数据结构与算法随笔之------堆与优先队列详解
堆与优先队列
1.定义
优先队列
队列是一个操作受限的线性表,数据只能在一端进入,另一端出来,具有先进先出的性质。有时在队列中需要处理优先级的情况,即后面进入的数据需要提前出来,这里就需要优先队列。优先队列是至少能够提供插入和删除最小值这两种操作的数据结构。对应于队列的操作,插入相当于入队,删除最小相当于出队。
链表,二叉查找树,都可以提供插入和删除最小这两种操作。对于链表的实现,插入需要O(1),删除最小需要遍历链表,故需要O(N)。对于二叉查找树,这两种操作都需要O(logN);而且随着不停的删除最小的操作,二叉查找树会变得非常不平衡;同时使用二叉查找树有些浪费,因此很多操作根本不需要。一种较好的实现优先队列的方式是二叉堆(下面简称堆)。
堆
堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。首先堆是完全二叉树(只有最下面的两层结点度能够小于2,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树),其次任意节点的左右孩子(若有)值都不小于其父亲,这是小根堆,即最小的永远在上面。相反的是大根堆,即大的在上面。
因为完全二叉树有很好的规律,因此可以只用数据来存储数据而不需要链表。






二.堆的基本操作

堆的结构定义
typedef struct HNode *Heap; /* 堆的类型定义 */
struct HNode {
ElementType *Data; /* 存储元素的数组 */
int Size; /* 堆中当前元素个数 */
int Capacity; /* 堆的最大容量 */
};
typedef Heap MaxHeap; /* 最大堆 */
typedef Heap MinHeap; /* 最小堆 */
#define MAXDATA 1000 /* 该值应根据具体情况定义为大于堆中所有可能元素的值 */堆的创建
MaxHeap CreateHeap( int MaxSize )
{ /* 创建容量为MaxSize的空的最大堆 */
MaxHeap H = (MaxHeap)malloc(sizeof(struct HNode));
H->Data = (ElementType *)malloc((MaxSize+1)*sizeof(ElementType));
H->Size = 0;
H->Capacity = MaxSize;
H->Data[0] = MAXDATA; /* 定义"哨兵"为大于堆中所有可能元素的值*/
return H;
}
堆的插入(最大)

你一个很自然的想法就是插入到数组的最后,所以

此时没有破坏堆的有序性


此时有序性被破坏,所以交换35与31即可



这个也一个道理,只不过要调整两次



bool Insert( MaxHeap H, ElementType X )
{ /* 将元素X插入最大堆H,其中H->Data[0]已经定义为哨兵 */
int i;
if ( IsFull(H) ) {
printf("最大堆已满");
return false;
}
i = ++H->Size; /* i指向插入后堆中的最后一个元素的位置 */
for ( ; H->Data[i/2] < X; i/=2 )
H->Data[i] = H->Data[i/2]; /* 上滤X */
H->Data[i] = X; /* 将X插入 */
return true;
}判满
bool IsFull( MaxHeap H )
{
return (H->Size == H->Capacity);
}
堆的删除操作(最大)
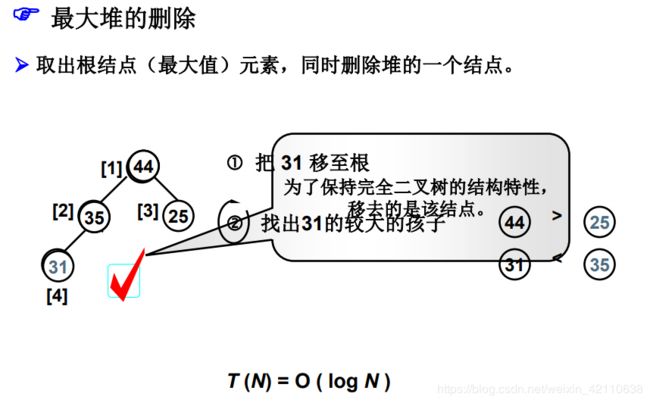

ElementType DeleteMax( MaxHeap H )
{ /* 从最大堆H中取出键值为最大的元素,并删除一个结点 */
int Parent, Child;
ElementType MaxItem, X;
if ( IsEmpty(H) ) {
printf("最大堆已为空");
return ERROR;
}
MaxItem = H->Data[1]; /* 取出根结点存放的最大值 */
/* 用最大堆中最后一个元素从根结点开始向上过滤下层结点 */
X = H->Data[H->Size--]; /* 注意当前堆的规模要减小 */
for( Parent=1; Parent*2<=H->Size; Parent=Child ) {
Child = Parent * 2;
if( (Child!=H->Size) && (H->Data[Child]Data[Child+1]) )
Child++; /* Child指向左右子结点的较大者 */
if( X >= H->Data[Child] ) break; /* 找到了合适位置 */
else /* 下滤X */
H->Data[Parent] = H->Data[Child];
}
H->Data[Parent] = X;
return MaxItem;
} 最大堆的建立
先给代码
/*----------- 建造最大堆 -----------*/
void PercDown( MaxHeap H, int p )
{ /* 下滤:将H中以H->Data[p]为根的子堆调整为最大堆 */
int Parent, Child;
ElementType X;
X = H->Data[p]; /* 取出根结点存放的值 */
for( Parent=p; Parent*2<=H->Size; Parent=Child ) {
Child = Parent * 2;
if( (Child!=H->Size) && (H->Data[Child]Data[Child+1]) )
Child++; /* Child指向左右子结点的较大者 */
if( X >= H->Data[Child] ) break; /* 找到了合适位置 */
else /* 下滤X */
H->Data[Parent] = H->Data[Child];
}
H->Data[Parent] = X;
}
void BuildHeap( MaxHeap H )
{ /* 调整H->Data[]中的元素,使满足最大堆的有序性 */
/* 这里假设所有H->Size个元素已经存在H->Data[]中 */
int i;
/* 从最后一个结点的父节点开始,到根结点1 */
for( i = H->Size/2; i>0; i-- )
PercDown( H, i );
} 思路:
不必将值一个个地插入堆中,通过交换形成堆。假设根的左、右子树都已是堆,并且根的元素名为R。这种情况下,有两种可能:
(1) R的值小于或等于其两个子女,此时堆已完成;
(2) R的值大于其某一个或全部两个子女的值,此时R应与两个子女中值较小的一个交换,结果得到一个堆,除非R仍然大于其新子女的一个或全部的两个。这种情况下,我们只需简单地继续这种将R“拉下来”的过程,直至到达某一个层使它小于它的子女,或者它成了叶结点。
建堆效率
n个结点的堆,高度d =log2n。根为第0层,则第i层结点个数为2i,考虑一个元素在堆中向下移动的距离。大约一半的结点深度为d-1,不移动(叶)。四分之一的结点深度为d-2,而它们至多能向下移动一层。树中每向上一层,结点的数目为前一层的一半,而子树高度加一。
这种算法时间代价为Ο(n)
由于堆有log n层深,插入结点、删除普通元素和删除最小元素的平均时间代价和时间复杂度都是
Ο(log n)。

。。。


下面给出一个网上找的建堆总结
为什么要把最大堆的创建放在最后来讲?因为在堆的创建过程中,有两个方法。会分别用到最大堆的插入和最大堆的删除原理。创建最大堆有两种方法:
(1)、先创建一个空堆,然后根据元素一个一个去插入结点。由于插入操作的时间复杂度为O(log2(n)),那么n个元素插入进去,总的时间复杂度为O(n * log2(n))。
(2)、将这n个元素先顺序放入一个二叉树中形成一个完全二叉树,然后来调整各个结点的位置来满足最大堆的特性。
现在我们就来试一试第二种方法来创建一个最大堆:假如我们有12个元素分别为:
{79,66,43,83,30,87,38,55,91,72,49,9}
将上诉15个数字放入一个二叉树中,确切地说是放入一个完全二叉树中,如下:
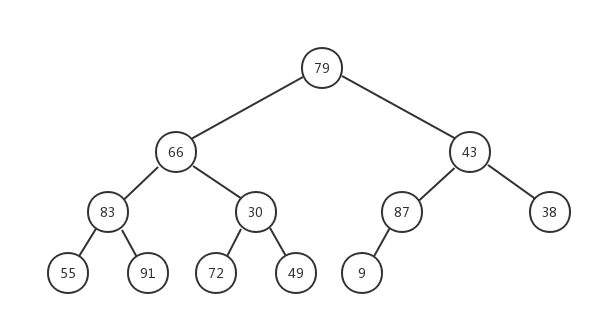
但是这明显不符合最大堆的定义,所以我们需要让该完全二叉树转换成最大堆!怎么转换成一个最大堆呢?
最大堆有一个特点就是其各个子树都是一个最大堆,那么我们就可以从把最小子树转换成一个最大堆,然后依次转换它的父节点对应的子树,直到最后的根节点所在的整个完全二叉树变成最大堆。那么从哪一个子树开始调整?
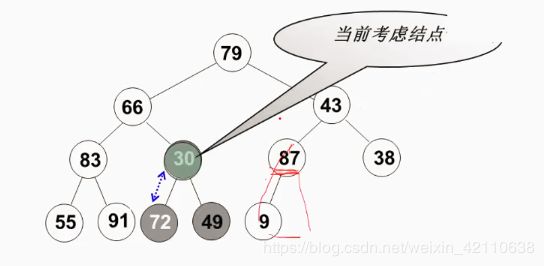
我们从该完全二叉树中的最后一个非叶子节点为根节点的子树进行调整,然后依次去找倒数第二个倒数第三个非叶子节点...
具体步骤
在做最大堆的创建具体步骤中,我们会用到最大堆删除操作中结点位置互换的原理,即关键字值较小的结点会做下沉操作。
- 1)、就如同上面所说找到二叉树中倒数第一个非叶子结点
87,然后看以该非叶子结点为根结点的子树。查看该子树是否满足最大堆要求,很明显目前该子树满足最大堆,所以我们不需要移动结点。该子树最大移动次数为1。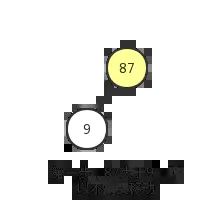
- 2)、现在来到结点
30,明显该子树不满足最大堆。在该结点的子结点较大的为72,所以结点72和结点30进行位置互换。该子树最大移动次数为1。
- 3)、同样对结点
83做类似的操作。该子树最大移动次数为1。
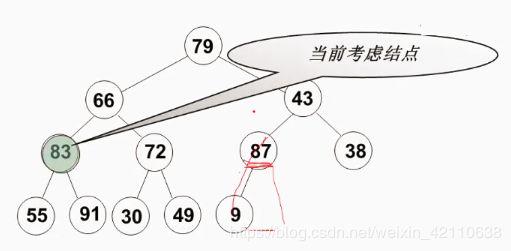
- 4)、现在来到结点
43,该结点的子结点有{87,38,9},对该子树做同样操作。由于结点43可能是其子树结点中最小的,所以该子树最大移动次数为2。
- 5)、结点
66同样操作,该子树最大移动次数为2。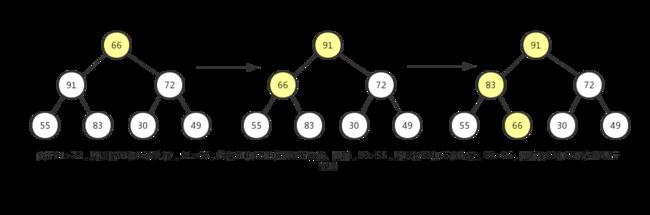
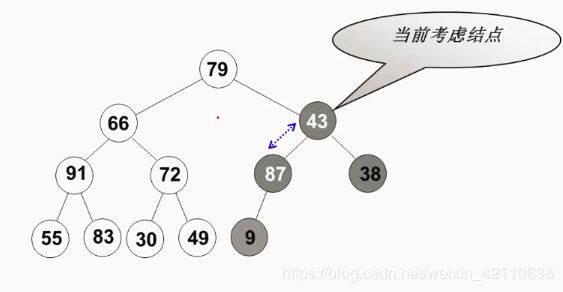
- 6)、最后来到根结点
79,该二叉树最高深度为4,所以该子树最大移动次数为3。
自此通过上诉步骤创建的最大堆为:

所以从上面可以看出,该二叉树总的需要移动结点次数最大为:10。
链接:https://www.jianshu.com/p/21bef3fc3030
最后总结一下最大堆的插入操作与删除操作
插入:直接想法插入到最后一个位置(比较堆是个完全二叉树,也就是个数组),但是一插入可能会破坏堆的有序性,那么只需要调整即可
删除:删除堆顶元素后将最后一个元素换上去,然后也是调整即可