [K + M - 1] = b [ M]。如果存在多个K,则输出最小的K.
输入
第一行输入是数字T,表示案例数。每个案例包含三行。第一行是两个数字N和M(1 <= M <= 10000,1 <= N <= 1000000)。第二行包含N个整数,表示[1],a [2],......,a [N]。第三行包含M个整数,表示b [1],b [2],......,b [M]。所有整数都在[-1000000,1000000]的范围内。
输出
对于每个测试用例,您应输出一行仅包含上述K的行。如果不存在这样的K,则输出-1。
样本输入
2
13 5
1 2 1 2 3 1 2 3 1 3 2 1 2
1 2 3 1 3
13 5
1 2 1 2 3 1 2 3 1 3 2 1 2
1 2 3 2 1
样本输出
6
-1
原题链接
import java.util.Scanner;
public class hdu1711 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int t = in.nextInt();
while(t-->0) {
n = in.nextInt();
m = in.nextInt();
s = new int[n];
p = new int[m];
next = new int[m];
for(int i=0;i
leetcode 28. 实现strStr()(Implement strStr())
模板题
class Solution {
public int strStr(String haystack, String needle) {
if(haystack==null || haystack.equals("") || haystack.length()<1)
return needle.equals("")?0:-1;
else if(needle==null || needle.equals("") || needle.length()<1)
return 0;
return match(needle.toCharArray(),haystack.toCharArray());
}
static int match(char[] p,char[] T) {
int[] next = buildNext(p);
int n = T.length,m = p.length,i = 0,j = 0;
while(it || p[j]==p[t]) {
j++;
t++;
N[j]=(p[j]!=p[t])?t:N[t];
}
else
t = N[t];
}
return N;
}
}
hdu1358
问题描述
对于具有N个字符的给定字符串S的每个前缀(每个字符具有介于97和126之间的ASCII代码),我们想知道该前缀是否是周期性字符串。也就是说,对于每个i(2 <= i <= N),我们想要知道最大的K> 1(如果有的话),使得长度为i的S的前缀可以写为A K,即A连接K次,对于一些字符串A.当然,我们也想知道期间K.
输入
输入文件由几个测试用例组成。每个测试用例包含两行。第一行包含N(2 <= N <= 1 000 000) - 字符串S的大小。第二行包含字符串S.输入文件以一行结尾,数字为零。
输出
对于每个测试用例,在一行输出“测试用例#”和连续的测试用例编号; 然后,对于具有周期K> 1的长度为i的每个前缀,输出前缀大小i和由单个空格分隔的周期K; 前缀大小必须按递增顺序排列。在每个测试用例后打印一个空行。
样本输入
3
AAA
12
aabaabaabaab
0
样本输出
测试案例#1
2 2
3 3
测试案例#2
2 2
6 2
9 3
12 4
推荐
JGShining | 我们已经为您精心挑选了几个类似的问题: 1686 3336 3746 3068 2203
这道题考察的是KMP算法中next数组的应用,必须理解透next[]数组代表的含义才能通过它解决这道题。
思路是先构造出 next[] 数组,下标为 i,定义一个变量 j = i - next[i] 就是next数组下标和下标对应值的差,如果这个差能整除下标 i,即 i%j==0 ,则说明下标i之前的字符串(周期性字符串长度为 i)一定可以由一个前缀周期性的表示出来,这个前缀的长度为刚才求得的那个差,即 j,则这个前缀出现的次数为 i/j 。所以最后输出i和i/j即可。
举这道题的第二组输入样例为例:
其next[]数组为:
i 0 1 2 3 4 5 6 7 8 9 10 11
a[i] a a b a a b a a b a a b
next[i] -1 0 1 0 1 2 3 4 5 6 7 8 ↓

next[i]值是0或-1的忽略。
注意:由于输出次数太多 (2 <= N <= 1 000 000),建议用printf输出,否则会超时。原文链接
import java.util.Scanner;
public class hdu1358 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int t = 0;
while(true) {
++t;
n = in.nextInt();
if(n==0)
break;
ch = in.next().toCharArray();
next = new int[n+5];//next最好多开点
next[0] = -1;
getnext();
System.out.println("Test case #"+t);
int j;
for(int i=0;i<=n;i++) {
if(next[i]==-1 || next[i]==0)
continue;
j = i - next[i];
if(i%j==0)
System.out.println(i+" "+i/j);
}
System.out.println();
}
}
static int[] next;
static char[] ch;
static int n;
static void getnext() {
int j=0,k=-1;
while(jhdu2087
没记错的话,是水题100题里面的,其实这题的数据暴力也能过,1000的数据规模,不过拿来练手kmp也是不错的
问题描述
一块花布条,里面有些图案,另有一块直接可用的小饰条,里面也有一些图案。对于给定的花布条和小饰条,计算一下能从花布条中尽可能剪出几块小饰条来呢?
输入
输入中含有一些数据,分别是成对出现的花布条和小饰条,其布条都是用可见ASCII字符表示的,可见的ASCII字符有多少个,布条的花纹也有多少种花样。花纹条和小饰条不会超过1000个字符长。如果遇见#字符,则不再进行工作。
输出
输出能从花纹布中剪出的最多小饰条个数,如果一块都没有,那就老老实实输出0,每个结果之间应换行。
样本输入
abcde a3
aaaaaa aa
#
样本输出
0
3
import java.util.Scanner;
public class hdu2087 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
String str="";
while(true) {
str = in.next();
if(str.equals("#"))
break;
s = str.toCharArray();
p = in.next().toCharArray();
n = s.length;
m = p.length;
next = new int[m+1];
next[0] = -1;
getnext();
System.out.println(kmp());
}
}
static char[] s;
static char[] p;
static int[] next;
static int n,m;
static void getnext() {
int j=0,k=-1;
while(j
hdu1686
问题描述
法国作家乔治·佩雷克(Georges Perec,1936-1982)曾写过一本名为“La disparition”的书,没有字母“e”。他是Oulipo集团的成员。这本书的引用:
Tout avait Pair normal,mais tout s'affirmait faux。Tout avait Fair normal,d'abord,puis surgissait l'inhumain,l'affolant。Il aurait voulusavoiroùs'articulaitl'association qui l'unissait au roman:stir son tapis,assaillantàtoutinstant son imagination,l'intuition d'un tabou,la vision d'un mal obscur,d'un quoi vacant ,d'un dit:la vision,l'avision d'unoubi commandant tout,oùs'abolissaitla raison:tout avait l'air normal mais ...
佩雷克可能会在接下来的比赛中获得高分(或者更低)。人们被要求在一些主题上写一个甚至是有意义的文本,尽可能少地出现一个给定的“单词”。我们的任务是为陪审团提供一个计算这些事件的计划,以获得竞争对手的排名。这些竞争对手经常写出非常长的文本,带有无意义的含义; 一系列500,000连续'T'并不罕见。他们从不使用空间。
因此,我们希望快速找出文本中出现单词(即给定字符串)的频率。更正式地:给出字母{A','B','C',...,'Z'}和该字母表上的两个有限字符串,单词W和文本T,计算T中W的出现次数W的所有连续字符必须与T的连续字符完全匹配。事件可能重叠。
输入
输入文件的第一行包含一个数字:要遵循的测试用例数。每个测试用例具有以下格式:
一行包含单词W,一行超过{'A','B','C',...,'Z'},其中1≤| W | ≤10,000(这里| W |表示字符串W的长度)。
带有文本T的一行,一个超过{'A','B','C',...,'Z'}的字符串,带有| W | ≤| T | ≤1,000,000。
输出
对于输入文件中的每个测试用例,输出应在一行中包含单个数字:文本T中单词W的出现次数。
样本输入
3
BAPC
BAPC
AZA
AZAZAZA
VERDI
AVERDXIVYERDIAN
样本输出
1
3
0
资源
华东区大学生程序设计邀请赛_热身赛
推荐
lcy | 我们已经为您精心挑选了几个类似的问题: 3336 3746 2203 3068 2087
原题链接
这题在kmp模板中做了点小改动,next[m]在kmp中再次凸显重要,普通的kmp模板用不到next[m]这点,因为到m已经匹配成功了,这点没什么用,但扩展kmp嘻嘻。开始的 kmp(0,0)return 1+kmp(i-m+1,0);的思路超时了,太暴力了主要是i-m+1这里每次匹配成功才+1,时间复杂度很高,应该差不多回到了O(n*m)
import java.util.Scanner;
public class hdu1686 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int t = in.nextInt();
while(t-->0) {
p = in.next().toCharArray();
s = in.next().toCharArray();
n = s.length;
m = p.length;
next = new int[m+1];
next[0] = -1;
getnext();
System.out.println(kmp());
}
}
static char[] s;
static char[] p;
static int[] next;
static int n,m;
static void getnext() {
int j=0,k=-1;
while(j
hdu3336
kmp+线性dp
问题描述
众所周知,AekdyCoin擅长字符串问题以及数论问题。当给定字符串s时,我们可以写下该字符串的所有非空前缀。例如:
s:“abab”
前缀为:“a”,“ab”,“aba”,“abab”
对于每个前缀,我们可以计算它在s中匹配的次数。所以我们可以看到前缀“a”匹配两次,“ab”匹配两次,“aba”匹配一次,“abab”匹配一次。现在要求您计算所有前缀的匹配时间总和。对于“abab”,它是2 + 2 + 1 + 1 = 6.
答案可能非常大,因此输出答案mod 10007。
输入
第一行是单个整数T,表示测试用例的数量。
对于每种情况,第一行是整数n(1 <= n <= 200000),这是字符串s的长度。给出字符串s之后的一行。字符串中的字符都是小写字母。
产量
对于每种情况,只输出一个数字:s mod 10007的所有前缀的匹配时间总和。
样本输入
1
4
ABAB
样本输出
6
假设两串字符完全相等,next[j]=i,代表s[1...i]==sum[j-i+1....j],这一段其实就是前缀
i~j之间已经不可能有以 j 结尾的子串是前缀了,不然next[j]就不是 i 了
设dp[i]:以string[i]结尾的子串总共含前缀的数量
所以dp[j]=dp[i]+1,即以i结尾的子串中含前缀的数量加上前j个字符这一前缀
import java.util.Scanner;
public class hdu3336 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int t = in.nextInt();
long ans;
while(t-->0) {
n = in.nextInt();
next = new int[n+1];
dp = new int[n+1];
next[0] = -1;
ans = 0;
s = in.next().toCharArray();
getnext();
for(int i=1;i<=n;i++)
dp[i] = 1;
for(int i=1;i<=n;i++) {
dp[i] = dp[next[i]]+1;
ans += dp[i];
ans %= 10007;
}
// for(int i=0;i<=n;i++)
// System.out.print(dp[i]+" ");
// System.out.println();
// for(int i=0;i<=n;i++)
// System.out.print(next[i]+" ");
// System.out.println();
System.out.println(ans);
}
}
static char[] s;
static int n;
static int[] next;
static int[] dp;
static void getnext(){
int j=0,k=-1;
while(jhdu3746
KMP:补齐循环节
问题描述
CC总是在本月底变得非常沮丧,昨天他已经检查了他的信用卡,没有任何意外,只剩下99.9元。他太苦恼了,想着如何度过最后的日子。受到“HDU CakeMan”的企业家精神的启发,他想出售一些小东西来赚钱。当然,这不是一件容易的事。
由于圣诞节即将来临,男孩们正在忙着选择圣诞礼物送给他们的女朋友。据信链式手链是一个不错的选择。然而,事情并不总是如此简单,众所周知,女孩喜欢色彩缤纷的装饰,使手镯显得生动活泼,同时他们希望展现自己成熟的大学生一面。在CC了解女孩的要求之后,他打算出售名为CharmBracelet的链式手链。CharmBracelet由彩色珍珠组成,以展现女孩的活泼,最重要的是它必须通过循环链连接,这意味着珍珠的颜色从左到右循环连接。并且循环计数必须不止一个。如果连接最左边的珍珠和这种链的最右边的珍珠,你可以制作一个CharmBracelet。就像下面的pictrue一样,这个CharmBracelet的循环是9,它的循环计数是2:

现在CC引进了一些普通的手链,他想购买最少数量的珍珠来制作CharmBracelets以便他可以节省更多的钱。但是当重新制作手镯时,他只能在链的左端和右端添加彩色珍珠,也就是说,禁止添加到中间。
CC对他的想法感到满意并请求您的帮助。
输入
输入的第一行是单个整数T(0
输出
对于每种情况,您都需要输出为制作CharmBracelet而添加的珍珠的最小数量。
样本输入
3
aaa
abca
abcde
样本输出
0
2
5
题意:
给你一个串,要你在串头或尾添加最少的字符,使得该串至少有2个循环节,问你最少需要加几个字符.
分析:
首先要明白:如果一个串需要至少添加x(x>=0)个字符才能是有>=2个循环节的串,那么我可以只在串末尾添加,不需要去串头添加.(比如串cabc,循环节是abc,我可以在尾部添加ab即可.)
首先如果原始串已经有至少两个循环节就不必添加.当f[m]>0&&m%(m-f[m])==0时,不必添加.(结合之前的KMP循环节题目看看是不是这样.)
现在假设条件 f[m]>0&&m%(m-f[m])==0 不成立的时候呢?
重要结论:不论串S是不是循环的,如果想要S是一个循环串的话,那么它的最小循环节长度一定是len-f[len]. 其中len是串S的长度.
即不论S是不完整的循环串还是完整的循环串,len-f[len]一定是串S中去除末尾残缺部分之后,存在的最小循环节长度.现在来例证一下:
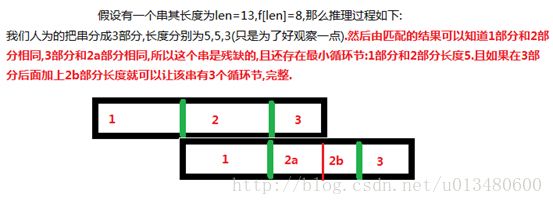

假设f[len]=0,那么是不是该串完全没有由部分子串构成最小循环节呢?是的.
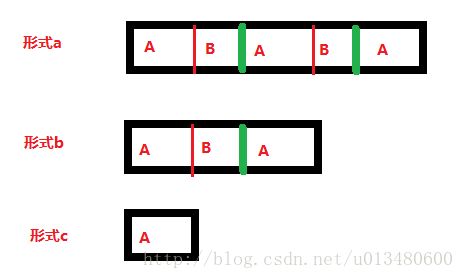
只要一个串是上面的形式a或b,那么就不可能f[len]=0.
只要f[len]=0 (类似上面的形式c),那么它一定是单独成循环节,需要添加len个字符.原文链接
一模一样的java代码在hduoj过不了,查了下,也没有人能用java代码通过,都是吃WA,应该是oj问题
#include
#include
using namespace std;
char s[100005];
int next[100005];
int n,t;
void getnext(){
int j=0,k=-1;
while(j
leetcode 459. 重复的子字符串
kmp求循环节
class Solution {
static char[] p;
static int[] next;
static int n;
public static boolean repeatedSubstringPattern(String s) {
if(s=="" || s.length()<=1)
return false;
n = s.length();
p = s.toCharArray();
next = new int[n+1];
next[0]=-1;
int j=0,k=-1;
while(j
poj2406
模板题,KMP求最小循环节
描述
给定两个字符串a和b,我们将* b定义为它们的串联。例如,如果a =“abc”而b =“def”则a * b =“abcdef”。如果我们将连接视为乘法,则以正常方式定义非负整数的取幂:a ^ 0 =“”(空字符串)和^(n + 1)= a *(a ^ n)。
输入
每个测试用例都是一行输入,表示s,一串可打印的字符。s的长度至少为1,不超过1百万个字符。包含句点的行在最后一个测试用例之后。
产量
对于每个s,您应该打印最大的n,使得某些字符串a的s = a ^ n。
样本输入
abcd
aaaa
ababab
.
样本输出
1
4
3n%j==0这个判断很重要哦
import java.util.Scanner;
public class poj2406 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
while(true) {
String str = in.next();
if(str.equals("."))
break;
s = str.toCharArray();
n = s.length;
next = new int[n+1];
next[0]=-1;
getnext();
int j = n - next[n];
System.out.println(n%j==0?n/j:1);
}
}
static char[] s;
static int[] next;
static int n;
static void getnext() {
int j=0,k=-1;
while(jpoj2752
描述
这只小猫非常有名,许多夫妇在山丘和山谷上跋涉到Byteland,并要求小猫为他们新生的婴儿命名。他们寻求这个名字,同时寻求名声。为了摆脱这种无聊的工作,创新的小猫制定了一个简单而奇妙的算法:
Step1。将父亲的名字和母亲的名字连接到一个新的字符串S.
Step2。找到一个正确的前缀后缀字符串S(它不仅是前缀,而且是S的后缀)。
示例:父='ala',母亲='la',我们有S ='ala'+'la'='alala'。S的潜在前缀后缀字符串是{'a','ala','alala'}。给定字符串S,你能帮助小猫编写一个程序来计算S的可能前缀后缀字符串的长度吗?(他可能会给你的宝宝起一个名字来感谢你:)
输入
输入包含许多测试用例。每个测试用例占用包含上述字符串S的单行。
限制:输入中只能出现小写字母。1 <= S的长度<= 400000。
产量
对于每个测试用例,以递增的顺序输出一行整数,表示新宝宝名称的可能长度。
样本输入
ababcababababcabab
aaaaa
样本输出
2 4 9 18
1 2 3 4 5本题题意为求出所有在后缀中出现过的前缀的最后一个元素的下标
本题要考虑一下next数组的本质,其实就是最长的出现在后缀中的前缀,但是由于本题要求所有的而不是最长的,考虑到next数组的递归过程,其实就是对每一个当前长度的前缀,都有完全相同的后缀与之对应,所以就不断递归next数组即可求解。
import java.util.Scanner;
public class poj2752 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
while(in.hasNext()) {
s = in.next().toCharArray();
n = s.length;
next = new int[n+1];
ans = new int[n+1];
next[0]=-1;
getnext();
int j = n;
int cnt = 0;
while(j!=0) {
ans[cnt++] = j;
j = next[j];
}
for(int i=cnt-1;i>=0;i--)
if(i!=0)
System.out.print(ans[i]+" ");
else
System.out.println(ans[i]);
}
}
static char[] s;
static int[] next;
static int[] ans;
static int n;
static void getnext() {
int j=0,k=-1;
while(j