3.数据挖掘——房价项目预测(三)Pandas学习
目录
模块的导入
Pandas数据类型
Series
DataFrame
Panel
Pandas的运算函数
Pandas的排序
Pandas的协方差cov()和标准系数corr()
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。除了用于数据挖掘和数据分析,同时也提供数据清洗功能。
pandas存在的意义就是为用户提供更整齐更方便的数据体验
模块的导入
前面说到,Pandas是基于NumPy的一种工具,所以我们在使用Pandas的同时也要导入NumPy库。
import numpy as np
import pandas as pdPandas数据类型
- Series:它是一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。
- DataFrame:是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
- Panel:面板是具有异构数据的三维数据结构。在图形表示中很难表示面板。但是一个面板可以说明为DataFrame的容器。
Series
Series翻译过来叫做:系列 系列是具有均匀数据的一维数组结构。
Series关键点: 均匀数据 、尺寸大小不变、 数据的值可变
创建一个Series:
通过pandas.Series()函数创建系列,参数是一个列表:
s = pd.Series(np.random.randn(4))
print(s)
print(type(s))

Series 基本属性和方法:
| 属性或方法 | 描述 |
| axes | 返回行轴标签列表 |
| dtype | 返回对象的数据类型 |
| empty | 如果系列为空,则返回True |
| ndim | 返回底层数据的维数,默认定义为:1 |
| size | 返回基础数据中的元素数 |
| values | 将系列作为ndarray返回 |
| head() | 返回前n行 |
| tail() | 返回最后n行 |
s = pd.Series(np.random.randn(4))
print(s)
print(s.axes)
print(s.dtype)
print(s.empty)
print(s.size)
print(s.ndim)
print(s.values)
print(type(s.values))

s = pd.Series(np.random.randint(1,15,6))
print(s)
print("\n")
print(s.head(3))
print("\n")
print(s.tail(3))
DataFrame
数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列。 DataFrame是pandas使用最多,用途最广的类型 .
数据帧(DataFrame)的功能特点:
- 潜在的列是不同的类型
- 大小可变
- 标记轴(行和列)
- 可以对行和列执行算术运算
创建一个DataFrame :
通过pandas.DataFrame()创建:
df = pd.DataFrame(np.random.randint(1,30,12).reshape(3,4))
print(df)
Dataframe的基本属性和方法:
较Series系列多了一个转置属性和一个形状属性:
| 属性或方法 | 描述 |
| axes | 返回行轴标签列表 |
| dtype | 返回对象的数据类型 |
| empty | 如果系列为空,则返回True |
| ndim | 返回底层数据的维数,默认定义为:1 |
| size | 返回基础数据中的元素数 |
| values | 将系列作为ndarray返回 |
| head() | 返回前n行 |
| tail() | 返回最后n行 |
| T | 转置行和列 |
| shape | 返回表示DateFrame的维度的元组 |
df = pd.DataFrame(np.random.randint(1,30,12).reshape(3,4))
print(df)
print(df.T)
print(df.shape)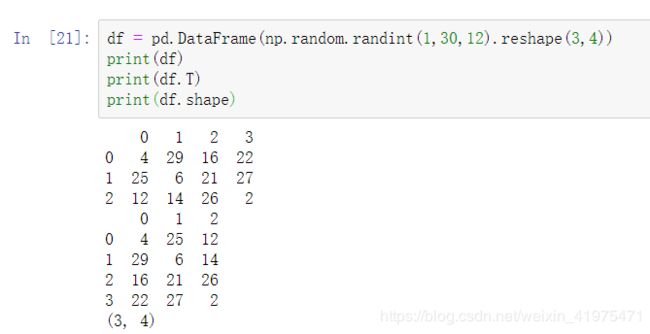
Panel
面板(Panel)是3D容器的数据。面板数据一词来源于计量经济学。
3轴(axis)这个名称旨在给出描述涉及面板数据的操作的一些语义。它们是:
- items - axis 0,每个项目对应于内部包含的数据帧(DataFrame)。
- major_axis -axis 1,它是每个数据帧(DataFrame)的索引(行)。
- minor_axis - axis 2,它是每个数据帧(DataFrame)的列。
Panel创建与基本属性:
可以使用以下构造函数创建面板:
pandas.Panel(data, items, major_axis, minor_axis, dtype, copy)参数说明:
| 参数 | 描述 |
| data | 数据采取各种形式,如:ndarray,series,map,lists,dict,constant和另一个数据帧(DataFrame) |
| items | axis=0 |
| major_axis | axis=1 |
| minor_axis | axis=2 |
| dtype | 每列的数据类型 |
| copy | 复制数据,默认为:false |
Pandas的运算函数
| 函数 | 描述 |
| count() | 非空观测数量 |
| sum() | 所有值之和 |
| mean() | 所有值的平均值 |
| median() | 所有值的中位数 |
| mode() | 值的模值 |
| std() | 值的标准偏差 |
| min() | 所有值中的最小值 |
| max() | 所有值中的最大值 |
| abs() | 绝对值 |
| prod() | 数组元素的乘积 |
| cumsum() | 累计综总和 |
| cumprod() | 累计乘积 |
创建一个实例:
d={'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Minsu','Jack','Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
df = pd.DataFrame(d)
print(df)
print(df.Age.sum())
print(df.Age.mean())
print(df.Rating.median())
print(df.Age.std())
print(df.Rating.max())
print(df.Rating.min())
Pandas的排序
Pandas的排序分为两种:一种是按标签,一张是按实际值。
创建一个演示用的例子:
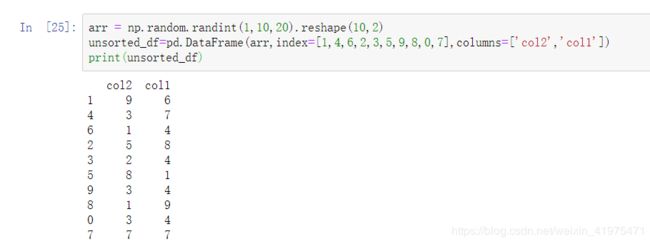
arr = np.random.randint(1,10,20).reshape(10,2)
unsorted_df=pd.DataFrame(arr,index=[1,4,6,2,3,5,9,8,0,7],columns=['col2','col1'])
print(unsorted_df)
按标签进行排序:
使用sort_index()方法,通过传递axis参数和排序顺序,可以对DataFrame进行排序。 默认情况下,按照升序对行标签进行排序。
sorted_df = unsorted_df.sort_index()
print(sorted_df)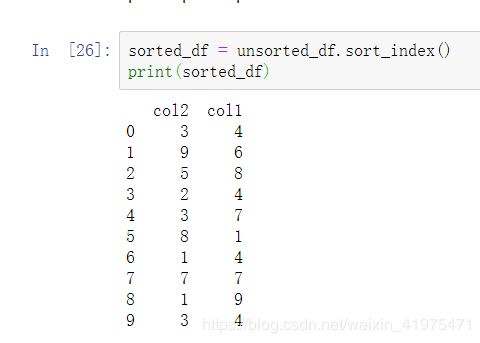
按实际值排序:
像索引排序一样,sort_values()是按值排序的方法。它接受一个by参数,它将使用要与其排序值的DataFrame的列名称。
sorted_df = unsorted_df.sort_values(by='col1')
print(sorted_df)
Pandas的协方差cov()和标准系数corr()
frame = pd.DataFrame(np.random.randn(10, 5), columns=['a', 'b', 'c', 'd', 'e'])
print(frame)
print ("\n a,b的协方差",frame['a'].cov(frame['b']))
print (frame.cov())

相关性显示了任何两个数值(系列)之间的线性关系。
frame = pd.DataFrame(np.random.randn(10, 5), columns=['a', 'b', 'c', 'd', 'e'])
print(frame)
print (frame['a'].corr(frame['b']))
print (frame.corr())
