python爬虫:使用scrapy框架抓取360超清壁纸(10W+超清壁纸等你来爬)
目的:闲着无聊,利用爬虫爬取360超清壁纸,并将其数据存储至MongoDB/MySQL中,将图片下载至指定文件夹。
要求:确保以安装MongoDB或者MySQL数据库、scrapy框架也肯定必须有的;使用python环境:python3.5;且使用的是Chrome浏览器。
1.网站抓取前期分析
首先,进行数据抓取网站的分析,这里将要抓取的网站为['http://image.so.com/'],进入首页,进入壁纸专区,美图太多别急着看……,打开chrome的开发者工具,开始进行分析。
结果可以看的出:该网站image.so.com使用的是经过Ajax技术处理,后期js渲染而后呈现出的网页,直接请求网站image.so.com后得不到任何有用的数据(见图1,图2);所以对于Ajax请求直接将开发者工具的过滤器切换到XHR选项(XHR得到的是Ajax信息)鼠标滚动几次,就会看到这里出现了很多Ajax请求信息。如下图所示:
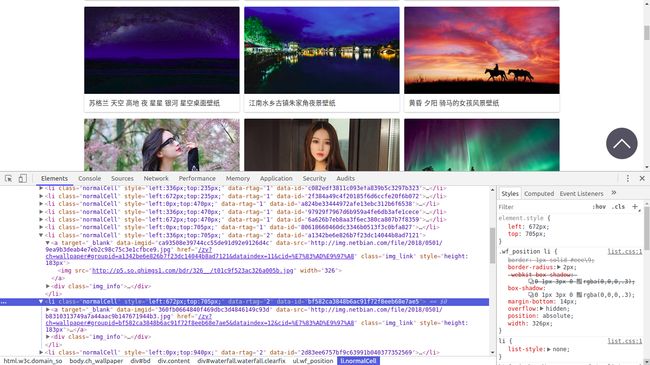
图一 elements上可以看到很多原始数据信息

图二 Network的z?ch=wallpaper的response内与图一信息完全不一样,即网页经过js渲染
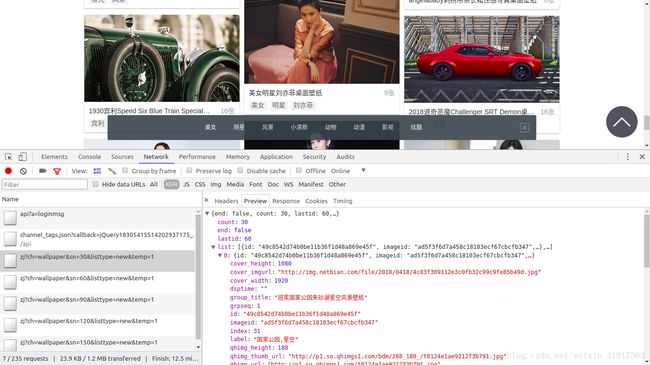
图三 XHR上的请求列表
可以看到图三有很多的请求详情,点开zj?ch=wallpaper&sn=30&listtype=new&temp=1,进入Preview,点击list并打开任意一个list(如list1),会发现里面有过很多参数信息,如id、index、url、group_title等。
其实上面所看到的都是JSON文件,每一个list字段(应该都是30个图片),里面包含的是网页上图片的所有信息,并且发现url的规律,当sn=30的时候返回的是0-30张图,当sn=60的时候返回的是30-60张图片。此外ch=什么就代表什么(此处ch=wallpaper),其他的不用管,可有可无。
下面开始用scrapy实现图片信息的mongo或者mysql存储,并且下载相应的图片信息。
2.创建images项目,并实现程序可执行,详情见代码:
item模块
from scrapy import Item,Field
class ImagesItem(Item):
collection = table = 'images'
imageid = Field()
group_title = Field()
url = Field()spiders模块
# -*- coding: utf-8 -*-
import json
from urllib.parse import urlencode
from images.items import ImagesItem
from scrapy import Spider, Request
class ImagesSpider(Spider):
name = 'images'
allowed_domains = ['image.so.com']
def start_requests(self):
# 表单数据
data = {
'ch': 'wallpaper',
'listtype': 'new',
't1': 93,
}
# 爬虫起始地址
base_url = 'http://image.so.com/zj?'
# page列表从1到50页循环递归,其中MAX_PAGE为最大页数
for page in range(1, self.settings.get('MAX_PAGE') + 1):
data['sn'] = page*30
params = urlencode(data)
# spider实际爬取的地址是api接口,如http://image.so.com/zj?ch=wallpaper&sn=30&listtype=new&temp=1
url = base_url + params
yield Request(url, self.parse)
def parse(self, response):
# 因response返回的数据为json格式,故json.loads解析
result = json.loads(response.text)
res = result.get('list')
if res:
for image in res:
item = ImagesItem()
item['imageid'] = image.get('imageid')
item['group_title'] = image.get('group_title')
item['url'] = image.get('qhimg_url')
yield itemmiddlewares模块,因该网站有headers反扒限制,故构造RandomUserAgentMiddelware进行随机agents选取。
import random
from images360.user_agents import user_agents
class RandomUserAgentMiddelware(object):
"""
换User-Agent
"""
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(user_agents)user_agents池模块:
""" User-Agents """
user_agents = [
"Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Avant Browser/1.2.789rel1 (http://www.avantbrowser.com)",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5",
"Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-GB; rv:1.9.0.11) Gecko/2009060215 Firefox/3.0.11 (.NET CLR 3.5.30729)",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 GTB5",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; tr; rv:1.9.2.8) Gecko/20100722 Firefox/3.6.8 ( .NET CLR 3.5.30729; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0a2) Gecko/20110622 Firefox/6.0a2",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:7.0.1) Gecko/20100101 Firefox/7.0.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:2.0b4pre) Gecko/20100815 Minefield/4.0b4pre",
"Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0 )",
]pipeline模块:用于将网页上的信息清洗、入库:此处分为MongoPipeline和ImagePipeline
import pymongo
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
# 数据信息存储至 mongo 中
class MongoPipeline(object):
def __init__(self,mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB'),
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
self.db[item.collection].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()
# 下载图片
class ImagePipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
url = request.url
file_name = url.split('/')[-1]
return file_name
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem('Image Downloaded Failed')
return item
def get_media_requests(self, item, info):
yield Request(item['url'])最后进行settings设置:重要的一个环节:
BOT_NAME = 'images'
SPIDER_MODULES = ['images.spiders']
NEWSPIDER_MODULE = 'images.spiders'
# 抓取最大页数
MAX_PAGE = 50
# MONGO信息设置
MONGO_URI = 'localhost'
MONGO_DB = 'images'
# 图片下载路径
IMAGES_STORE = './image1'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 2
# The download delay setting will honor only one of:
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'images.middlewares.RandomUserAgentMiddelware': 543,
}
ITEM_PIPELINES = {
'images.pipelines.ImagePipeline': 300,
'images.pipelines.MongoPipeline': 301,
}代码到此就结束了,开始跑吧:不一会儿数据库、文件夹的图片就会呈现出来

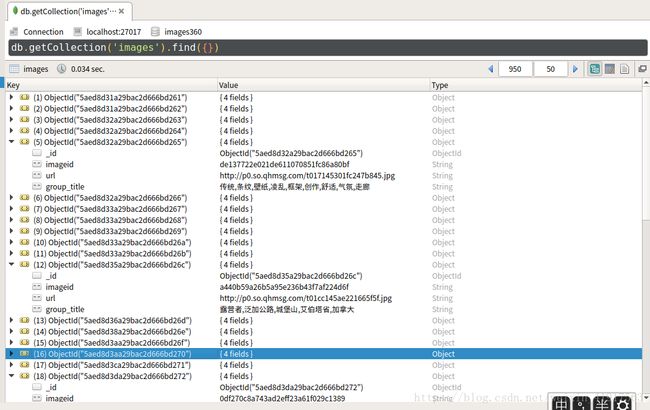
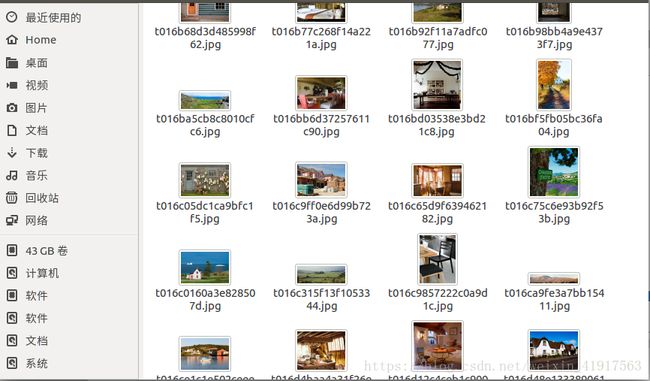
ok,壁纸爬虫利器大功告成!
注:如代码若有不懂之处可以关注博主微信公众号私信于我:Coder的修炼 ,看到我会及时处理回复,thanks!