python机器学习---监督学习---K最近邻算法(用于分类和回归)
目录
1. K最近邻算法原理
2. K最近邻算法项目实战
2.1 电影分类
2.2 酒分类
3. K最近邻算法优缺点
备注:本文主要来自于对《深入浅出python机器学习》书籍的学习总结笔记,感兴趣的同学可以购买本书学习,学习的本质就是形成自己的逻辑。
1. K最近邻算法原理
基本思想:一个样本在特征空间中,总会有k个最临近的样本。
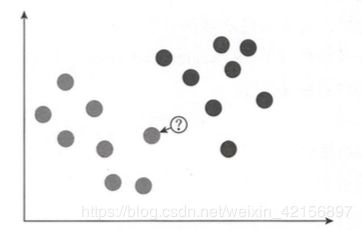

如在左边的图中,最近邻数k=1,即找到与问号样本最近的一个点,该点是灰色,因此将问号样本分类为灰色;
在右边的图中,最近邻数k=3,即找到与问号样本最近的3个点,发现有1个是灰色,2个是黑色,因此将问号样本分类为黑色。
这里举的是分类案例,实际上K最近邻算法也可用于回归,原理和用于分类相同。预测一个问号样本的的y值,模型会找到距离该问号样本最近的k个训练数据集中的点,并且将它们y值取平均值作为该问号样本的预测值。


2. K最近邻算法项目实战
2.1 电影分类
1、任务描述
通过打斗次数和接吻次数来界定电影类型
2、数据情况

3、建模过程
#导入numpy包---用np.array()对原始数据进行处理
import numpy as np
#导入KNN分类器
from sklearn.neighbors import KNeighborsClassifier
##数据预处理---数据和标签
data_x=np.array([[3,104],[2,100],[1,81],[101,10],[99,5],[98,2]])
#将打斗次数和接吻次数数据传入data
labels_y=np.array([1,1,1,2,2,2])
#用1和2来代表Romance和Action,因为sklearn不接受字符数组作为标志
##模型训练
knn=KNeighborsClassifier() #引入KNN分类算法
knn.fit(data_x,labels_y) #knn.fit(x,y)引入训练数据x,y训练knn模型
##模型应用
new_data=np.array([[18,90]])
prediction=knn.predict(new_data) #knn.predict(new_x)导入新的与x类似结构的new_x数据进行预测
prediction模型返回结果:![]()
结果为1,表示该未知电影属于Romance,与直觉相符。
2.2 酒分类
1、数据预处理
#从sklearn.datasets模块导入数据集load_wine,这是scikit-learn内置的数据集
from sklearn.datasets import load_wine
#导入KNN分类器
from sklearn.neighbors import KNeighborsClassifier
##1、数据预处理---导入的酒数据集是一种Bunch对象,它包括键keys和数值values,它有点类似字典,可用类似字段的方法查看信息
#导入数据
wine_data=load_wine()
#查看酒数据集的键keys---data.keys()
wine_data.keys()
#wine_data.values()---查看值
#wine_data.items()---查看键值
#查看数据集的详细信息
wine_data['feature_names']
#查看数据的大小
wine_data['data'].shape2、数据建模---训练/测试/应用
#2、数据建模---模型训练/测试/应用
#2.1将数据拆分为训练集和测试集---要用train_test_split模块中的train_test_split()函数,随机将75%数据化道训练集,25%数据到测试集
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
#拆分数据集---x,y都要拆分,rain_test_split(x,y,random_state=0),random_state=0使得每次生成的伪随机数不同
x_train,x_test,y_train,y_test=train_test_split(wine_data['data'],wine_data['target'],random_state=0)
#查看拆分后的数据集大小情况
print('x_train_shape:{}'.format(x_train.shape))
print('x_test_shape:{}'.format(x_test.shape))
print('y_train_shape:{}'.format(y_train.shape))
print('y_test_shape:{}'.format(y_test.shape))
#2、数据建模---模型训练/测试/应用
#2.2 模型训练---knn.fit(x_train,y_train)
#导入KNN分类器
from sklearn.neighbors import KNeighborsClassifier
#引入KNN分类算法
knn=KNeighborsClassifier(n_neighbors=1) #n_neighbors=1表示k=1
#knn.fit(x,y)对训练数据进行拟合
knn.fit(x_train,y_train)
#2、数据建模---模型训练/测试/应用
#2.3 模型测试---knn.score(x_test,y_test)
score=knn.score(x_test,y_test)
print('test_score:{:.2%}'.format(score))
#2、数据建模---模型训练/测试/应用
#2.4 模型应用---knn.predict(x_new)
#导入新数据
#导入numpy包---用np.array()对新数据进行处理
import numpy as np
#输入新的数据点---注意要与原数据结构相同
x_new=np.array([[13.2,2.77,2.51,18.5,96.6,1.04,2.55,0.57,1.47,6.2,1.05,3.33,820]])
prediction=knn.predict(x_new)
print('预测结果:{}'.format(prediction))
3. K最近邻算法优缺点
K最近邻算法是一个非常经典且原理十分容易理解的算法,这是它的优点;但是它也有许多问题,因为它要去算与每一个样本的距离,对于规模较大的数据集计算量大、内存开销大;因为高维数据即变量数变多时,欧式距离的区分能力越差,因此对高维数据集欠拟合;因为变量的值域越大时,值域越大的变量在距离计算中占主导作业,因此对稀疏的数据集不太好用,需要事先对变量进行标准化。所以在当前的各种常见场景中,该算法的使用并不多见。