Python--文件操作及复制和抓取的简单实现
一,冯诺依曼体系架构

CPU由运算器和控制器组成:
运算器:完成各种算数运算,逻辑运算,数据传输等数据加工处理
控制器:控制程序的执行
储存器:用于记忆程序和数据,如内存
输入设备:将数据或程序输入到计算机中,如键盘,鼠标
输出设备:将数据或程序处理的结果展示给用户,例如显示器和打印机
一般说IO操作,指的是文件IO,若是网络IO都会直接说网络IO
二,文件IO常用操作:
open 打开
read 读取
write 写入
close 关闭
readline 行读取
readlines 多行读取
seek 文件指针操作
tell 指针位置
1) open (file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
打开一个文件,返回一个文件对象(流对象)和文件描述符.打开文件失败,则返回异常
基本使用: 创建一个文件test,然后打开它,用完关闭
f = open('test') #file对象
#windows<_io.TextIOWrapper name='test' mode='r' encoding= 'cp936'>
#linux <_io_TextIOWrapper name='test' mode='r' encoding='utf-8'>
print(f.read()) #读取文件
f.close() #关闭文件
文件操作中,最常用的操作就是读和写.
文件访问的模式有两种:文本模式和二进制模式.不同模式下,操作函数不尽相同,表现的结果也不尽一样.
2) open的参数
file
打开或者要创建的文件名.如果不指定路径,默认就是当前路径.
***mode模式
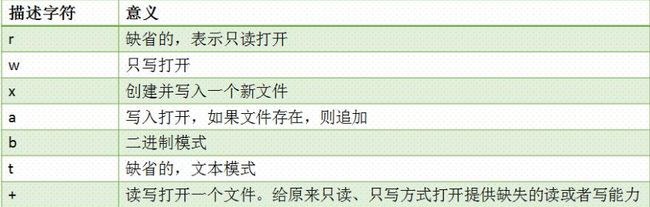
由上可知,默认是文本打开模式,并且是只读的.
1) r
只读打开文件,如果使用write方法,会抛出异常
若文件不存在,抛出FileFoundError异常
2) w
表示只写方式打开,若读取则抛出异常
若文件不存在,则直接创建文件
若文件存在,则清空文件内容
3) x
文件不存在的化则创建文件且打开方式为只写
文件存在则抛出FileExistsError异常
4) 总结: r是制度,wxa都是只写
wxa都可以产生新文件,w不管文件存在与否,都会产生全新内容的文件;a不管文件是否存在,都能打开文件的尾部进行追加;x必须要文件事先不存在,自己创造一个新文件.
5) 文本模式t
字符流,将文件的字节按照某种字符编码理解,按照字符操作.open的默认mode就是rt.
6) 二进制模式b
字节流,将文件就按照字节理解,与字符编码无关.二进制模式操作时,字节操作使用bytes类型
7) +
为r,x,w,a提供确实的读写功能,但是,获取文件对象依旧按照r,x,w,a自己的特征.+不可以单独使用,可以认为它是为前面的模式字符做增强功能的.
3) 文件指针
mode = r , 指针起始在0
mode = a, 指针起始在EOF
tell()显示指针当前位置
seek(offset[,whence]): 移动文件指针位置.offset表示偏移多少字节,whence表示从哪里开始.
文本模式下:
whence 缺省值为0,表示从头开始,offset只能接受正整数
whence 1表示从当前位置,offset只接受0
whence 2表示从EOF开始,offset只接受0
二进制模式下:
whence 缺省值为0,表示从头开始,offset只能正整数
whence 1表示从当前位置,offset可正可负
whence 2表示从EOF开始,offset可正可负
二进制模式支持任意起点的偏移,从头,从尾,从中间,都可以;
向后seek可以超界,但是向前seek的时候不能超界,否则抛异常.
4) buffering: 缓冲区
-1表示使用缺省大小的buffer.如果是二进制模式,使用io.DEFAULT_BUFFER_SIZE值,默认是4096或8192.若是文本模式,若是终端设备,是行缓存方式,若不是,则使用二进制模式的策略.
0只在二进制模式中使用,表示关buffer
1只在文本模式中使用,表示使用行缓冲,意思就是见到换行符就flusn
大于1用于指定buffer的大小
buffer缓冲区:
缓冲区是一个内存空间,一般来说是一个FIFO队列,到缓冲区满了或者达到阈值数据才会flush到磁盘.
flush()将缓冲区数据写入磁盘
close()关闭前会调用flush()
io.DEFAULT_BUFFER_SIZE缺省缓冲区大小,字节
二进制模式:

文本模式:

buffering = 0:
这是一种特殊的二进制模式,不需要内存的buffer,可以看作是一个FIFO的文件.

Buffering Instrution:

简化记忆:
1.文本模式,一般都用默认缓冲区大小
2.二进制模式,是一个个字节的操作,可以指定buffer的大小
3.一般来说,默认缓冲区大小是个比较好的选择,除非明确知道,否则不改动它
4.一般编程中,明确知道需要写磁盘了,都会手动调用一次flush,而不是等到自动flush或者close的时候.
encoding : 编码,仅文本模式使用
None 表示使用缺省编码,依赖操作系统.
windows下缺省GBK(0xB0A1),Linux下缺省UTF-8(0xE5 95 8A)
其他参数
errors
什么样的编码错误将被捕获
None和strict表示有编码错误,将抛出ValueError异常,ignore表示忽略
newline
文本模式中,换行的转换.可以为None,'空串','\r','\r\n','\n'
读时,None表示'\r','\r\n','\n'都被转换位'\n' ; '表示不会自动转换通用换行符;其它合法字符表示换行符就是指定字符,就会按照指定字符分行
写时,None表示'\n'都会被替换为系统缺省行分隔符os.linesp ; '\n'或 " 表示'\n'不替换;其它合法字符表示'\n'会被替换为指定的字符
f = open('d:/test1','w')
f.write('python\rwww.python.com\nwww.magedu.com\r\npython3')
f.close()
newlines = [None,'','\n','\r\n']
for nl in newlines:
f = open('d:/test1','r+',newline=nl)
print(f.readlines())
f.close()closefd
关闭文件描述符,True表示关闭它.False会在文件关闭后保持这个描述符. --fileobj.fileno()查看
read
read(size=-1)
size表示读取的多少个字符或者字节;负数或者None表示读取到EOF
f = open('d:/test1','r+')
f.write('lalalala')
f.write('\n')
f.write('PHP才是最好的语言')
f.seek(0)
print(f.read(12))
f.close()#二进制模式
f = open('d:/test1','rb+')
print(f.read(5))
print(f.read(1))
f.close()行读取
readline(size=-1)
一行行读取文件内容.size设置一次能读取行内几个字符或字节.
readlines(hint=-1)
读取所有行的列表.指定hint则返回指定的行数.
#按行迭代
f = open('test') #返回可迭代对象
for line in f:
print(line)
f.closewrite
write(s), 把字符串s写入到文件中并返回字符的个数.
writelines(lines), 将字符串列表写入文件.
f = open('test','w+')
lines = ['abc','123\n','Python'] #提供换行符
f.writelines(lines)
f.seek(0)
print(f.read())
f.close()close
flush并关闭文件对象.
文件已关闭再次关闭没有任何效果
其他
seekable()是否可seek
readable()是否可读
writable()是否可写
closed是否已经关闭
上下文管理
问题的引出
在Linux中,执行
#下面必须这么写
lst = []
for _ in range(2000):
lst.append(open('test'))
#OSError : [Error 24] Too many open files: 'test'
print(len(lst))lsof 列出打开的文件,没有就#yum install lsof
$ lsof -p 1427 |grep test |wc -l
lsof -p 进程号
ulimit -a 查看所有限制. 其中open files就是打开文件数的限制,默认1024
for x in lst:
x.close()将文件依次关闭,然后就可以继续打开了.再看一次lsof
如何解决此问题?
1. 异常处理
当出现异常的时候,拦截异常.但是,因为很多代码都可能出现OSError异常,还不好判断异常就是因为资源限制产生的.
f = open('test')
try:
f.write('abc') #文件只读,写入失败
finally:
f.close() #需要关闭使用finally可以保证打开的文件可以被关闭.
2.上下文管理
一种特殊的语法,交给解释器去释放文件对象.
上下文管理:
del f
with open('test') as f:
f.write('abc') #文件只读 写入失败
# 测试f是否关闭
f.closed #f的作用域上下文管理:
1.使用with...as关键字
2.上下文管理的语句块并不会开启新的作用域
3.with语句块执行完的时候,会自动关闭文件对象
另一种写法:
f1 = open('test')
with f1:
f1.write('abc')
# 测试f是否关闭
f1.closed #f1的作用域
对于类似于文件对象的IO对象,一般来说都需要在不使用的时候关闭,注销,以释放资源.
IO被打开的时候,会获得一个文件描述符.计算机的资源是有限的,所以操作系统都会做限制.就是为了保护计算机的资源不要被完全耗尽,计算资源是共享的,不是独占的.
一般情况下,除非特别明确知道资源情况,否则不要提高资源的限制值来解决问题.
一,指定一个源文件,实现copy到目标目录.
例如把/tmp/test.txt拷贝到/tmp/test1.txt
filename1 = '/tmp/test.txt'
filename2 = '/tmp/test1.txt'
f = open('filename1','w+')
lines = ['C and Java which is better?','PHP!!!','PHP is the best language!!!']
f.writelines('\n'.join(lines))
f.seek(0)
print(f.read())
f.close()
def cp(src,dest):
with open(src) as f1:
with open(dest,'w') as f2:
f2.write(f1.read())
cp('filename1','filename2')
c = open('filename2','r')
c.seek(0)
c.readlines()二,有一个文件,对其进行单词统计,不区分大小写,统计出重复最多的10个单词:
(我们把help文档复制了下来,保存在了sample中,以sample为例)
1)这只是一个初步的解法:
d = {}
with open('d:/sample.txt',encoding='utf-8') as f1:
for line in f1:
words = line.split()
for word in map(str.lower,words):
d[word] = d.get(word,0) + 1
sorted(d.items(),key = lambda item:item[1],reverse = True)[:10]思考:如何把包含特殊字符的需要的单词统计出来呢?
2)接上面代码,我们发现其实例如说path,它还有好多个没被统计出来,例如os.path.basename(path)中就可以看作有两个path.
count = 0
for k in d.keys():
if k.find('path') > -1:
count += 1
print(k)
print(count)方法一:
def makekey(s:str):
chars = set(r"""!'"#./\()[],*-""")
key = s.lower()
ret = []
for i,c in enumerate(key):
if c in chars:
ret.append(' ')
else:
ret.append(c)
return ''.join(ret).split()
d = {}
with open('d:/sample.txt',encoding = 'utf-8') as f:
for lines in f:
words = lines.split()
for wordlist in map(makekey,words):
for word in wordlist:
d[word] = d.get(word,0) + 1
for k,v in sorted(d.items(),key = lambda item:item[1],reverse=True)[:10]:
print(k,v)方法二:
def makekey(s:str):
chars = set(r"""!'"#./\()[],*-""")
key = s.lower()
ret = []
start = 0
length = len(key)
for i,c in enumerate(key):
if c in chars:
if start == i: #如果紧挨着还是特殊字符,start==i
start += 1 # 加1 继续 看是否还挨着特殊字符
continue
ret.append(key[start:i])
start = i + 1 #跳过这个不需要的字符
else:
if start方法三:
def word_count(filename,encode='utf8',sp = None):
import collections
result = collections.defaultdict(int)
wordlen = 0
flag = False
#if sp is None:
# 可设置一个特殊符号集 specialcharacters
with open(filename,'r',encoding = encode ) as f:
for line in f:
for i in range(len(line)):
if line[i].isalpha():#if i not in specialcharacters:
flag = True
wordlen += 1
elif flag == True and not line[i].isalpha():# flag = True and i in specialcharacters
flag = False
word = line[i-wordlen:i].lower()
result[word] += 1
wordlen = 0
return result
result_count = word_count('sample.txt')
#print('\n'.join(map(str,sorted(result_count.items(),key = lambda item:item[1], reverse = True)[:10])))
for k,v in sorted(result_count.items(),key = lambda item:item[1], reverse = True)[:10]:
print('{:<4} : {:>3}'.format(k,v))