sql server 面试题
- 查询两张表相同的数据
--01
select * from #tb1
intersect
select * from #tb2查询两张表不同的数据
select * from #tb1
except
select * from #tb22、行列转换
create table #pivot_tb
(
p_name nvarchar(20) null,
p_skil nvarchar(20) null,
damages int null
)
----
insert into #pivot_tb
select N'亚瑟' ,N'第一技能',200
union all
select N'亚瑟' ,N'第二技能',500
union all
select N'亚瑟',N'第三技能',700
union all
select N'百里守约',N'第一技能',0
union all
select N'百里守约',N'第二技能',1200
union all
select N'妲己',N'第三技能',600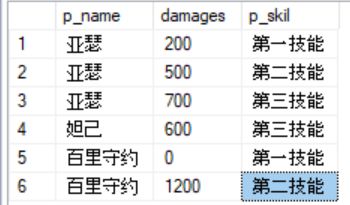
----行转列
select p_name,
sum(case when p_skil = N'第一技能' then damages else 0 end )as 第一技能,
sum(case when p_skil = N'第二技能' then damages else 0 end )as 第二技能,
sum(case when p_skil = N'第三技能' then damages else 0 end )as 第三技能
from #pivot_tb
group by p_name
---pivot
select p_name
,[第一技能],[第二技能],[第三技能] -- into #Zbz
from #pivot_tb
pivot (
sum (damages) for p_skil in( [第一技能],[第二技能],[第三技能])
)
as pt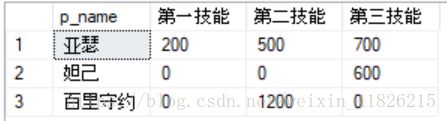
列转行
--- 列转行
select p_name,[第一技能] as damages, N'第一技能' as p_skil from #Zbz where [第一技能] is not null
union all
select p_name,[第二技能] as damages, N'第二技能' as p_skil from #Zbz where [第二技能] is not null
union all
select p_name,[第三技能] as damages, N'第三技能' as p_skil from #Zbz where [第三技能] is not null
--- unpivot
SELECT *
FROM
(SELECT * FROM #Zbz) p
UNPIVOT
(damages FOR p_skil IN
([第一技能],[第二技能],[第三技能])
)AS unpvt;
GO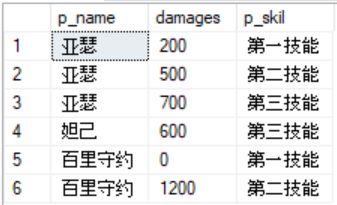
3、drop ,delete ,truncate 区别
drop
隐式提交,不能回滚,
删除表结构及所有从数据,将表所占空间全部释放。
删除表的结构所依赖的约束,触发器,索引,依赖于该表的存储过程/函数将保 留,但是变为invalid状态。
delete
逐行删除,并且同时将该行的的删除操作记录在redo和undo表空间中以便进行回滚(rollback)和重做操作。
truncate
删除所有数据,TRUNCATE不记录日志 , 表结构及其列、约束、索引等保持不变。
4、select 1 ,count(1)
select 1 from table 增加临时列,每行的列值是写在select后的数,这条sql语句中是1
count(1) 表的行数
5、exists
1.子查询与外表的字段有关系时
select 字段1 , 字段2 from 表1 where exists (select 字段1 , 字段2 from 表2 where 表2.字段2 = 表1.字段2)
这时候,此SQL语句相当于一个关联查询。
它先执行表1的查询,然后把表1中的每一条记录放到表2的条件中去查询,如果存在,则显示此条记录
2.子查询与外表的字段没有任何关联
Select 字段1 , 字段2 from 表1 where exists ( select * from 表2 where 表2.字段 = ‘ 条件‘)
在这种情况下,只要子查询的条件成立,就会查询出表1中的所有记录,反之,如果子查询中没有查询到记录,则表1不会查询出任何的记录。
当子查询与主表不存在关联关系时,简单认为只要exists为一个条件判断,如果为true,就输出所有记录。如果为false则不输出任何的记录。
6、exists与in
in是在内存里遍历比较,而exists需要查询数据库,所以当B表数据量较大时,exists效率优于in。
exists()会执行A.length次,它并不缓存exists()结果集,因为exists()结果集的内容并不重要,重要的是其内查询语句的结果集空或者非空,空则返回false,非空则返回true。
外表大,用IN;内表大,用EXISTS
not in 和not exists
如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;
而not extsts 的子查询依然能用到表上的索引。
所以无论那个表大,用not exists都比not in要快。
7、on 与 where
on条件是在生成临时表时使用的条件
where条件是在临时表生成好后,再对临时表进行过滤的条件
on后的条件用来生成左右表关联的临时表,where后的条件对临时表中的记录进行过滤。
8、WHERE、HAVING和ON的比较
WHERE和HAVING关键字都可以对查询结果进行筛选,两者的区别是WHERE的作用时间是在计算之前就完成的,而having是在计算后才起作用的。HAVING只会在检索出所有记录之后才对结果集进行过滤
ON关键字实际上也是对数据进行筛选,只不过是在多表关联时使用。需要注意的是,在我们常用的操作中,表关联是最耗时的操作之一。尤其是两张大表的关联
9、优化修改删除语句
如果你同时修改或删除过多数据,会造成cpu利用率过高从而影响别人对数据库的访问。
如果你删除或修改过多数据,采用单一循环操作,那么会是效率很低,也就是操作时间过程会很漫长。
delete tb where id<1
delete tb where id>=1 and id<2
delete tb where id>=2 and id<3