Proximal Policy Optimization(PPO 近似策略优化)---李宏毅课堂笔记

on-policy vs off-policy
on-policy :此agent与environment互动的agent是同一个,简单来说就是你自己玩王者荣耀,然后不断地从失败中吸取教训,最后越玩越好。Policy Gradigent就是on-policy。
off-policy:此agent与environment互动的agent不是同一个,比如就像你看游戏博主教你玩王者荣耀,告诉你各种技巧,然后你从直播中学习,最后提高技能。我们本文中提到的PPO是off-policy。
在Policy Gradigent中我们知道 ∇ R ‾ θ = E τ − p θ ( τ ) [ R ( τ ) ∇ log p θ ( τ ) ] \nabla \overline{R}_\theta = {E_{\tau \,-\, p_{\theta(\tau)}}}[R(\tau)\nabla\log p_{\theta}(\tau)] ∇Rθ=Eτ−pθ(τ)[R(τ)∇logpθ(τ)] 在policy gradigent中 θ \theta θ更新的话,我们采样的数据也会更新。就像我们每次输的时候都会掉级,嘿嘿,我有一天下午从白金掉到了黄铜。
我们想要的是用 π θ ′ \pi_{{\theta}^\prime} πθ′采样数据来训练 θ \theta θ,当 θ ′ {\theta}^\prime θ′更新时我们可以重复用采样数据,就像我们可以不停的看视频来学习提高技巧,不需要掉级。
重要采样
E x − p [ f ( x ) ] = 1 N ∑ i = 1 N f ( x i ) E_{x \,-\,p}[f(x)]=\frac{1}{N} \sum_{i=1}^Nf(x^{i}) Ex−p[f(x)]=N1∑i=1Nf(xi) 此公式是说从 p ( x ) p(x) p(x)取 N N N个样本,但是如果此 x i x^i xi并不是在 p ( x ) p(x) p(x)中而是在 q ( x ) q(x) q(x)中因为:
E x − p [ f ( x ) ] = ∫ f ( x ) p ( x ) d x E_{x \,-\,p}[f(x)]=\int{f(x)p(x)}dx Ex−p[f(x)]=∫f(x)p(x)dx
且
∫ f ( x ) p ( x ) d x = ∫ f ( x ) p ( x ) q ( x ) q ( x ) d x = E x − q [ p ( x ) q ( x ) f ( x ) ] \int{f(x)p(x)}dx=\int{f(x)\frac{p(x)}{q(x)} q(x)}dx=E_{x \,-\,q}[\frac{p(x)}{q(x)}f(x)] ∫f(x)p(x)dx=∫f(x)q(x)p(x)q(x)dx=Ex−q[q(x)p(x)f(x)]
此时
E x − p [ f ( x ) ] = E x − q [ p ( x ) q ( x ) f ( x ) ] E_{x \,-\,p}[f(x)]=E_{x \,-\,q}[\frac{p(x)}{q(x)}f(x)] Ex−p[f(x)]=Ex−q[q(x)p(x)f(x)]
那么我们在想 V a r x − p [ f ( x ) ] Var_{x \,-\,p}[f(x)] Varx−p[f(x)] 与 V a r x − q [ f ( x ) ] Var_{x \,-\,q}[f(x)] Varx−q[f(x)]一样吗?
答案是否定的,那么何时他们的方差也相等呢?
首先我们可以知道
V a r [ x ] = E [ f ( x ) 2 ] − [ E f ( x ) ] 2 Var[x]=E[f(x)^2]-[Ef(x)]^2 Var[x]=E[f(x)2]−[Ef(x)]2
那么我们可以计算出
V a r x − p [ f ( x ) ] = E x − p [ f ( x ) 2 ] − [ E x − p f ( x ) ] 2 Var_{x \,-\,p}[f(x)]=E_{x-p}[f(x)^2]-[E_{x-p}f(x)]^2 Varx−p[f(x)]=Ex−p[f(x)2]−[Ex−pf(x)]2
V a r x − q [ f ( x ) p ( x ) q ( x ) ] = E x − q [ f ( x ) 2 ( p ( x ) q ( x ) ) 2 ] − [ E x − q ( f ( x ) p ( x ) q ( x ) ) ] 2 = ∫ f ( x ) 2 ( p ( x ) q ( x ) ) 2 q ( x ) d x − [ E x − p f ( x ) ] 2 = ∫ f ( x ) 2 p ( x ) q ( x ) p ( x ) d x − [ E x − p f ( x ) ] 2 = E x − p [ f ( x ) 2 p ( x ) q ( x ) ] − [ E x − p f ( x ) ] 2 Var_{x \,-\,q}[f(x)\frac{p(x)}{q(x)}]=E_{x-q}[f(x)^2(\frac{p(x)}{q(x)})^2]-[E_{x-q}(f(x)\frac{p(x)}{q(x)})]^2\\=\int{f(x)^2(\frac{p(x)}{q(x)})^2q(x)dx}-[E_{x-p}f(x)]^2\\=\int{f(x)^2\frac{p(x)}{q(x)}p(x)dx}-[E_{x-p}f(x)]^2\\=E_{x-p}[f(x)^2\frac{p(x)}{q(x)}]-[E_{x-p}f(x)]^2 Varx−q[f(x)q(x)p(x)]=Ex−q[f(x)2(q(x)p(x))2]−[Ex−q(f(x)q(x)p(x))]2=∫f(x)2(q(x)p(x))2q(x)dx−[Ex−pf(x)]2=∫f(x)2q(x)p(x)p(x)dx−[Ex−pf(x)]2=Ex−p[f(x)2q(x)p(x)]−[Ex−pf(x)]2
所以 V a r x − p [ f ( x ) ] − V a r x − q [ f ( x ) p ( x ) q ( x ) ] = E x − p [ f ( x ) 2 ] − E x − p [ f ( x ) 2 p ( x ) q ( x ) ] Var_{x \,-\,p}[f(x)]-Var_{x \,-\,q}[f(x)\frac{p(x)}{q(x)}]=E_{x-p}[f(x)^2]-E_{x-p}[f(x)^2\frac{p(x)}{q(x)}] Varx−p[f(x)]−Varx−q[f(x)q(x)p(x)]=Ex−p[f(x)2]−Ex−p[f(x)2q(x)p(x)],此时若是 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x)越接近,那么它的方差也越接近。
重要采样遇到的问题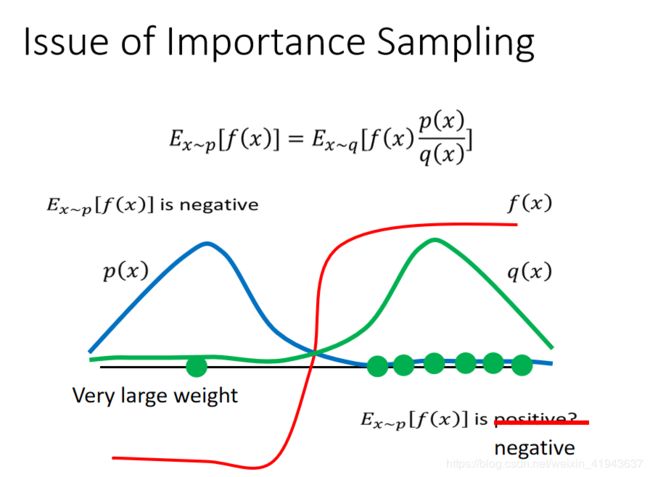
若当我们从q(x)中采样不够多的话,就会遇到如图的情况:如果从q(x)只采样到了右边那四个点,那么 E x − q [ f ( x ) ] E_{x-q}[f(x)] Ex−q[f(x)]是正的,而 E x − p [ f ( x ) ] E_{x-p}[f(x)] Ex−p[f(x)]是负的。若采样足够,假设取到左边的那个点,因为 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x)足够的大, p ( x ) q ( x ) f ( x ) \frac{p(x)}{q(x)}f(x) q(x)p(x)f(x)将是很大的负的,这样就有可能使得 E x − p [ f ( x ) ] = E x − q [ p ( x ) q ( x ) f ( x ) ] E_{x \,-\,p}[f(x)]=E_{x \,-\,q}[\frac{p(x)}{q(x)}f(x)] Ex−p[f(x)]=Ex−q[q(x)p(x)f(x)]
运用重要采样的思想
on-policy :Policy Gradigent中我们知道 ∇ R ‾ θ = E τ − p θ ( τ ) [ R ( τ ) ∇ log p θ ( τ ) ] \nabla \overline{R}_\theta = {E_{\tau \,-\, p_{\theta(\tau)}}}[R(\tau)\nabla\log p_{\theta}(\tau)] ∇Rθ=Eτ−pθ(τ)[R(τ)∇logpθ(τ)]
off-policy:从 θ ′ \theta^{'} θ′中取样,可以用数据训练 θ \theta θ很多次 ∇ R ‾ θ = E τ − p θ ′ ( τ ) [ p θ ( τ ) p θ ′ ( τ ) R ( τ ) ∇ log p θ ( τ ) ] \nabla \overline{R}_\theta = {E_{\tau \,-\, p_{\theta^{'}(\tau)}}}[\frac{p_{\theta(\tau)}}{p_{\theta^{'}(\tau)}}R(\tau)\nabla\log p_{\theta}(\tau)] ∇Rθ=Eτ−pθ′(τ)[pθ′(τ)pθ(τ)R(τ)∇logpθ(τ)]
梯度更新
= E ( s t , a t ) − π θ [ A θ ( s t , a t ) ∇ log p θ ( a t n ∣ s t n ) ] = E ( s t , a t ) − π θ ′ [ p θ ( a t , s t ) p θ ′ ( a t , s t ) A θ ′ ( s t , a t ) ∇ log p θ ( a t n ∣ s t n ) ] = E ( s t , a t ) − π θ ′ [ p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) p θ ( s t ) p θ ′ ( s t ) A θ ′ ( s t , a t ) ∇ log p θ ( a t n ∣ s t n ) ] =E_{(s_t,a_t)-\pi_{\theta}}[A^{\theta}(s_t,a_t)\nabla \log p_{\theta}(a_t^n|s_t^n)]\\=E_{(s_t,a_t)-\pi_{\theta^{'}}}[\frac{p_\theta(a_t,s_t)}{p_\theta^{'}(a_t,s_t)}A^{\theta^{'}}(s_t,a_t)\nabla \log p_{\theta}(a_t^n|s_t^n)]\\=E_{(s_t,a_t)-\pi_{\theta^{'}}}[\frac{p_\theta(a_t|s_t)}{p_\theta^{'}(a_t|s_t)}\frac{p_\theta(s_t)}{p_\theta^{'}(s_t)}A^{\theta^{'}}(s_t,a_t)\nabla \log p_{\theta}(a_t^n|s_t^n)] =E(st,at)−πθ[Aθ(st,at)∇logpθ(atn∣stn)]=E(st,at)−πθ′[pθ′(at,st)pθ(at,st)Aθ′(st,at)∇logpθ(atn∣stn)]=E(st,at)−πθ′[pθ′(at∣st)pθ(at∣st)pθ′(st)pθ(st)Aθ′(st,at)∇logpθ(atn∣stn)]其中 p θ ( s t ) p θ ′ ( s t ) \frac{p_\theta(s_t)}{p_\theta^{'}(s_t)} pθ′(st)pθ(st)可以省略
因为 ∇ f ( x ) = f ( x ) ∇ log f ( x ) \nabla f(x)=f(x)\nabla \log f(x) ∇f(x)=f(x)∇logf(x)
所以我们根据此公式可以得出 ∇ log p θ ( a t n ∣ s t n ) p θ ( a t ∣ s t ) = ∇ p θ ( a t ∣ s t ) \nabla \log p_{\theta}(a_t^n|s_t^n){p_\theta(a_t|s_t)}=\nabla p_\theta(a_t|s_t) ∇logpθ(atn∣stn)pθ(at∣st)=∇pθ(at∣st)
J θ ′ ( θ ) = E ( a t , s t ) − π θ ′ [ p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) A θ ′ ( s t , a t ) ] J^{\theta^{'}}(\theta)=E_{(a_t,s_t)-\pi_{\theta^{'}}}[\frac{p_\theta(a_t|s_t)}{p_\theta^{'}(a_t|s_t)}A^{\theta^{'}}(s_t,a_t)] Jθ′(θ)=E(at,st)−πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]
PPO算法
J P P O θ ′ ( θ ) = J θ ′ ( θ ) − β K L ( θ , θ ′ ) J_{PPO}^{\theta^{'}}(\theta)=J^{\theta^{'}}(\theta)-\beta KL(\theta,\theta^{'}) JPPOθ′(θ)=Jθ′(θ)−βKL(θ,θ′)
- 初始化 θ 0 \theta^{0} θ0
- 优化 J P P O θ k ( θ ) = J θ k ( θ ) − β K L ( θ , θ k ) J_{PPO}^{\theta^{k}}(\theta)=J^{\theta^{k}}(\theta)-\beta KL(\theta,\theta^{k}) JPPOθk(θ)=Jθk(θ)−βKL(θ,θk)
- if K L ( θ , θ k ) > K L m a x KL(\theta,\theta^{k})>KL_{max} KL(θ,θk)>KLmax β \beta β增大,因为KL大的候, θ \theta θ和 θ k \theta^{k} θk之间差距很大,此时增大 β \beta β,增大后面的作用。if K L ( θ , θ k ) < K L m i n KL(\theta,\theta^{k})
PPO2算法
- PPO2算法是PPO算法的改进,比后者更好计算。
- c l i p ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) , 1 − ϵ , 1 + ϵ ) clip(\frac{p_{\theta}(a_t|s_t)}{p_{\theta}^{k}(a_t|s_t)},1-\epsilon,1+ \epsilon) clip(pθk(at∣st)pθ(at∣st),1−ϵ,1+ϵ)的意思是 p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) < 1 − ϵ \frac{p_{\theta}(a_t|s_t)}{p_{\theta}^{k}(a_t|s_t)}<1-\epsilon pθk(at∣st)pθ(at∣st)<1−ϵ时 c l i p ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) , 1 − ϵ , 1 + ϵ ) = 1 − ϵ clip(\frac{p_{\theta}(a_t|s_t)}{p_{\theta}^{k}(a_t|s_t)},1-\epsilon,1+ \epsilon)=1-\epsilon clip(pθk(at∣st)pθ(at∣st),1−ϵ,1+ϵ)=1−ϵ
当 p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) > 1 + ϵ \frac{p_{\theta}(a_t|s_t)}{p_{\theta}^{k}(a_t|s_t)}>1+\epsilon pθk(at∣st)pθ(at∣st)>1+ϵ时 c l i p ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) , 1 − ϵ , 1 + ϵ ) = 1 + ϵ clip(\frac{p_{\theta}(a_t|s_t)}{p_{\theta}^{k}(a_t|s_t)},1-\epsilon,1+ \epsilon)=1+\epsilon clip(pθk(at∣st)pθ(at∣st),1−ϵ,1+ϵ)=1+ϵ如图所示: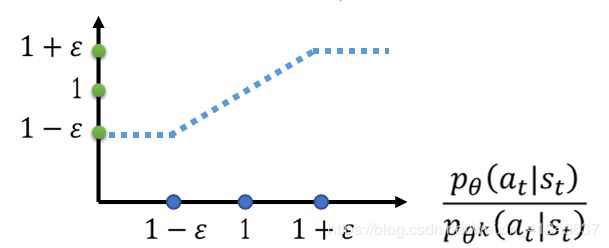
- PPO2算法公式: J P P O 2 θ k ( θ ) = ∑ ( s t , a t ) m i n ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) A θ k ( s t , a t ) , c l i p ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) , 1 − ϵ , 1 + ϵ ) A θ k ( s t , a t ) ) J_{PPO2}^{\theta^{k}}(\theta)=\sum_{(s_t,a_t)}min(\frac{p_\theta(a_t|s_t)}{p_\theta^{k}(a_t|s_t)}A^{\theta^{k}}(s_t,a_t),clip(\frac{p_{\theta}(a_t|s_t)}{p_{\theta}^{k}(a_t|s_t)},1-\epsilon,1+ \epsilon)A^{\theta^{k}}(s_t,a_t)) JPPO2θk(θ)=(st,at)∑min(pθk(at∣st)pθ(at∣st)Aθk(st,at),clip(pθk(at∣st)pθ(at∣st),1−ϵ,1+ϵ)Aθk(st,at))
- m i n ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) , c l i p ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) , 1 − ϵ , 1 + ϵ ) ) min(\frac{p_\theta(a_t|s_t)}{p_\theta^{k}(a_t|s_t)},clip(\frac{p_{\theta}(a_t|s_t)}{p_{\theta}^{k}(a_t|s_t)},1-\epsilon,1+ \epsilon)) min(pθk(at∣st)pθ(at∣st),clip(pθk(at∣st)pθ(at∣st),1−ϵ,1+ϵ))的图像如下图:
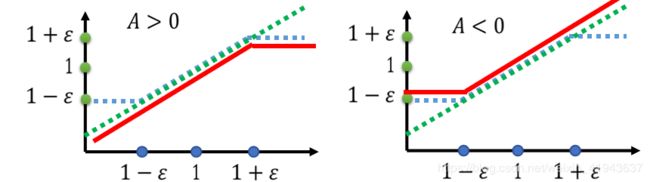
- 若A>0,说明reward是好的,那么我们就希望 p θ ( a t ∣ s t ) p_\theta(a_t|s_t) pθ(at∣st)越大越好,但是 p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) \frac{p_\theta(a_t|s_t)}{p_\theta^{k}(a_t|s_t)} pθk(at∣st)pθ(at∣st)的比值不能超过 1 + ϵ 1+\epsilon 1+ϵ;若A<0,说明reward不好的,那么我们就希望 p θ ( a t ∣ s t ) p_\theta(a_t|s_t) pθ(at∣st)越小越好,但是 p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) \frac{p_\theta(a_t|s_t)}{p_\theta^{k}(a_t|s_t)} pθk(at∣st)pθ(at∣st)的比值不能少于 1 − ϵ 1-\epsilon 1−ϵ