【汇总】pytorch里的一些函数
view()
https://blog.csdn.net/york1996/article/details/81949843
参数不可为空。参数中的-1就代表这个位置由其他位置的数字来推断,只要在不致歧义的情况的下,view参数就可以推断出来,也就是人可以推断出形状的情况下,view函数也可以推断出来。比如a tensor的数据个数是6个,如果view(1,-1),我们就可以根据tensor的元素个数推断出-1代表6。
生成随机数Tensor的方法
torch.randn()
torch.randn()是从标准正态分布中抽样。返回一个张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量的形状由参数sizes定义。
torch.randn(*sizes, out=None)
参数:
-
sizes (int…) - 整数序列,定义了输出张量的形状
-
out (Tensor, optinal) - 结果张量
torch.rand()
torch.rand()是从0-1的均匀分布中抽样,返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数。张量的形状由参数sizes定义。
*torch.rand(sizes, out=None)
参数:
- sizes (int…) - 整数序列,定义了输出张量的形状
- out (Tensor, optinal) - 结果张量
torch.normal()
返回一个张量,包含了从指定均值means和标准差std的离散正态分布中抽取的一组随机数。
标准差std是一个张量,包含每个输出元素相关的正态分布标准差。
torch.normal(means, std, out=None)
参数:
- means (float, optional) - 均值
- std (Tensor) - 标准差
- out (Tensor) - 输出张量
torch.linespace()
返回一个1维张量,包含在区间start和end上均匀间隔的step个点。
输出张量的长度由steps决定。
torch.linspace(start, end, steps=100, out=None)
参数:
- start (float) - 区间的起始点
- end (float) - 区间的终点
- steps (int) - 在start和end间生成的样本数
- out (Tensor, optional) - 结果张量
torch.cat()
https://duanyc.top/2020/02/16/pytorch-torch-cat/
torch.stack()
https://blog.csdn.net/Teeyohuang/article/details/80362756
-
例子:
c, dim = 0时, c = [ a, b]
d, dim =1 时, d = [ [a[0] , b[0] ] , [a[1], b[1] ] ]
e, dim = 2 时, e = [ **[ ** [ a[0] [0], b[0] [0] ], [ a[0] [1], b[0] [1] ], [ a[0] [2],b[0] [2] ] ] ,
[ [ a[1] [0], b[1] [0] ] , [ a[1] [1], b[0] [1] ], [ a[1] [2],b[1] [2] ] ] ]
-
解释1:新增的那一维位置,如果dim=0,则新增的维度为第一维,第一维就是原来的三个tensor拼接而成。而第二维、第三维则是原来三个tensor的继承。以次类推dim为1和2的情况。
-
解释2:从最外层往里剥开,看是哪一维度
torch.nn.BatchNorm1d()
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True)
对小批量(mini-batch)的2d或3d输入进行批标准化(Batch Normalization)操作
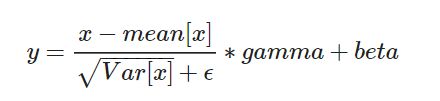
在每一个小批量(mini-batch)数据中,计算输入各个维度的均值和标准差。gamma与beta是可学习的大小为C的参数向量(C为输入大小)
在训练时,该层计算每次输入的均值与方差,并进行移动平均。移动平均默认的动量值为0.1。
在验证时,训练求得的均值/方差将用于标准化验证数据。
参数:
- num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
- eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
- momentum: 动态均值和动态方差所使用的动量。默认为0.1。
- affine: 一个布尔值,当设为true,给该层添加可学习的仿射变换参数。
Shape: - 输入:(N, C)或者(N, C, L) - 输出:(N, C)或者(N,C,L)(输入输出相同)
例子
>>> # With Learnable Parameters
>>> m = nn.BatchNorm1d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm1d(100, affine=False)
>>> input = autograd.Variable(torch.randn(20, 100))
>>> output = m(input)
torch.nn.BatchNorm2d()
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)
对小批量(mini-batch)3d数据组成的4d输入进行批标准化(Batch Normalization)操作
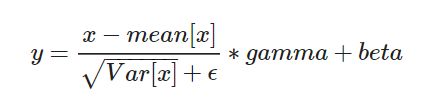
在每一个小批量(mini-batch)数据中,计算输入各个维度的均值和标准差。gamma与beta是可学习的大小为C的参数向量(C为输入大小)
在训练时,该层计算每次输入的均值与方差,并进行移动平均。移动平均默认的动量值为0.1。
在验证时,训练求得的均值/方差将用于标准化验证数据。
参数:
- num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features x height x width’
- eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
- momentum: 动态均值和动态方差所使用的动量。默认为0.1。
- affine: 一个布尔值,当设为true,给该层添加可学习的仿射变换参数。
Shape: - 输入:(N, C,H, W) - 输出:(N, C, H, W)(输入输出相同)
例子
>>> # With Learnable Parameters
>>> m = nn.BatchNorm2d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm2d(100, affine=False)
>>> input = autograd.Variable(torch.randn(20, 100, 35, 45))
>>> output = m(input)