怕了么?三年后,人工智能将彻底改变前端开发?
https://www.toutiao.com/a6697803854785806862/
2019-06-02 13:39:42
程序猿(ID:OpenSourceTop)猿妹 编译
原文:https://github.com/emilwallner/Screenshot-to-code-in-Keras、https://blog.floydhub.com/Turning-design-mockups-into-code-with-deep-learning/
近日,阮一峰@ruanyf 发了一条微博:Github 排行榜第一名,是一个梦幻项目。神经网络通过深度学习,自动把设计稿变成 HTML 代码。 作者号称三年后,人工智能彻底改变前端开发。
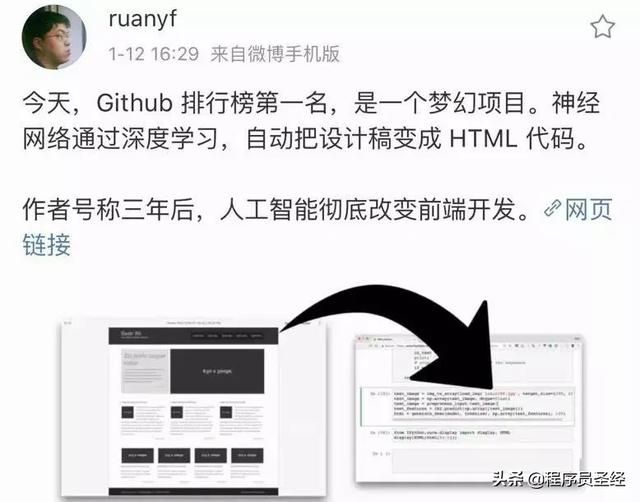
该项目作者Emil Wallner表示:三年后,人工智能将彻底改变前端开发,提高原型设计的速度,降低构建软件的障碍。
Tony Beltramelli去年发布了pix2code,Airbnb推出了sketch2code。目前,自动化前端开发的最大障碍是计算能力。但是,我们现在可以使用当前的深度学习算法,以及合成的训练数据来探索人工智能前端构建。
在这篇文章中,我们将讲述一个神经网络如何基于设计模型的图片来编写一个基本的HTML和CSS网站。以下为构建过程:
构建过程
给训练的神经网络提供设计图像
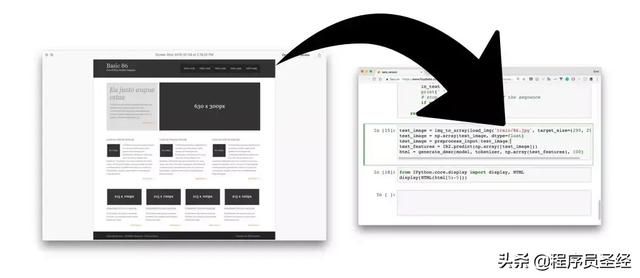
神经网络将图像转换成HTML标记
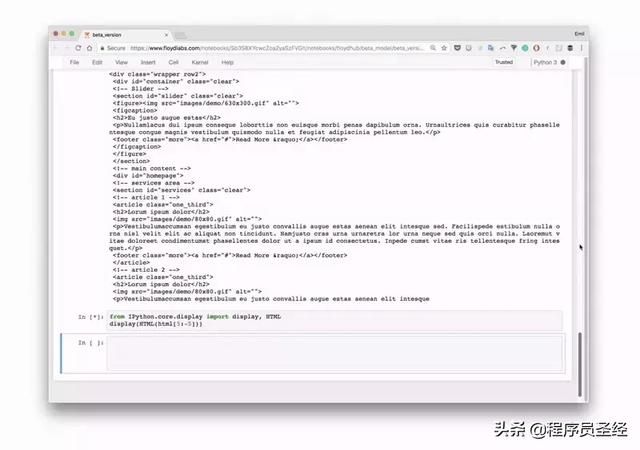
渲染输出
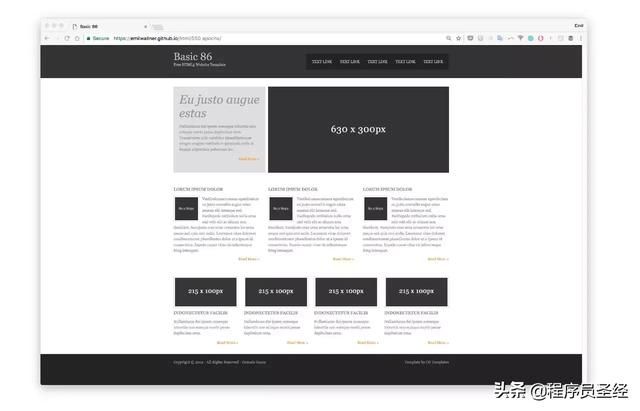
我们分为三步迭代来构建神经网络:
在第一个版本中,我们将构建最低版本来控制移动部件的一个组件。第二个版本HTML将着重于自动执行所有步骤并解释神经网络层。在最终版本Bootstrap中,我们将创建一个可以概括和探索LSTM层的模型。
所有的代码都在Github和FloydHub上。其中,floydhub目录中,本地notebook在local目录下。
代码地址如下:https://github.com/emilwallner/Screenshot-to-code-in-Keras
https://www.floydhub.com/emilwallner/projects/picturetocode
核心逻辑
我们旨在建立一个神经网络,够生成与截图对应的 HTML/CSS 标记语言。
训练神经网络时,你先给它提供几个截图以及相对应HTML代码,它通过逐个预测所有匹配的 HTML 标记来学习。当它预测下一个标记语言的标签时,就会接收到截图和之前所有正确的标记。
这里提供一个简单的训练数据示例:https://docs.google.com/spreadsheets/d/1xXwarcQZAHluorveZsACtXRdmNFbwGtN3WMNhcTdEyQ/edit?usp=sharing
创建一个逐词预测模型是当今最常见的方法,本文将在整个教程中使用此方法。
注意:每次预测时,神经网络接收的是同样的截图。也就是说如果网络需要预测 20 个单词,它就会得到 20 次同样的设计截图。现在,不用管神经网络的工作原理,只需要专注于神经网络的输入和输出。

让我们把重点放在以前的标记上。假设我们训练网络来预测“I can code”的句子。当它收到“I”,那么它预测“can”。下一次它会收到“I can”并预测“code”。它收到所有以前的单词,只需要预测下一个单词。
神经网络从数据中创建特征。神经网络构建了链接数据输入和输出的功能。它必须创建特征来了解它预测的每个屏幕截图中的内容(HTML语法)。这都是为了预测下一个标签的构建。
我们无需输入正确的 HTML 标记,网络会接收它目前生成的标记,然后预测下一个标记。预测从「起始标签」(start tag)开始,到「结束标签」(end tag)终止,或者达到最大限制时终止。
安装方法
FloydHub
FloydHub是在云GPU上运行模型的最佳选择:https://www.floydhub.com/

本地

文件夹结构

Hello World 版本
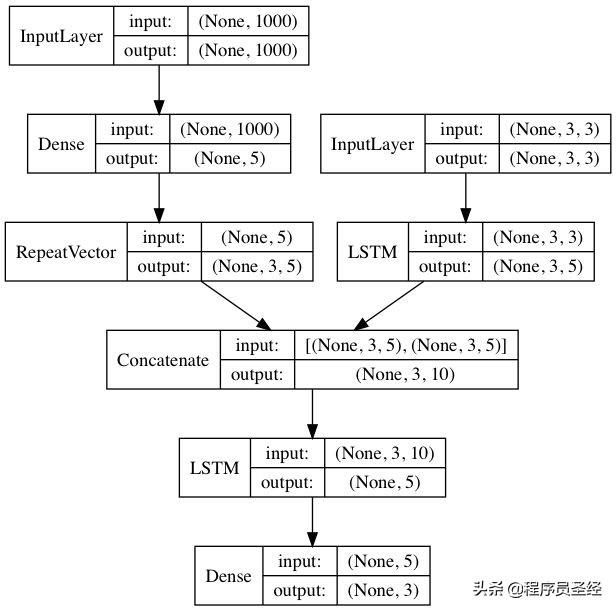
HTML
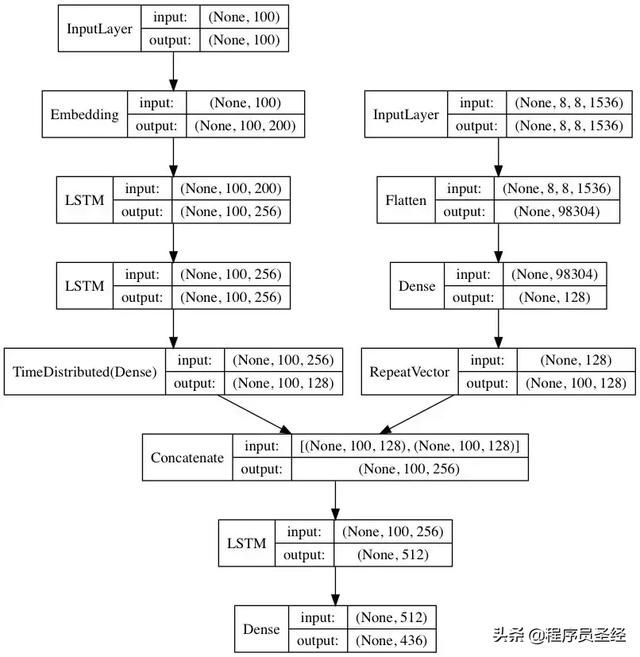
Bootstrap
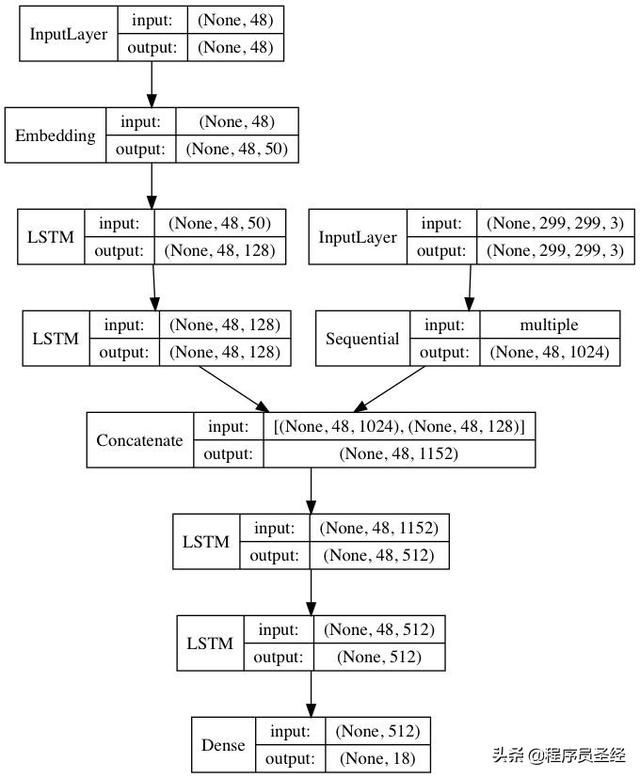
前端开发是深度学习应用的理想空间。数据容易生成,并且当前深度学习算法可以映射大部分逻辑。
一个最让人激动的领域是专注于在 LSTM 上的应用。这不仅会提升精确度,还可以使我们直观的感受到 CNN 在生成标记时所聚焦的地方。注意力一样是标记、样式表、脚本和终端之间通信的关键。注意力层可以追踪变量,使网络可以在编程语言之间进行通信。
但以后,最大的影响将会来自建立综合数据的可扩展方式。然后一步步添加字体、颜色和动画。目前为止,大多数进步发生在草图(sketches)转化为模版应用。在不到两年的时间里,我们将创建一个草图,它会在一秒之内找到相应的前端。
目前,Airbnb 设计团队与 Uizard 已经创建了两个正在使用的原型。