【OpenCV-Python-Tutorial 数字图像处理】opencv3.4 官方API及其实例总结
目录大纲
- 官方链接整理
- 说明
- OPENCV API教程和实例整理
- 1. 图像操作基础
- 1.1 图像操作基础
- 1.2 图像通道和颜色空间变换
- 1.2 图像尺寸变换
- 2.图像变换(翻转、仿射、透视)
- 2.1 图像翻转变换
- 2.2 图像仿射变换
- 2.3 图像透视变换
- 3.图像运算
- 4.图像预处理
- 4.1 均值滤波
- 4.2 中值滤波
- 4.3 高斯滤波
- 4.4 双边滤波
- 5.形态学操作
- 5.1腐蚀
- 5.2 膨胀
- 5.3 形态学操作
- 开运算:先进行腐蚀操作,后进行膨胀操作,主要用来去除一些较亮的噪声点,即先腐蚀掉不要的部分,再进行膨胀。
- 闭运算:先进行膨胀操作,后进行腐蚀操作,主要用来去除一些较暗的噪声点,关闭一些物体上的小洞,或者黑色的小孔。
- 形态学梯度:膨胀运算结果减去腐蚀运算结果,可以拿到轮廓信息。
- 顶帽运算:原图像减去开运算结果,得到噪声图像。
- 黑帽运算:原图像减去闭运算结果,得到前景中的小黑点或者内部小孔。
- 6.图像分割(梯度、边缘检测)
- 6.1 阈值分割
- 6.1 sobel算子
- 6.2 scharr算子
- 6.3 Laplacian算子
- 6.4 Canny算子
- 6.5 边缘检测代码汇总
- 汇总效果图
- 7.图像金字塔、轮廓检测、Hough变换
- 两种类型的金字塔:
- 两种类型的采样:
- 7.1 下采样
- 7.2 上采样
- 7.2 图像轮廓检测
- 7.2 Hough变换
- 8.图像直方图
- 图像直方图
- 9.傅里叶变换
- 傅里叶变换和逆变换
- 频域滤波
- 高通滤波
- 低通滤波
- 10. 图像特征提取和描述
- 10.1 Harris角点检测
- 10.2 SIFT算法
- 10.3 SURF算法
- 10.3 FAST算法
- 10.4 ORB算法
- 10.5 特征匹配
- 11. 视频分析
- 11.1 摄像头视频
- (1) 用摄像头捕获视频
- (2) 保存视频
- (2) 播放视频
- 11.2光流
- 12.摄像机标定和3D重构
- 12.1 相机标定
- 12.2 位置和姿态估计
- 13.机器学习
- 13.1 K近邻(k-Nearest Neighbour, knn)
- 13.2 SVM支持向量机
- 13.3 K值聚类
- 14 深度学习 (待补充)
- 15 多目标跟踪(待补充)
整理资料和实例,着实不容易,后续经常分享实用干货知识。希望各位路过的朋友点赞、关注、转发。
官方链接整理
- OpenCV官方教程:https://docs.opencv.org/master/d6/d00/tutorial_py_root.html
- 中文版教程,注意是python2:
链接: https://pan.baidu.com/s/1brvNxngMSPvLk8fvzYjLKw 提取码: q587 - 官方教程:
链接: https://pan.baidu.com/s/1tBF__qpQWflFHhVvPqovDA 提取码: iqjr - 官方例子:
链接: https://pan.baidu.com/s/1Fiw98FCW9hl_7ZOB9htL8A 提取码: rvdm
说明
因为链接中的段兄于2014年翻译的opencv3官方API(参见官方链接 2.中文版教程)是较老的版本并且使用的是PYTHON2,但是随着opencv源代码的不打断迭代,有些api已经不再是原来的接口和用法,鄙人不才,现与2019年末重新整理了一下相关的官方API。具体版本如下:
opencv:3.4.2.16(高于此版本,例如新出的4.x版本,有些接口已经开始收费,所以默认为这是免费版本的最高稳定版了)
python: 3.7
OPENCV API教程和实例整理
1. 图像操作基础
opencv常见用法参见:
图像基本处理: https://www.cnblogs.com/shizhengwen/p/8719062.html
图像通道: https://www.jianshu.com/p/ed00179ede34
图像变换: https://www.jianshu.com/p/ef67cacf442c
------------------------------图像基本操作---------------------------------
1.1 图像操作基础
(1) import cv2
- 功能: 导入函数库
导入opencv函数库(本例使用的是3.4.2.16版本,> 3.4.2的版本会有部分功能版权收费,建议选择3.4.2.16版本及其以下)
(2) rtval = cv2.imread(file_path, flags)
- 功能:读取图片
- 参数:
file_path:要读入图片的完整路径
flags:读入图片的标志 ,常用的参数如下
cv2.IMREAD_COLOR:默认参数,读入一副彩色图片,忽略alpha通道
cv2.IMREAD_GRAYSCALE:读入灰度图片,此时是单通道
cv2.IMREAD_UNCHANGED:顾名思义,读入完整图片,包括alpha通道 - 返回值rtval:
读取的图片信息矩阵 - 示例:
# windows路径表示方法1:就在本文件夹下的图片,eg:
img = cv.imread("./lena.jpg",cv.IMREAD_GRAYSCALE)
# windows路径表示方法2:添加r在绝对、相对路径下,可在windows环境正常读取,否则会有问题:
img = cv.imread(r"D:\111111Python\AI\img_project\lena.jpg")
(3) cv2.imshow(wname, img)
- 功能:显示图片
- 参数:
wname:图像的窗口的名字,自己可以定义
img:要显示的图像(imread的返回值) - 返回值:
读取的图片信息矩阵 - 示例:
cv.imshow("lena_naked_img",img)
(4) rtval = cv2.waitKey(xxx_ms) 是一个键盘绑定函数。
-
功能:函数的功能是刷新图像,其中参数xxx_ms表示刷新频率
-
参数:
xxx_ms 表示等待间隔的时间(ms)
xxx_ms > 0, 在xxx_ms内,等待特定键盘输入
xxx_ms <= 0, 无限期等待键盘单击需要指出的是它的时间尺度是毫 秒级。函数等待特定的几毫秒,看是否有键盘输入。
-
返回值rtval :
特定的几毫秒之内,如果 按下任意键,这个函数会返回按键的 ASCII 码值,程序将会继续运行。如果没有键盘输入,返回值为 -1,
如果我们设置这个函数的参数为 0,那它将会无限 期的等待键盘输入。
它也可以被用来检测特定键是否被按下,例如按键 a 是否 被按下 -
示例:
cv2.waitKey(0)
键盘按键对应ascii码表:http://www.asciima.com/ascii/1.html
(5) retval = imwrite(filename, img [, params])
-
功能:按照一定缩放比例保存图片
-
参数:
filename:保存图片的(完整路径下的)名字
img:是要保存的图像
params:可选的第三个参数,它针对特定的格式:对于JPEG,其表示的是图像的质量,用0 - 100的整数表示,默认95;对于png ,第三个参数表示的是压缩级别。默认为3.
注意:cv2.IMWRITE_JPEG_QUALITY类型为 long ,必须转换成 int cv2.IMWRITE_PNG_COMPRESSION, 从0到9 压缩级别越高图像越小。 -
返回值rtval :
保存的新图片 -
示例:
cv2.imwrite('1.jpg',img, [int( cv2.IMWRITE_JPEG_QUALITY), 95])
cv2.imwrite('1.png',img, [int(cv2.IMWRITE_PNG_COMPRESSION), 9])
(6) cv.destroyAllWindows()
cv2.destroyAllWindow()销毁所有窗口
cv2.destroyWindow(wname)销毁指定窗口,此处注意窗口名称
- 示例:
cv2.destroyWindow(“lena_naked_img”)
(7) rtval = img.item(location)
-
功能:图片像素点读取
-
参数:
location:灰度图像(w,h) 彩色图像 (w,h,c)注意:
W: 图片像素行; h:图片像素列; c:图片通道(RGB彩色图片是0-2,opencv读取像素是B/G/R->0/1/2) -
返回值rtval :某个像素点值
-
示例:
img = cv2.imread(file_path, flags)
rtval = img.item(location)
(7) img.itemset(location, value)
-
功能:图片像素点值更改
-
参数:
location:灰度图像(w,h) 彩色图像 (w,h,c)注意:
W: 图片像素行; h:图片像素列; c:图片通道(RGB彩色图片是0-2,opencv读取像素是B/G/R->0/1/2)value:
特定位置新的像素值 -
返回值rtval :None
-
示例:
img = cv2.imread(file_path, flags)
rtval = img.itemset((100,100,0), 255)
------------------------------图像通道、颜色空间、尺寸变换---------------------------------
1.2 图像通道和颜色空间变换
(8) b, g, r = cv2.split(img)
-
功能:rgb彩色图片,拆分成不同通道
-
参数:
img:待拆分的图片 -
返回值rtval :
r,g,b:新拆分出来的3个通道 -
示例:
a=cv2.imread("image\lenacolor.png")
b,g,r=cv2.split(a)
(9) img = cv2.merge([b,g,r])
- 功能:b,g,r单通道图像信息合并成彩色图片
- 参数:
b,g,r:不同通道信息,注意顺序不可变 - 返回值rtval :
彩色图片 - 示例:
a=cv2.imread("image\lenacolor.png")
rows,cols,chn=a.shape
b=cv2.split(a)[0]
g = np.zeros((rows,cols),dtype=a.dtype)
r = np.zeros((rows,cols),dtype=a.dtype)
m=cv2.merge([b,g,r])
(10) dst = cv2.cvtColor(src, code[, dst[, dstCn]])
-
功能:图像类型变换,从一种颜色空间转变为另一种颜色空间,例如BRG-> RGB, BGR->HSV GRAY->BGR等
-
参数:
src: 输入图像
code: OpenCV2的CV_前缀宏命名规范被OpenCV3中的COLOR_式的宏命名前缀取代注意RGB色彩空间默认通道顺序为BGR 常用的例如: opencv默认是BGR图像,BGR->RGB颜色空间 :cv2.COLOR_BGR2RGB, BGR->灰度图片(变成单通道):cv2.COLOR_BGR2GRAY, BGR->HSV: cv2.COLOR_BGR2HSV, GRAY->BGR: cv2.COLOR_GRAY2BGR, (具体可以参考: http://docs.opencv.org/3.1.0/d7/d1b/group__imgproc__misc.html#ga4e0972be5de079fed4e3a10e24ef5ef0)dst: 相同尺度和深度的目标图像,一般省略
dstCn: 目标图像的通道数,该参数为0时,目标图像根据源图像的通道数和具体操作自动决定 -
返回值dst :输出的新的颜色空间的图像
-
示例:略
1.2 图像尺寸变换
(11) dst = cv2.resize(src, dsize [, dst [, fx [, fy [, interpolation ]]]])
-
功能:按照一定尺度对图片进行缩放
-
参数:
src - 原图
dst - 目标图像。一般不填写
dsize - 目标图像大小。当参数dsize不为0时,dst的大小为size;
否则,它的大小需要根据src的大小,参数fx和fy决定。
dst的类型(type)和src图像相同当dsize为0时,它可以通过以下公式计算得出:dsize = (width, height)= round(src x fx, src x fy) 注意: 参数dsize和参数(fx, fy)不能够同时为0 fx - 水平轴上的比例因子。当它为0时,计算公式如下: fx = dsize.width/src.cols fy - 垂直轴上的比例因子。当它为0时,计算公式如下: fy = dsize.height/src.rows interpolation - 插值方法。共有5种: 1)INTER_NEAREST - 最近邻插值法 2)INTER_LINEAR - 双线性插值法(默认) 3)INTER_AREA - 基于局部像素的重采样(resampling using pixel area relation)。对于图像抽取(image decimation)来说,这可能是一个更好的方法。但如果是放大图像时,它和最近邻法的效果类似。 4)INTER_CUBIC - 基于4x4像素邻域的3次插值法 5)INTER_LANCZOS4 - 基于8x8像素邻域的Lanczos插值 ref:https://www.cnblogs.com/jyxbk/p/7651241.html -
返回值rtval :目标图像
-
示例:
img = cv2.imread("lena.jpg")
# 输入出图像的(width, height)
height, width = img.shape[:2]
# 缩小图像
size = (int(width*0.3), int(height*0.5))
shrink = cv2.resize(img, size, interpolation=cv2.INTER_AREA)
# 放大图像
fx = 1.6
fy = 1.2
enlarge = cv2.resize(img, (0, 0), fx=fx, fy=fy, interpolation=cv2.INTER_CUBIC)
2.图像变换(翻转、仿射、透视)
opencv常见用法参见:
图像平移旋转翻转等 https://www.jianshu.com/p/ef67cacf442c
几何变化官方 https://docs.opencv.org/3.4/da/d6e/tutorial_py_geometric_transformations.html
https://blog.csdn.net/zh_jessica/article/details/77946346 https://blog.csdn.net/zh_jessica/article/details/77946346#2-%E6%97%8B%E8%BD%ACrotate
https://www.iteye.com/blog/huangyongxing310-2432254
cv2.flip() # 图像翻转
cv2.warpAffine() #图像仿射
cv2.getRotationMatrix2D() #取得旋转角度的Matrix
cv2.GetAffineTransform(src, dst, mapMatrix) #取得图像仿射的matrix
cv2.getPerspectiveTransform(src, dst) #取得图像透视的4个点起止值
cv2.warpPerspective() #图像透视
2.1 图像翻转变换
(1) dst = cv2.flip(src, flipCode[, dst])
-
功能:图像翻转
-
参数:
src: 原始图像矩阵;
dst: 变换后的矩阵;
flipCode: 翻转方式,有三种模式0 --- 垂直方向翻转; 1----- 水平方向翻转; -1:水平、垂直方向同时翻转 注意: flipCode==0垂直翻转(沿X轴翻转), flipCode>0水平翻转(沿Y轴翻转), flipCode<0水平垂直翻转(先沿X轴翻转,再沿Y轴翻转,等价于旋转180°) -
返回值dst :翻转后的图像
-
示例:
%matplotlib inline
from matplotlib import pyplot as plt
import numpy as np
import cv2
image = cv2.imread("aier.jpg")
# Flipped Horizontally 水平翻转
h_flip = cv2.flip(image, 1)
# Flipped Vertically 垂直翻转
v_flip = cv2.flip(image, 0)
# Flipped Horizontally & Vertically 水平垂直翻转
hv_flip = cv2.flip(image, -1)
plt.figure(figsize=(8,8))
plt.subplot(221)
plt.imshow(image[:,:,::-1])
plt.title('original')
plt.subplot(222)
plt.imshow(h_flip[:,:,::-1])
plt.title('horizontal flip')
plt.subplot(223)
plt.imshow(v_flip[:,:,::-1])
plt.title(' vertical flip')
plt.subplot(224)
plt.imshow(hv_flip[:,:,::-1])
plt.title('h_v flip')
# 调整子图间距
# plt.subplots_adjust(wspace=0.5, hspace=0.1)
plt.subplots_adjust(top=0.8, bottom=0.08, left=0.10, right=0.95, hspace=0,
wspace=0.35)
# plt.tight_layout()
plt.show()
2.2 图像仿射变换
(1) dst = cv2.getRotationMatrix2D(center, angle, scale)
-
功能:得到图像的旋转矩阵 M,
-
参数:
center–表示旋转的中心点 angle–表示旋转的角度degrees scale–图像缩放因子 -
返回值dst :旋转矩阵 M
-
示例:
cv2.getRotationMatrix2D常和 cv2.warpAffine组合进行图像旋转。
图像旋转:设(x0, y0)是旋转后的坐标,(x, y)是旋转前的坐标,(m,n)是旋转中心,a是旋转的角度,(left,top)是旋转后图像的左上角坐标,则公式如下:
[x0 y0 1] = [x y 1] [1 0 0 [cosa -sina 0 [1 0 0
0 -1 0 sina cosa 0 0 -1 0
-m n 1] 0 0 1]left top 1]
例:图像旋转90度
img = cv2.imread('messi5.jpg',0)
rows,cols = img.shape
M = cv2.getRotationMatrix2D((cols/2,rows/2),90,1)
dst = cv2.warpAffine(img,M,(cols, rows))
(3) dst = cv2.warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]])
-
功能:将仿射变换应用与图像,可进行图像的平移、旋转、缩放等
-
参数:
src – 输入的图像
M – 2 X 3 的变换矩阵.
dsize – 输出的图像的size大小
dst – 输出的图像
flags – 输出图像的插值方法
flags:插值方法和以下开关选项的组合:flages表示插值方式,默认为 flags=cv2.INTER_LINEAR,表示线性插值, 此外还有: cv2.INTER_NEAREST(最近邻插值) cv2.INTER_AREA (区域插值) cv2.INTER_CUBIC(三次样条插值) cv2.INTER_LANCZOS4(Lanczos插值)borderMode – 图像边界的处理方式
borderValue – 边界填充颜色,默认是0;如果想改成白色,可以写成 borderValue=(255,255,255) -
返回值dst :经过仿射变换后的新图像
-
示例:
例:图像平移
img = cv2.imread("lena.tiff", cv2.IMREAD_UNCHANGED)
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
M = np.float32([[1, 0, 0], [0, 1, 100]])
img1 = cv2.warpAffine(image, M, (image.shape[1], image.shape[0]))
(4) dst = cv2.getAffineTransform(src, dst)
-
功能:通过对比前后两幅图3个对应点坐标,获取前后两幅图片放射变换矩阵M
说明:
图像的旋转加上拉升就是图像仿射变换,仿射变化也是需要一个M矩阵就可以, 但是由于仿射变换比较复杂,一般直接找很难找到这个矩阵,opencv提供了根据变换前后三个点的对应关系来自动求解M。 这个函数是M=cv2.getAffineTransform(pos1,pos2), 其中两个位置就是变换前后的对应位置关系。 输出的就是仿射矩阵M。然后在使用函数cv2.warpAffine()。 -
参数:
src,dst:原图像和放射变换新图像上对应的3对点坐标 -
返回值dst :仿射变换矩阵
-
示例:
import cv2
img = cv2.imread('aier.jpg')
rows,cols = img.shape[:2]
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,20],[100,250]])
M = cv2.getAffineTransform(pts1,pts2)
res = cv2.warpAffine(img,M,(rows,cols))
2.3 图像透视变换
(5) cv2.getPerspectiveTransform(src, dst) → retval
- 功能:通过4对前后变换的坐标点,计算透视变化关系矩阵M
- 参数:src, dst分别是原图像和透视图像上对应的4对点坐标
- 返回值dst :变换矩阵M
- 示例:
## pts1 ==> pts2
pts1=np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2=np.float32([[0,0],[300,0],[0,300],[300,300]])
M=cv2.getPerspectiveTransform(pts1,pts2)
(6) cv2.warpPerspective(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) → dst
-
功能:透视变换
说明:视角变换,需要一个3*3变换矩阵。在变换前后要保证直线还是直线。 构建此矩阵需要在输入图像中找寻 4个点,以及在输出图像中对应的位置。这四个点中的任意三个点不能共线。 -
参数:
-
返回值dst :
-
示例:
import cv2
import numpy as np
img=cv2.imread('aier.jpg')
rows,cols,ch=img.shape
pts1=np.float32([[56,5],[368,5],[28,387],[389,390]])
pts2=np.float32([[0,0],[300,0],[0,300],[300,300]])
M=cv2.getPerspectiveTransform(pts1,pts2)
dst=cv2.warpPerspective(img,M,(300,300))
3.图像运算
opencv常见用法参见:
https://www.cnblogs.com/blog-xyy/p/11184095.html
(1) dst=cv2.add(src1, src2[, dst[, mask[, dtype]]])
(2) dst=cv2.subtract(src1,src2,dst,mask,dtype)
(3) dst=cv2.multiply(src1,src2,dst,scale,dtype)
(4) dst=cv2.divide(src1,src2,dst,scale,dtype)
- 功能:
(1)将两张图片的元素相加
(2)相减
(3)相乘 dst = scale * src1 * src2
(4)相除 dst = scale * src1 / src2
注意:A. opencv这全是饱和运算,即如果进行加减乘除,数值超过[0, 250]的话,会选择最小/最大值作为当前值
例如:令src1 + src2 = val,
val > 255 ,val =255;
val <= 255, val等于相加结果
B. 如果只是图片元素的加减乘除,进行numpy运算,所开展的都是取模运算。
例如:令src1 + src2 = val,
val > 255 ,val = val % 255;
val <= 255, val等于相加结果
C.参与运算的图像,数字范围一定是相同的
- 参数:
src1:第一张图像
src2:第二张图像
dst:destination,目标图像,需要提前分配空间,可省略
mask:8位单通道数组,指定要更改的输出数组的元素。
scale:缩放比
dtype:输出数组的深度,默认等于-1 - 返回值dst :输出图片
- 示例:
#例1:
import cv2 as cv
import numpy as np
img1 = cv.imread('1.jpg') # 图片1
img2 = cv.imread('2.jpg') # 图片2
add = cv.add(img1, img2) # 两个图像相加
subtract = cv.subtract(img1, img2) # 两个图像相减
multiply = cv.multiply(img1, img2) # 两个图像相乘
divide = cv.divide(img1, img2) # 两个图像相除
cv.imshow("test", add)
#例2:
x = np.uint8([25]) #无符号8位整型,表示范围是[0, 255]的整数
y = np.uint8([100])
print(cv2.subtract(x, y)) # 250+10 = 260 => [[255]]
print(x+y) # 250+10 = 260 % 256 = 4 =>[4]
(5) dst = cv.addWeighted(src1, alpha, src2, beta, gamma[, dst[, dtype]])
- 功能:这也是图像的融合,但是给图像不同的权重,因此它给人一种混合或透明的感觉。图像按下式添加:
dst=α⋅img1+β⋅img2+γ - 参数:
src1:第一幅图像
appha:第一个数组元素所占权重
src2:第二幅图像
beta:第二个数组元素所占权重
gamma:亮度调节值,不能省略,不用的时候写成0即可
dst:与输入数组具有相同大小和通道数的output数组
dtype:输出数组的深度,默认等于-1 - 返回值dst :输出图像
- 示例:
img1 = cv.imread('1.jpg') # 图片1
img2 = cv.imread('2.jpg') # 图片
dst = cv.addWeighted(img1, 1, img2, 1, 0)
cv.imshow("test", dst)
4.图像预处理
opencv常见用法参见:
平滑滤波 https://www.cnblogs.com/zyly/p/8893579.html
双边滤波 https://blog.csdn.net/keith_bb/article/details/54427779
https://blog.csdn.net/piaoxuezhong/article/details/78302920?utm_source=distribute.pc_relevant.none-task
4.1 均值滤波
(1) dst = cv2.blur(src, ksize[, dst[, anchor[, borderType]]])
- 功能:均值滤波
均值滤波是一种典型的线性滤波算法,主要是利用像素点邻域的像素值来计算像素点的值。其具体方法是首先给出一个滤波kernel,该核将覆盖像素点周围的其他邻域像素点,去掉像素本身,将其邻域像素点相加然后取平均值即为该像素点的新的像素值,这就是均值滤波的本质。 - 参数:
src: 输入图像,图像深度是cv2.CV_8U、cv2.CV_16U、cv2.CV_16S、cv2.CV_32F以及cv2.CV_64F其中的某一个。
dst: 输出图像,深度和类型与输入图像一致。
ksize: 滤波kernel的尺寸,元组类型。
anchor: 字面意思是锚点,也就是处理的像素位于kernel的什么位置,默认值为(-1, -1)即位于kernel中心点,如果没有特殊需要则不需要更改。
borderType 用于推断图像外部像素的某种边界模式,有默认值cv2.BORDER_DEFAULT。 - 返回值dst :滤波后的图像
- 示例:参见汇总
(2) dst = boxFilter(src, ddepth, ksize[, dst[, anchor[, normalize[, borderType]]]])
-
功能:均值滤波
-
参数:
src:输入图像
dst: 输出图像
ddepth:int类型的目标图像深度,通常使用“-1”表示与原始图像一致
ksize: 滤波kernel的尺寸,元组类型
normalize :是否对目标图像进行归一化处理。如果 normalize = 1(默认),即对卷积核求均值,和cv2.blur作用相同 如果 normalize = 0,表示的是将所有元素都加起来(,但是不求均值),这样容易溢出anchor: 字面意思是锚点,也就是处理的像素位于kernel的什么位置,默认值为(-1, -1)即位于kernel中心点,如果没有特殊需要则不需要更改。
borderType 用于推断图像外部像素的某种边界模式,有默认值cv2.BORDER_DEFAULT。 -
返回值dst :滤波后的图像
-
示例:参见汇总
4.2 中值滤波
(3) dst = cv2.medianBlur(src,ksize[,dst])
-
功能:中值滤波函数
中值滤波是一种典型的非线性滤波,是基于排序统计理论的一种能够有效抑制噪声的非线性信号处理技术,基本思想是用像素点邻域灰度值的中值来代替该像素点的灰度值,让周围的像素值接近真实的值从而消除孤立的噪声点。该方法在取出脉冲噪声、椒盐噪声的同时能保留图像的边缘细节。这些优良特性是线性滤波所不具备的。中值滤波首先也得生成一个滤波核,将该核内的各像素值进行排序,生成单调上升或单调下降的二维数据序列,二维中值滤波输出为g(x, y)=medf{f(x-k, y-1),(k, l∈w)},其中f(x,y)和g(x,y)分别是原图像和处理后图像, w为输入的二维模板,能够在整幅图像上滑动,通常尺寸为33或55区域,也可以是不同的形状如线状、圆形、十字形、圆环形等。通过从图像中的二维模板取出奇数个数据进行排序,用排序后的中值取代要处理的数据即可。
中值滤波对消除椒盐噪声非常有效,能够克服线性滤波器带来的图像细节模糊等弊端,能够有效保护图像边缘信息,是非常经典的平滑噪声处理方法。在光学测量条纹图像的相位分析处理方法中有特殊作用,但在条纹中心分析方法中作用不大。
-
参数:
src: 输入图像,图像为1、3、4通道的图像,当核尺寸为3或5时,图像深度只能为cv2.CV_8U、cv2.CV_16U、cv2.CV_32F中的一个,如而对于较大孔径尺寸的图片,图像深度只能是cv2.CV_8U。
dst: 输出图像,尺寸和类型与输入图像一致。
ksize: 滤波核的尺寸大小,必须是大于1的奇数,如3、5、7…… -
返回值dst :滤波后的图像
-
示例:参见汇总
4.3 高斯滤波
(4) dst = cv2.GaussianBlur(src,ksize,sigmaX[,sigmaxY[,borderType]]])
-
功能:高斯滤波函数。
高斯滤波是一种线性平滑滤波,对于除去高斯噪声有很好的效果。在其官方文档中形容高斯滤波为”Probably the most useful filter”,同时也指出高斯滤波并不是效率最高的滤波算法。高斯算法在官方文档给出的解释是高斯滤波是通过对输入数组的每个点与输入的高斯滤波核执行卷积计算然后将这些结果一块组成了滤波后的输出数组,通俗的讲就是高斯滤波是对整幅图像进行加权平均的过程,每一个像素点的值都由其本身和邻域内的其他像素值经过加权平均后得到。高斯滤波的具体操作是:用一个核(或称卷积、掩模)扫描图像中的每一个像素,用模板确定的邻域内像素的加权平均灰度值去替代模板中心像素点的值。在图像处理中高斯滤波一般有两种实现方式:一种是用离散化窗口滑窗卷积,另一种是通过傅里叶变换。最常见的就是第一种滑窗实现,只有当离散化的窗口非常大,用滑窗计算量非常大的情况下会考虑基于傅里叶变换的方法。
我们在参考其他文章的时候可能会出现高斯模糊和高斯滤波两种说法,其实这两种说法是有一定区别的。我们知道滤波器分为高通、低通、带通等类型,高斯滤波和高斯模糊就是依据滤波器是低通滤波器还是高通滤波器来区分的。比如低通滤波器,像素能量低的通过,而对于像素能量高的部分将会采取加权平均的方法重新计算像素的值,将能量像素的值编程能量较低的值,我们知道对于图像而言其高频部分展现图像细节,所以经过低通滤波器之后整幅图像变成低频造成图像模糊,这就被称为高斯模糊;相反高通滤波是允许高频通过而过滤掉低频,这样将低频像素进行锐化操作,图像变的更加清晰,被称为高斯滤波。说白了很简单就是:高斯滤波是指用高斯函数作为滤波函数的滤波操作而高斯模糊是用高斯低通滤波器。
高斯滤波在图像处理中常用来对图像进行预处理操作,虽然耗时但是数字图像用于后期应用但是其噪声是最大的问题,噪声会造成很大的误差而误差在不同的处理操作中会累积传递,为了能够得到较好的图像,对图像进行预处理去除噪声也是针对数字图像处理的无奈之举。
高斯滤波器是一类根据高斯函数的形状来选择权值的线性平滑滤波器,高斯滤波器对于服从正太分布的噪声非常有效。
-
参数:
src: 输入图像,图像深度为cv2.CV_8U、cv2.CV_16U、cv2.CV_16S、cv2.CV_32F、cv2.CV_64F。dst: 输出图像,与输入图像有相同的类型和尺寸。
ksize: 高斯内核大小,元组类型
sigmaX: 高斯核函数在X方向上的标准偏差
一般取sigmaX = 0,sigma = 0.3*((ksize - 1)*0.5 - 1) + 0.8sigmaY: 高斯核函数在Y方向上的标准偏差,如果sigmaY是0,则函数会自动将sigmaY的值设置为与sigmaX相同的值,如果sigmaX和sigmaY都是0,这两个值将由ksize[0]和ksize[1]计算而来。具体可以参考getGaussianKernel()函数查看具体细节。建议将size、sigmaX和sigmaY都指定出来。
borderType: 推断图像外部像素的某种便捷模式,有默认值cv2.BORDER_DEFAULT,如果没有特殊需要不用更改,具体可以参考borderInterpolate()函数。
-
返回值dst :滤波后的图像
-
示例:
# 汇总
import cv2
from matplotlib import pyplot as plt
img_ori = cv2.imread("./lena.jpg")
img = cv2.resize(img, (int(img_ori.shape[1]/2), int(img_ori.shape[0]/2)))
# 均值,kenel=(3,3)
img_average = cv2.blur(img, (3,3))
# 高斯
img_gaussian = cv2.GaussianBlur(img, (5,5), 0)
# 中值
img_midia = cv2.medianBlur(img, 5)
cv2.imshow("original", img)
cv2.imshow("average", img_average)
cv2.imshow("gaussian", img_gaussian)
cv2.imshow("median", img_midia)
cv2.waitKey(0)
cv2.destroyAllWindows()
4.4 双边滤波
(5) dst = cv2.bilateralFilter(src, d, sigmaColor, sigmaSpace[, dst[, borderType]])
-
功能:
双边滤波是一种非线性滤波器,它可以达到保持边缘、降噪平滑的效果。和其他滤波原理一样,双边滤波也是采用加权平均的方法,用周边像素亮度值的加权平均代表某个像素的强度,所用的加权平均基于高斯分布[1]。最重要的是,双边滤波的权重不仅考虑了像素的欧氏距离(如普通的高斯低通滤波,只考虑了位置对中心像素的影响),还考虑了像素范围域中的辐射差异(例如卷积核中像素与中心像素之间相似程度、颜色强度,深度距离等),在计算中心像素的时候同时考虑这两个权重。这种方法会确保边界不会被模糊掉,因为边界处的灰度值变化比较大。但是这种操作与其他滤波器相比会比较慢。
对于简单的滤波而言,可以将两个sigma值设置成相同的值,如果值<10,则对滤波器影响很小,如果值>150则会对滤波器产生较大的影响,会使图片看起来像卡通。 -
参数:
src:输入图像
d:过滤时周围每个像素领域的直径
sigmaColor:颜色空间过滤器的sigma值,这个参数的值越大,表明该像素邻域内有越宽广的颜色会被混合到一起,产生较大的半相等颜色区域。
sigmaSpace:坐标空间中滤波器的sigma值,如果该值较大,则意味着颜色相近的较远的像素将相互影响,从而使更大的区域中足够相似的颜色获取相同的颜色。当d>0时,d指定了邻域大小且与sigmaSpace无关,否则d正比于sigmaSpace. -
返回值dst :
-
示例:略
5.形态学操作
opencv常见用法参见:
腐蚀膨胀: https://www.cnblogs.com/miaorn/p/12288661.html
BorderTyper: https://blog.csdn.net/weixin_41049188/article/details/91349314
形态学处理: https://blog.csdn.net/qq_40962368/article/details/81276820?utm_source=distribute.pc_relevant.none-task
5.1腐蚀
(1) cv2.getStructuringElement(shape, ksize[, anchor]) -> retval
-
功能:返回用于形态学操作的指定大小和形状的结构元素
进行腐蚀操作的核,不仅可以是矩形,还可以是十字形和椭圆形,opencv提供getStructuringElement()函数来获得核, 其参数如下 -
参数:
shape:核的形状 cv2.MORPH_RECT: 矩形 cv2.MORPH_CROSS: 十字形(以矩形的锚点为中心的十字架) cv2.MORPH_ELLIPSE:椭圆(矩形的内切椭圆) ksize: 核的大小,矩形的宽,高格式为(width,height) anchor: 核的锚点,默认值为(-1,-1),即核的中心点 -
返回值retval :核或者成为结构化元素
-
示例:
# 十字形
>>> import cv2
>>> kernel = cv2.getStructuringElement(cv2.MORPH_CROSS,(5,5))
>>> kernel
array([[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0],
[1, 1, 1, 1, 1],
[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0]], dtype=uint8)
# 矩形
>>> cv2.getStructuringElement(cv2.MORPH_RECT,(5,5))
array([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]], dtype=uint8)
# 椭圆形
>>> cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(5,5))
array([[0, 0, 1, 0, 0],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[0, 0, 1, 0, 0]], dtype=uint8)
# 可以用numpy得到相同的结构
>>> kernel = np.ones((5,5),np.uint8)
>>> kernel
array([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]], dtype=uint8)
(2) dst = cv2.erode(src, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]])
-
功能:图像腐蚀操作
原理:卷积核沿着图像滑动,如果与卷积核对应的原图像的所有像素值都是 1,那么中心元素就保持原来的像素值,否则就变为零。
效果:前景物体会变小,整幅图像的白色区域会减少。
用途:去除白噪声;断开两个连在一块的物体等。 -
参数:
src 所需要腐蚀的图像,图像的通道数可以任意, 但要求图像深度必须是CV_8U , CV_16U , CV_16S , CV_32F , CV_64F中的一种kernel代表腐蚀操作时所采用的结构类型, 可以自定义生成, 也可以通过函数,cv2.getStructuringEleMent()
interations腐蚀操作迭代的次数, 默认为1
dst 为腐蚀后输出的目标图像,与原始图像的类型和大小一样,一般不用填
anchor 代表结构中锚点的位置,默认为( - 1 , - 1 ) 即核的中心位置
borderValue 边界填充值,当需要填充特定值时
borderType代表边界样式,决定在图像发生几何变换或者滤波操作(卷积)时边沿像素的处理方式;当结构元为3x3时处理边界时会出现有一行未处理,当为
5x5时有两行, 参见下面边界处理方式:
类型 说明 cv2.BORDER_CONSTANT iiiiii|abcdefgh|iiiiii 特定值i cv2.BORDER_REPLICATE aaaaaa|abcdefgh| hhhhhh cv2.BORDER_REFLECT fedcba|abcdefgh|hgfedcb cv2.BORDER_WRAP cdefgh|abcdefgh|abcdefg cv2.BORDER_REFLECT_101 gfedcb|abcdefgh| gfedcba cv2.BORDER_TRANSPARENT uvwxyz|abcdefgh| ijklmno cv2.BORDER_REFLECT101 与cv2.BORDER_REFLECT_101 相同 cv2.BORDER_DEFAULT 与cv2.BORDER_REFLECT_101 相同 cv2.BORDER_ISOLATED 不考虑ROI之外的区域以上的说明中的竖线中间的字母即代表图像的像素点, 而两边的字母即代表边界样式和像素点之间的关系
例如cv2.BORDER_CONSTANT即是特定值处理, 而cv2.BORDER_REPLICATE 即是将边缘样式处理为图像边缘的像素点 -
返回值dst :腐蚀后图像
-
示例:
img = cv2.imread('lena.png')
kernel = np.ones((5,5), np.uint8)
# kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(5,5))
erosion = cv2.erode(img, kernel, iterations=1) #腐蚀
5.2 膨胀
(3) dst = cv2.dilate(src,kernel,anchor,iterations,borderType,borderValue)
-
功能:图像膨胀
原理:与腐蚀相反,与卷积核对应的原图像的像素值中只要有一个是 1,中心元素的像素值就是 1。 效果:增加图像中的白色区域(前景)。 用途:可以用来连接两个分开的物体。 -
参数:
src: 输入图像对象矩阵,为二值化图像 kernel:进行腐蚀操作的核,可以通过函数getStructuringElement()获得 anchor:锚点,默认为(-1,-1) iterations:腐蚀操作的次数,默认为1 borderType: 边界种类 borderValue:边界值 -
返回值dst :膨胀后的图像
-
示例:
import cv2 as cv
img = cv.imread(r"C:\Users\Administrator\Desktop\logo.png")
img_cvt = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
ret,img_thr = cv.threshold(img_cvt,200,255,cv.THRESH_BINARY_INV)
kernel = cv.getStructuringElement(cv.MORPH_RECT,(3,5))
dst = cv.dilate(img_thr,kernel,iterations=1)
5.3 形态学操作
开运算:先进行腐蚀操作,后进行膨胀操作,主要用来去除一些较亮的噪声点,即先腐蚀掉不要的部分,再进行膨胀。
闭运算:先进行膨胀操作,后进行腐蚀操作,主要用来去除一些较暗的噪声点,关闭一些物体上的小洞,或者黑色的小孔。
形态学梯度:膨胀运算结果减去腐蚀运算结果,可以拿到轮廓信息。
顶帽运算:原图像减去开运算结果,得到噪声图像。
黑帽运算:原图像减去闭运算结果,得到前景中的小黑点或者内部小孔。
进行开运算,闭运算,顶帽运算,底帽运算,形态学梯度,opencv提供了一个统一的函数cv2.morphologyEx(),其对应参数如下:
(4) dst = cv2.morphologyEx(src, op, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]])
- 功能:形态学操作
- 参数:
-
src: 输入图像对象矩阵,为二值化图像 op: 形态学操作类型 cv2.MORPH_OPEN 开运算 cv2.MORPH_CLOSE 闭运算 cv2.MORPH_GRADIENT 形态梯度 cv2.MORPH_TOPHAT 顶帽运算 cv2.MORPH_BLACKHAT 黑帽运算 kernel:进行腐蚀操作的核,可以通过函数getStructuringElement()获得 anchor:锚点,默认为(-1,-1) iterations:腐蚀操作的次数,默认为1 borderType: 边界种类 borderValue:边界值 - 返回值dst :经过形态学操作后的图像
- 示例:
import cv2 as cv
import matplotlib.pyplot as plt
img = cv.imread(r"C:\Users\Administrator\Desktop\logo.png")
img_cvt = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
ret,img_thr = cv.threshold(img_cvt,200,255,cv.THRESH_BINARY_INV)
kernel = cv.getStructuringElement(cv.MORPH_RECT,(3,5))
open = cv.morphologyEx(img_thr,cv.MORPH_OPEN,kernel,iterations=1)
close = cv.morphologyEx(img_thr,cv.MORPH_CLOSE,kernel,iterations=1)
gradient = cv.morphologyEx(img_thr,cv.MORPH_GRADIENT,kernel,iterations=1)
tophat = cv.morphologyEx(img_thr,cv.MORPH_TOPHAT,kernel,iterations=1)
blackhat = cv.morphologyEx(img_thr,cv.MORPH_BLACKHAT,kernel,iterations=1)
images=[img_thr,open,close,gradient,tophat,blackhat]
titles=["img_thr","open","close","gradient","tophat","blackhat"]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],"gray")
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
6.图像分割(梯度、边缘检测)
opencv常见用法参见:
阈值化分割:https://www.cnblogs.com/ZFJ1094038955/p/12027836.html
梯度与边缘检测: https://blog.csdn.net/GiffordY/article/details/92191697?depth_1.utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
canny算子: https://www.cnblogs.com/techyan1990/p/7291771.html
梯度和边缘检测:https://www.jianshu.com/p/eacaa97cb2f7
------------------------------图像阈值分割-------------------------------
6.1 阈值分割
(1) retval, dst = cv2.threshold(src, thresh, maxval, type[, dst])
- 功能:阈值分割
- 参数:
-
src:表示的是图片源 thresh:表示的是阈值(起始值) maxval:表示的是最大值 type:表示的是这里划分的时候使用的是什么类型的算法,常用值为0(cv2.THRESH_BINARY) cv2.THRESH_BINARY:二值阈值化 cv2.THRESH_BINARY_INV:反二值阈值化 cv2.THRESH_TRUNC: 截断阈值化 cv2.THRESH_TOZERO:阈值化为0 cv2.THRESH_TOZERO_INV:反阈值化为0 cv2.THRESH_OTSU:大津算法 cv2.THRESH_TRIANGLE, cv2.THRESH_MASK

- 返回值retval, dst:阈值,分割后的图像
- 示例:
import cv2
a=cv2.imread("image\\lena512.bmp",cv2.IMREAD_UNCHANGED)
#注意原始图像的类型,必须是8位单通道图像,彩色图像无意义
r,b=cv2.threshold(a,127,255,cv2.THRESH_BINARY_INV)
----------------------------图像边缘检测---------------------------------
图像边缘一般都是通过对图像进行梯度运算来实现的。图像梯度的最重要性质是,梯度的方向在图像灰度最大变化率上,它恰好可以反映出图像边缘上的灰度变化 。
我们一般将图像看成二维离散函数,图像梯度其实就是这个二维离散函数的求导。
6.1 sobel算子
(1) dst = cv2.Sobel(src, ddepth, dx, dy[, dst[, ksize[, scale[, delta[, borderType]]]]])
-
功能:利用Sobel算子进行图像梯度计算
-
参数:
-
src:输入图像 ddepth: 输出图像的深度(可以理解为数据类型),-1表示与原图像相同的深度 注1: 通常情况下,可以将该参数值设置为-1,让处理结果与原始图片保持一致。但是实际操作中,计算梯度值可能出现负数。通常处理图像是np.uint8类型,如果结果是该类型,所有负数会自动截断为0,发生信息丢失。 所以,通常计算时,使用更高的数据类型cv2.CV_64F, 取绝对值后,在转换为np.uint8(cv2.CV_8U)类型。还需要使用下面函数: -
dx,dy:当组合为dx=1,dy=0时求x方向的一阶导数,当组合为dx=0,dy=1时求y方向的一阶导数(如果同时为1,通常得不到想要的结果) 计算x方向梯度 :【dx = 1, dy = 0】 计算y方向梯度 :【dx = 0, dy = 1】 ksize:(可选参数)Sobel算子的大小,必须是1,3,5或者7,默认为3。求X方向和Y方向一阶导数时,卷积核分别为: scale:(可选参数)将梯度计算得到的数值放大的比例系数,效果通常使梯度图更亮,默认为1 delta:(可选参数)在将目标图像存储进多维数组前,可以将每个像素值增加delta,默认为0 borderType:(可选参数)决定图像在进行滤波操作(卷积)时边沿像素的处理方式,默认为BORDER_DEFAULT
实际计算x-y方向的sobel结果过程:
--------方式1(不推荐):dx = 1, dy = 1
--------方式2(推荐):
分别计算dx和dy后相加,eg:
1)dx=cv2.Sobel(src,ddepth,1,0)
2)dy=cv2.Soble(src.ddepth,0,1)
3)dst=|dx| + |dy| — 防止溢出一般乘一个系数:
dst=|dx| * 0.5 + |dy| * 0.5 ---- 可以用注2函数计算:
注2:cv2.addWeighted,相当于:dst = (src1 * alpha + src2 * beta) + gamma
eg: cv2.addWeighted(src1,0.5,src2,0.5,0)
配合cv2.convertScalerAbs函数(求取绝对值函数),可以实现soble算子,在x,y放上上的和,即:dst = (|src1| * alpha + |src2| * beta) + gamma
dst=cv2.addWeighted(src1,alpha,src2,beta,gamma)
* src1:原图1
* alpha:原图1的系数
* src2:原图2
* beta:原图2的系数
* gamma:修正值
dst = cv2.convertScalerAbs(src, [,alpha[,beta]])
* 作用:将原始图像src转换为256色位图(负数->绝对值)
* 公式: 目标图像=调整(原始图像*alpha+beta)
* 直接调整,(不用alpha,beta)eg:目标图像=cv2.convertScalerAbs(原始图像)
注3:
Scharr相关参数处理内容和sobel相同。另外 对于Sobel算子,ksize = -1与Schar是等价的, 即:
dst = cv2.Scharr(src, ddepth, dx, dy) === dst = cv2.Sobel(src, ddepth, dx, dy, -1)
- 返回值dst :经过sobel梯度算子计算处理的图片
- 示例:参见汇总
6.2 scharr算子
一般认为scharr算子的边缘检测精确度比sobel要优,相当于改进版。
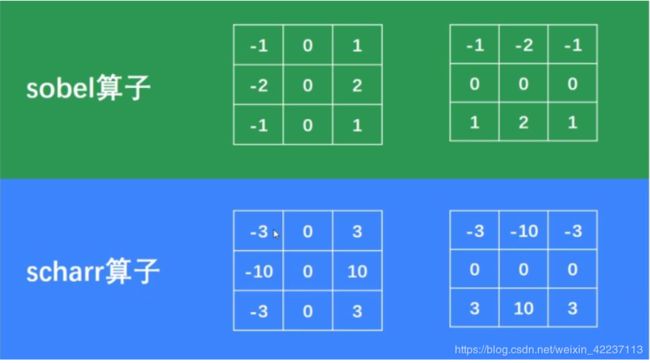
(2) dst = cv2.Scharr(src, ddepth, dx, dy[, dst[, scale[, delta[, borderType]]]])
- 功能:同sobel
- 参数:基本同soble
- 返回值dst :经过scharr梯度算子计算处理的图片
- 示例:参见汇总
6.3 Laplacian算子
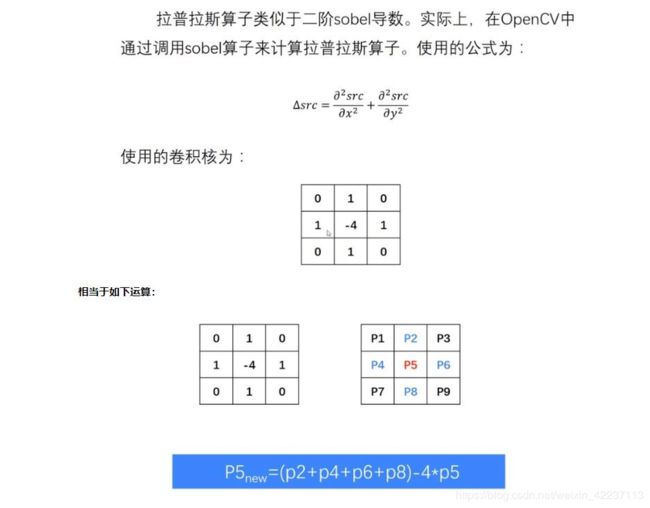
(3) dst = cv2.Laplacian(src, ddepth[, dst[, ksize[, scale[, delta[, borderType]]]]])
- 功能:二阶导数梯度算子
- 参数:基本同soble
- 返回值dst :经过Laplacian梯度算子计算处理的图片
- 示例:参见汇总
sobel/scharr都是一阶倒数的算子;laplacian是二阶求导算子,所以具有不变性

6.4 Canny算子
Canny边缘检测基本原理:
图象边缘检测必须满足两个条件:一能有效地抑制噪声;二必须尽量精确确定边缘的位置。
根据对信噪比与定位乘积进行测度,得到最优化逼近算子。这就是Canny边缘检测算子。
类似与Marr(LoG)边缘检测方法,也属于先平滑后求导数的方法。
Canny 的目标是找到一个最优的边缘检测算法,最优边缘检测的含义是:
好的检测 - 算法能够尽可能多地标识出图像中的实际边缘。
好的定位 - 标识出的边缘要尽可能与实际图像中的实际边缘尽可能接近。
最小响应 - 图像中的边缘只能标识一次,并且可能存在的图像雜訊不应标识为边缘。
- 1) 使用高斯函数的一阶导数同时完成平滑和微分;
- 2) 计算梯度(幅值和方向);
- 3) 梯度幅值进行非极大值抑制;
注意:此时选择的是相同方向的、临近像素梯度值进行比较,选择其中最大的梯度值保留;
如果阈值都比较小,图像相对细节比较多;如果都比较大,细节会比较少
-
(4) 自动边缘连接:
梯度值>高阈值 ,保留;
梯度值<低阈值,舍弃;
低阈值< 梯度值 < 高阈值, 选择和高阈值相连的;保留,间断或者不相连的,社区
(4) dst = cv2.Canny(image, threshold1, threshold2[, edges[, apertureSize[, L2gradient]]])
- 功能:边缘检测
- 参数:
-
image:是需要处理的原图像,该图像必须为单通道的灰度图; threshold1: 阈值1; threshold2: 阈值2。 其中较大的阈值2用于检测图像中明显的边缘,但一般情况下检测的效果不会那么完美,边缘检测出来是断断续续的。所以这时候用较小的第一个阈值用于将这些间断的边缘连接起来. apertureSize: 就是Sobel算子的大小。 L2gradient: 是一个布尔值,如果为真,则使用更精确的L2范数进行计算(即两个方向的倒数的平方和再开放),否则使用L1范数(直接将两个方向导数的绝对值相加)
dst = cv2.Canny(dx, dy, threshold1, threshold2[, edges[, L2gradient]])
也可以使用,同样作用
不同点: dx = soble_x, dy = soble_y
具体例子可以参见:https://www.jianshu.com/p/eacaa97cb2f7
- 返回值dst :图像边缘
- 示例:参见汇总
6.5 边缘检测代码汇总
#Q2.边缘检测
import cv2
# 滤波、变灰度和直接读取灰度图片作用一样
# img_org = cv2.imread("./lena.jpg")
# img_gauss = cv2.GaussianBlur(img_org, (3,3), 0)
# img_size = cv2.resize(img_gauss,(int(img_gauss.shape[0]*0.5),int(img_gauss.shape[1]*0.6)))
# img = cv2.cvtColor(img_size, cv2.COLOR_BGR2GRAY)
# 直接读取灰度图片
img_org = cv2.imread("./lena.jpg",cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img_org,(int(img_org.shape[0]*0.5),int(img_org.shape[1]*0.6)))
# sobel 边缘检测
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0)
sobely = cv2.Sobel(img,cv2.CV_64F,0,1)
sobelx_abs = cv2.convertScaleAbs(sobelx) #转回uint8
sobely_abs = cv2.convertScaleAbs(sobely)
sobelxy = cv2.addWeighted(sobelx,0.5,sobely,0.5,0)
# sobel wrong
sobel_xy = cv2.Sobel(img, -1, 1, 1)
# scharr 边缘检测
scharrx = cv2.Scharr(img,cv2.CV_64F,1,0)
scharry = cv2.Scharr(img,cv2.CV_64F,0,1)
scharrx_abs = cv2.convertScaleAbs(scharrx)
scharry_abs = cv2.convertScaleAbs(scharry)
scharrxy = cv2.addWeighted(scharrx,0.5,scharry,0.5,0)
# laplacian算子
laplacian = cv2.Laplacian(img, cv2.CV_64F)
la_abs = cv2.convertScaleAbs(laplacian)
# Cannny算子
# canny = cv2.Canny(img, 100, 200)#大阈值
# canny = cv2.Canny(img, 50, 60)#小阈值
canny = cv2.Canny(img, 50, 120)
cv2.imshow("original",img)
cv2.imshow("Sobel",sobelxy)
cv2.imshow("Sobel_wrong", sobel_xy)
# sobel_x -> 让图片信息丢失,只保留x轴信息
cv2.imshow("soble_x",cv2.Sobel(img,-1,1,0))
cv2.imshow("Scharr",scharrxy)
cv2.imshow("Laplacian", la_abs)
cv2.imshow("Canny",canny)
cv2.waitKey()
cv2.destroyAllWindows()
汇总效果图
7.图像金字塔、轮廓检测、Hough变换
opencv常见用法参见:
图像金字塔 : https://www.cnblogs.com/XJT2018/p/9946444.html
高斯、拉普拉斯图像金字塔: https://blog.csdn.net/poem_qianmo/article/details/26157633
轮廓检测 : https://blog.csdn.net/Easen_Yu/article/details/89365497
轮廓api : https://blog.csdn.net/dz4543/article/details/80655067
https://www.jianshu.com/p/9c186c3bdfcc
hough变换: https://blog.csdn.net/yukinoai/article/details/88366564
------------------------------图像金字塔---------------------------------
两种类型的金字塔:
①高斯金字塔:用于下采样。高斯金字塔是最基本的图像塔。原理:首先将原图像作为最底层图像G0(高斯金字塔的第0层),利用高斯核(5*5)对其进行卷积,然后对卷积后的图像进行下采样(去除偶数行和列)得到上一层图像G1,将此图像作为输入,重复卷积和下采样操作得到更上一层图像,反复迭代多次,形成一个金字塔形的图像数据结构,即高斯金字塔。
②拉普拉斯金字塔:用于重建图像,也就是预测残差,对图像进行最大程度的还原。比如一幅小图像重建为一幅大图,原理:用高斯金字塔的每一层图像减去其上一层图像上采样并高斯卷积之后的预测图像,得到一系列的差值图像即为 LP 分解图像。
每层的图像公式可以表示如下:
Li = Gi - PyrUp(PyrDown(Gi))
其中:
Gi: 第i层的原始图像
Li:第i层的拉普拉斯金字塔图像
两种类型的采样:
①上采样:就是图片放大(所谓上嘛,就是变大),使用PryUp函数。 上采样步骤:先将图像在每个方向放大为原来的两倍,新增的行和列用0填充,再使用先前同样的内核与放大后的图像卷积,获得新增像素的近似值。
②下采样:就是图片缩小(所谓下嘛,就是变小),使用PryDown函数。下采样将步骤:先对图像进行高斯内核卷积 ,再将所有偶数行和列去除。
总之,上、下采样都存在一个严重的问题,那就是图像变模糊了,因为缩放的过程中发生了信息丢失的问题。要解决这个问题,就得用拉普拉斯金字塔。
7.1 下采样
(1) dst = cv2.pyrDown(src[, dst[, dstsize[, borderType]]])
- 功能:图像金字塔下采样函数
- 参数:
-
src参数 表示输入图像。 dst参数 表示输出图像,它与src类型、大小相同。 dstsize参数 表示升采样之后的目标图像的大小。它是有默认值的,如果我们调用函数的时候不指定第三个参数,那么这个值是按照 Size((src.cols+1)/2, (src.rows+1)/2) 计算的。 而且不管你自己如何指定这个参数,一定必须保证满足以下关系式:|dstsize.width * 2 - src.cols| ≤ 2; |dstsize.height * 2 - src.rows| ≤ 2。也就是说降采样的意思其实是把图像的尺寸缩减一半,行和列同时缩减一半。 borderType参数表示表示图像边界的处理方式,参见cv2.erode - 返回值dst :下采样后的图像
- 示例:
import cv2
o=cv2.imread("image\\girl.bmp")
down=cv2.pyrDown(o)
up=cv2.pyrUp(down)
cv2.imshow("original",o)
cv2.imshow("down",down)
cv2.imshow("up",up)
cv2.waitKey()
cv2.destroyAllWindows()
7.2 上采样
(2 ) dst = pyrUp(src[, dst[, dstsize[, borderType]]])
- 功能:上采样函数
- 参数:
-
src参数 表示输入图像。 dst参数 表示输出图像,它与src类型、大小相同。 dstsize参数 表示降采样之后的目标图像的大小。在默认的情况下,这个尺寸大小是按照 Size(src.cols*2, (src.rows*2) 来计算的。 如果你自己要指定大小,那么一定要满足下面的条件: |dstsize.width - src.cols * 2| ≤ (dstsize.width mod 2); //如果width是偶数,那么必须dstsize.width是src.cols的2倍 |dstsize.height - src.rows * 2| ≤ (dstsize.height mod 2); borderType参数 表示表示图像边界的处理方式。参见cv2.erode - 返回值dst :上采样的图片
- 示例:同cv2.pyrDown
------------------------------图像轮廓---------------------------------
7.2 图像轮廓检测
(3) image, contours, hierarchy = cv2.findContours(image, mode, method[, contours[, hierarchy[, offset]]])
- 功能:findContours函数该函数接受二值图作为参数,根据参数,可查找物体外轮廓、内外轮廓,保存轮廓点、压缩等等…
- 参数:
-
image 代表输入的图片。注意输入的图片必须为二值图片。若输入的图片为彩色图片,必须先进行灰度化和二值化。 mode 表示轮廓的检索模式,有4种: cv2.RETR_EXTERNAL 表示只检测外轮廓。 cv2.RETR_LIST 检测的轮廓不建立等级关系。 cv2.RETR_CCOMP 建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息。如果内孔内还有一个连通物体,这个物体的边界也在顶层。 cv2.RETR_TREE 建立一个等级树结构的轮廓。 method 为轮廓的近似办法,有4种: cv2.CHAIN_APPROX_NONE 存储所有的轮廓点,相邻的两个点的像素位置差不超过1,即max(abs(x1-x2), abs(y2-y1))<=1。 cv2.CHAIN_APPROX_SIMPLE 压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个 矩形轮廓只需4个点来保存轮廓信息。 cv2.CHAIN_APPROX_TC89_L1 和 cv2.CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法。 offset: 每个轮廓点位移量。如果从图像ROI区域中提取轮廓,然后在整个图像中对其进行分析时,这将非常有用。 - 返回值 :
image, 修改后的图像(二值化后的图像)
contours, 轮廓点集
hierarchy,各层轮廓的拓扑信息 - 示例:参见cv2.drawContours
(4) image = cv2.drawContours(image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[, maxLevel[, offset ]]]]])
- 功能:画出轮廓图像
- 参数:
-
第一个参数是指明在哪幅图像上绘制轮廓; 第二个参数是轮廓本身,在Python中是一个list。 第三个参数指定绘制轮廓list中的哪条轮廓,如果是-1,则绘制其中的所有轮廓。后面的参数很简单。其中thickness表明轮廓线的宽度,如果是-1(cv2.FILLED),则为填充模式 - 返回值 image :轮廓图像
- 示例:
import cv2
o = cv2.imread('image\\contours.bmp')
gray = cv2.cvtColor(o,cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray,127,255,cv2.THRESH_BINARY)
image,contours, hierarchy = cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
# 底面制作一个白幕
temp = np.ones(binary.shape, np.uint8)*255
r=cv2.drawContours(temp,contours,-1,(0,0,255),6)
# 修改图像后,图像不可变,所以制作一个备份
# temp = o.copy()
# r=cv2.drawContours(temp,contours,-1,(0,0,255),6)
cv2.imshow("original",o)
cv2.imshow("contours",r)
cv2.waitKey()
cv2.destroyAllWindows()
------------------------------直线、圆形检测---------------------------------
7.2 Hough变换
(5)cv2.HoughCircles(image, method, dp, minDist, circles, param1, param2, minRadius, maxRadius)
-
功能:hough变换圆形检测
-
参数:
-
image:输入图像 ,必须是8位的单通道灰度图像 method:定义检测图像中圆的方法。目前唯一实现的方法是cv2.HOUGH_GRADIENT。 dp:累加器分辨率与图像分辨率的反比。dp获取越大,累加器数组越小。 minDist:检测到的圆的中心,(x,y)坐标之间的最小距离。如果minDist太小,则可能导致检测到多个相邻的圆。如果minDist太大,则可能导致很多圆检测不到。 circles:输出结果,发现的圆信息 param1:用于处理边缘检测的梯度值方法。 param2:cv2.HOUGH_GRADIENT方法的累加器阈值。阈值越小,检测到的圈子越多。 minRadius:最小半径 maxRadius:最大半径 -
返回值dst :
-
示例:
import cv2
# 载入并显示图片
img = cv2.imread('test.jpg')
cv2.imshow('img', img)
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 输出图像大小,方便根据图像大小调节minRadius和maxRadius
print(img.shape)
# 霍夫变换圆检测
circles = cv2.HoughCircles(gray, cv2.HOUGH_GRADIENT, 1,100, param1=100, param2=30, minRadius=5, maxRadius=300)
# 输出返回值,方便查看类型
print(circles)
print(circles[0])
# 输出检测到圆的个数
print(len(circles[0]))
print('------------------------------')
# 根据检测到圆的信息,画出每一个圆
for circle in circles[0]:
# 圆的基本信息
print(circle[2])
# 坐标行列
x = int(circle[0])
y = int(circle[1])
# 半径
r = int(circle[2])
# 在原图用指定颜色标记出圆的位置
img = cv2.circle(img, (x, y), r, (0, 0, 255), 3)
img = cv2.circle(img, (x, y), 2, (255, 255, 0), -1)
# 显示新图像
cv2.imshow('res', img)
# 按任意键退出
cv2.waitKey(0)
cv2.destroyAllWindows()
(6)cv2.HoughLines(image, rho, theta, threshold, lines, sen, stn, min_theta, max_theta)
- 功能:hough变换直线检测
- 参数:
-
image:输入图像,8-bit灰度图像 rho:生成极坐标时候的像素扫描步长 theta:生成极坐标时候的角度步长 threshold:阈值,只有获得足够交点的极坐标点才被看成是直线 lines:返回值,极坐标表示的直线(ρ, θ) sen:是否应用多尺度的霍夫变换,如果不是设置0表示经典霍夫变换 stn:是否应用多尺度的霍夫变换,如果不是设置0表示经典霍夫变换 min_theta:表示角度扫描范围最小值 max_theta:表示角度扫描范围最大值 - 返回值dst :
- 示例:
import cv2
import numpy as np
from matplotlib import pyplot as plt
def nothing(x): # 滑动条的回调函数
pass
src = cv2.imread('test19.jpg')
srcBlur = cv2.GaussianBlur(src, (3, 3), 0)
gray = cv2.cvtColor(srcBlur, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 50, 150, apertureSize=3)
WindowName = 'Approx' # 窗口名
cv2.namedWindow(WindowName, cv2.WINDOW_AUTOSIZE) # 建立空窗口
cv2.createTrackbar('threshold', WindowName, 0, 60, nothing) # 创建滑动条
while(1):
img = src.copy()
threshold = 100 + 2 * cv2.getTrackbarPos('threshold', WindowName) # 获取滑动条值
lines = cv2.HoughLines(edges, 1, np.pi/180, threshold)
for line in lines:
rho = line[0][0]
theta = line[0][1]
a = np.cos(theta)
b = np.sin(theta)
x0 = a*rho
y0 = b*rho
x1 = int(x0 + 1000*(-b))
y1 = int(y0 + 1000*(a))
x2 = int(x0 - 1000*(-b))
y2 = int(y0 - 1000*(a))
cv2.line(img, (x1, y1), (x2, y2), (0, 0, 255), 2)
cv2.imshow(WindowName, img)
k = cv2.waitKey(1) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
这种方法仅仅是一条直线都需要两个参数,这需要大量的计算。Probabilistic_Hough_Transform 是对霍夫变换的一种优化。
它 不会对每一个点都进行计算,而是从一幅图像中随机选取(是不是也可以使用 图像金字塔呢?)一个点集进行计算,对于直线检测来说这已经足够了。
但是 使用这种变换我们必须要降低阈值(总的点数都少了,阈值肯定也要小呀!)。
函数如下:
(7)cv2.HoughLinesP(image, rho, theta, threshold, lines, minLineLength, maxLineGap)
-
功能:直线检测
-
参数:
-
src:输入图像,必须8-bit的灰度图像 rho:生成极坐标时候的像素扫描步长 theta:生成极坐标时候的角度步长 threshold:阈值,只有获得足够交点的极坐标点才被看成是直线 lines:输出的极坐标来表示直线 minLineLength:最小直线长度,比这个短的线都会被忽略。 maxLineGap:最大间隔,如果小于此值,这两条直线 就被看成是一条直线。 -
返回值dst :
-
示例:
import cv2
import numpy as np
from matplotlib import pyplot as plt
def nothing(x): # 滑动条的回调函数
pass
src = cv2.imread('test19.jpg')
srcBlur = cv2.GaussianBlur(src, (3, 3), 0)
gray = cv2.cvtColor(srcBlur, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 50, 150, apertureSize=3)
WindowName = 'Approx' # 窗口名
cv2.namedWindow(WindowName, cv2.WINDOW_AUTOSIZE) # 建立空窗口
cv2.createTrackbar('threshold', WindowName, 0, 100, nothing) # 创建滑动条
cv2.createTrackbar('minLineLength', WindowName, 0, 100, nothing) # 创建滑动条
cv2.createTrackbar('maxLineGap', WindowName, 0, 100, nothing) # 创建滑动条
while(1):
img = src.copy()
threshold = cv2.getTrackbarPos('threshold', WindowName) # 获取滑动条值
minLineLength = 2 * cv2.getTrackbarPos('minLineLength', WindowName) # 获取滑动条值
maxLineGap = cv2.getTrackbarPos('maxLineGap', WindowName) # 获取滑动条值
lines = cv2.HoughLinesP(edges, 1, np.pi/180, threshold, minLineLength, maxLineGap)
for line in lines:
x1 = line[0][0]
y1 = line[0][1]
x2 = line[0][2]
y2 = line[0][3]
cv2.line(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.imshow(WindowName, img)
k = cv2.waitKey(1) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
8.图像直方图
图像直方图
直方图是对图像像素的统计分布,它统计了每个像素(0到L-1)的数量。
直方图均衡化就是将原始的直方图拉伸,使之均匀分布在全部灰度范围内,从而增强图像的对比度。
直方图均衡化的中心思想是把原始图像的的灰度直方图从比较集中的某个区域变成在全部灰度范围内的均匀分布。
opencv常见用法参见:
hist实例: https://www.cnblogs.com/lfri/p/12251387.html
hist官方: https://matplotlib.org/api/_as_gen/matplotlib.pyplot.hist.html
calHist https://www.jianshu.com/p/bd12c4273d7d
import matplotlib.pyplot as plt
python 自带的画图工具
常用函数:
plt.hist / plt.subplot / plt.imshow等
(1) plt.hist(x, bins=None, range=None, density=None, weights=None, cumulative=False, bottom=None, histtype=‘bar’, align=‘mid’, orientation=‘vertical’, rwidth=None, log=False, color=None, label=None, stacked=False, normed=None, *, data=None, **kwargs)
-
功能:可以用来画图像直方图
-
参数:
-
x:指定要绘制直方图的数据;输入值,这需要一个数组或者一个序列,不需要长度相同的数组。 bins:指定直方图条形的个数; range:指定直方图数据的上下界,默认包含绘图数据的最大值和最小值; density:布尔,可选。如果"True",返回元组的第一个元素将会将计数标准化以形成一个概率密度,也就是说,直方图下的面积(或积分)总和为1。这是通过将计数除以数字的数量来实现的观察乘以箱子的宽度而不是除以总数数量的观察。如果叠加也是“真实”的,那么柱状图被规范化为1。(替代normed) weights:该参数可为每一个数据点设置权重; cumulative:是否需要计算累计频数或频率; bottom:可以为直方图的每个条形添加基准线,默认为0; histtype:指定直方图的类型,默认为bar,除此还有’barstacked’, ‘step’, ‘stepfilled’; align:设置条形边界值的对其方式,默认为mid,除此还有’left’和’right’; orientation:设置直方图的摆放方向,默认为垂直方向; rwidth:设置直方图条形宽度的百分比; log:是否需要对绘图数据进行log变换; color:设置直方图的填充色; label:设置直方图的标签,可通过legend展示其图例; stacked:当有多个数据时,是否需要将直方图呈堆叠摆放,默认水平摆放; normed:是否将直方图的频数转换成频率;(弃用,被density替代) alpha:透明度,浮点数。 -
返回值:
n:直方图的值 bins:返回各个bin的区间范围 patches:返回每个bin的信息 -
示例:
import cv2
import matplotlib.pyplot as plt
o=cv2.imread("image\\boat.jpg")
cv2.imshow("original",o)
# ravel() 函数将多维array转化为一维array
plt.hist(o.ravel(),256)
cv2.waitKey()
cv2.destroyAllWindows()
(2) cv2.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]]) -> hist
-
功能:统计图像的直方图数据
-
参数:
第一个参数输入图像 第二个参数是用于计算直方图的通道,这里使用灰度图计算直方图,所以就直接使用第一个通道; 第三个参数是掩膜,是一个大小和image一样的np数组,其中把需要处理的部分指定为1,不需要处理的部分指定为0,一般设置为None,表示处理整幅图像 第四个参数是histSize,表示这个直方图分成多少份(即多少个直方柱)。 第五个参数是表示像素的范围,[0.0, 256.0]表示直方图能表示像素值从0.0到256的像素。 第六个,表示返回值hist,没有意义 accumulate是一个布尔值,用来表示直方图是否叠加。默认设置为False。 注意:除了mask,其他参数,都需要用[]括起来 -
返回值hist:直方图
-
示例:
import cv2
import numpy as np
img=cv2.imread("image\\boat.jpg")
hist = cv2.calcHist([img],[0],None,[256],[0,255])
print(type(hist))
print(hist.size)
print(hist.shape)
print(hist)
(3) bitwise_and(src1, src2[, dst[, mask]]) -> dst
-
功能:图像位与操作
-
参数:
src1:第一个输入矩阵 src2:第二个输入矩阵 dst:输出矩阵,和输入矩阵一样的尺寸和类型 mask:可选操作掩码,8位单通道数组,指定要更改的输出数组的元素。- 返回值dst :位与之后图像
-
扩展:
cv2.bitwise_not(src, dst, mask) 反转数组的每一位(异运算) cv2.bitwise_or(src1, src2, dst, mask) 计算两个矩阵每个元素析取(或运算) cv2.bitwise_xor(src1, src2, dst, mask) 计算两个矩阵每个元素的异或运算 -
示例:
import cv2
import numpy as np
import matplotlib.pyplot as plt
image=cv2.imread("image\\boat.bmp",0)
# 掩膜,选出ROI区域
mask=np.zeros(image.shape,np.uint8)
mask[200:400,200:400]=255
# 利用位与操作进行掩膜处理
mi=cv2.bitwise_and(image, mask)
cv2.imshow('original',image)
cv2.imshow('mask',mask)
cv2.imshow('mi',mi)
cv2.waitKey()
cv2.destroyAllWindows()
(4) dst = equalizeHist(src[, dst])
- 功能:直方图均衡化
- 参数:src:输入图像
- 返回值dst :均衡化后的目标图像
- 示例:略
9.傅里叶变换
关于傅里叶变换函数参考:
傅里叶变换 https://blog.csdn.net/Eastmount/article/details/89474405
import numpy as np
------------------------------numpu 傅里叶变换、逆变换------------------------------
常见函数:
#计算一维傅里叶变换
numpy.fft.fft(a, n=None, axis=-1, norm=None)
#计算二维的傅里叶变换
numpy.fft.fft2(a, n=None, axis=-1, norm=None)
#计算n维的傅里叶变换
numpy.fft.fftn()
#计算n维实数的傅里叶变换
numpy.fft.rfftn()
#返回傅里叶变换的采样频率
numpy.fft.fftfreq()
#将FFT输出中的直流分量移动到频谱中央
numpy.fft.shift()
傅里叶变换和逆变换
(1) np.fft.fft2(a, s=None, axes=(-2, -1), norm=None)
-
功能:实现傅里叶变换
-
参数:
a表示输入图像,阵列状的复杂数组 s表示整数序列,可以决定输出数组的大小。输出可选形状(每个转换轴的长度),其中s[0]表示轴0,s[1]表示轴1。对应fit(x,n)函数中的n,沿着每个轴,如果给定的形状小于输入形状,则将剪切输入。如果大于则输入将用零填充。如果未给定’s’,则使用沿’axles’指定的轴的输入形状 axes表示整数序列,用于计算FFT的可选轴。如果未给出,则使用最后两个轴。“axes”中的重复索引表示对该轴执行多次转换,一个元素序列意味着执行一维FFT norm包括None和ortho两个选项,规范化模式(请参见numpy.fft)。默认值为无 -
返回值dst :返回一个傅里叶变换图像频谱(复数数组)
-
示例:参见fftshift
(2) np.fft.fftshift(x, axes=None)
-
功能:一般用来将频率中心从左上角移动到中心处
-
参数:
x:输入array,输入数组。 axes:可填int或者tuple, 表示要移动的轴。默认值为None,即将移动所有轴。 -
返回值dst :移动后的数组
-
示例:
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('image\\lena.bmp',0)
# 图像的傅里叶变换
f = np.fft.fft2(img)
# 频谱中心化(初始频率中心在左上角,移动至中心处)
fshift = np.fft.fftshift(f)
# 频率幅度,即频谱
magnitude_spectrum = 20*np.log(np.abs(fshift))
plt.subplot(121)
plt.imshow(img, cmap = 'gray')
plt.title('original')
plt.axis('off')
plt.subplot(122)
plt.imshow(magnitude_spectrum, cmap = 'gray')
plt.title('result')
plt.axis('off')
plt.show()
常见函数
#实现图像逆傅里叶变换,返回一个复数数组
numpy.fft.ifft2(a, n=None, axis=-1, norm=None)
iimg = numpy.abs(逆傅里叶变换结果)
(3) np.fft.ifft2(a, s=None, axis=-1, norm=None)
- 功能:2维离散傅里叶逆变换
- 参数:与fft2相同
- 返回值dst :图像信息(复数形式)
- 示例:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
#读取图像
img = cv.imread('Lena.png', 0)
#傅里叶变换
f = np.fft.fft2(img)
fshift = np.fft.fftshift(f)
res = 20*np.log(np.abs(fshift))
#傅里叶逆变换
ishift = np.fft.ifftshift(fshift)
iimg = np.fft.ifft2(ishift)
iimg = np.abs(iimg)
#展示结果
plt.subplot(131), plt.imshow(img, 'gray'), plt.title('Original Image')
plt.axis('off')
plt.subplot(132), plt.imshow(res, 'gray'), plt.title('Fourier Image')
plt.axis('off')
plt.subplot(133), plt.imshow(iimg, 'gray'), plt.title('Inverse Fourier Image')
plt.axis('off')
plt.show()
(6)np.fft.ifftshift(x, axes=None)
- 功能:与fftshift互为逆运算,即将频谱中心从中心处移动到左上角处
- 参数:与ftshift基本相同
- 返回值dst :
- 示例:略
------------------------------opencv傅里叶变换、逆变换------------------------------
OpenCV 中相应的函数是cv2.dft()和用Numpy输出的结果一样,但是是双通道的。第一个通道是结果的实数部分,第二个通道是结果的虚数部分,并且输入图像要首先转换成 np.float32 格式。
(4) dst = cv2.dft(src, dst=None, flags=None, nonzeroRows=None)
-
功能:傅里叶变换
-
参数:
-
src表示输入图像,需要通过np.float32转换格式
-
dst表示输出图像,包括输出大小和尺寸
-
flags表示转换标记:
-
其中DFT _INVERSE执行反向一维或二维转换,而不是默认的正向转换;DFT _SCALE表示缩放结果,由阵列元素的数量除以它;_ROWS执行正向或反向变换输入矩阵的每个单独的行,该标志可以同时转换多个矢量,并可用于减少开销以执行3D和更高维度的转换等; DFT _COMPLEX_OUTPUT执行1D或2D实数组的正向转换,这是最快的选择,默认功能; DFT _REAL_OUTPUT执行一维或二维复数阵列的逆变换,结果通常是相同大小的复数数组,但如果输入数组具有共轭复数对称性,则输出为真实数组 -
nonzeroRows表示当参数不为零时,函数假定只有nonzeroRows输入数组的第一行(未设置)或者只有输出数组的第一个(设置)包含非零,
因此函数可以处理其余的行更有效率,并节省一些时间;这种技术对计算阵列互相关或使用DFT卷积非常有用
注意,由于输出的频谱结果是一个复数,需要调用cv2.magnitude()函数将傅里叶变换的双通道结果转换为0到255的范围。其函数原型如下:
-
cv2.magnitude(x, y)
x表示浮点型X坐标值,即实部
y表示浮点型Y坐标值,即虚部
最终输出结果为幅值,即:
- 返回值dst :
- 示例:
import numpy as np
import cv2
from matplotlib import pyplot as plt
#读取图像
img = cv2.imread('Lena.png', 0)
#傅里叶变换
dft = cv2.dft(np.float32(img), flags = cv2.DFT_COMPLEX_OUTPUT)
#将频谱低频从左上角移动至中心位置
dft_shift = np.fft.fftshift(dft)
#频谱图像双通道复数转换为0-255区间
result = 20*np.log(cv2.magnitude(dft_shift[:,:,0], dft_shift[:,:,1]))
#显示图像
plt.subplot(121), plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(result, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()
(5) dst = cv2.idft(src[, dst[, flags[, nonzeroRows]]])
-
功能:傅里叶逆变换
-
参数:
src表示输入图像,包括实数或复数 dst表示输出图像 flags表示转换标记 nonzeroRows表示要处理的dst行数,其余行的内容未定义(请参阅dft描述中的卷积示例) -
返回值dst :
-
示例:
# -*- coding: utf-8 -*-
import numpy as np
import cv2
from matplotlib import pyplot as plt
#读取图像
img = cv2.imread('Lena.png', 0)
#傅里叶变换
dft = cv2.dft(np.float32(img), flags = cv2.DFT_COMPLEX_OUTPUT)
dftshift = np.fft.fftshift(dft)
res1= 20*np.log(cv2.magnitude(dftshift[:,:,0], dftshift[:,:,1]))
#傅里叶逆变换
ishift = np.fft.ifftshift(dftshift)
iimg = cv2.idft(ishift)
res2 = cv2.magnitude(iimg[:,:,0], iimg[:,:,1])
#显示图像
plt.subplot(131), plt.imshow(img, 'gray'), plt.title('Original Image')
plt.axis('off')
plt.subplot(132), plt.imshow(res1, 'gray'), plt.title('Fourier Image')
plt.axis('off')
plt.subplot(133), plt.imshow(res2, 'gray'), plt.title('Inverse Fourier Image')
plt.axis('off')
plt.show()
------------------------------高通滤波------------------------------
频域滤波
目的:
图像增强、图像去噪、边缘检测、特征提取、压缩、加密等
方法:
图像进行傅里叶变换进入频域,修改傅里叶变换以达到特殊目的,然后计算傅里叶逆变换重新返回到图像域
说明:
越靠近频谱中心,频率越低,反之越高。多为图中颜色变化趋于一致地域。
低频对应图像内变化缓慢的灰度分量,由灰度尖锐过度造成,多为边缘
高频对应于图像内变化越来越快的灰度分量
低通滤波:衰减高频通过低频,将模糊一幅图像。
高通滤波:衰减低频通过高频,将增强尖锐细节,导致对比对下降。
高通滤波
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('image\\lena.bmp',0)
# 傅里叶变换
f = np.fft.fft2(img)
fshift = np.fft.fftshift(f)
rows, cols = img.shape
# 将低频过滤(中心位置的小正方形内像素全置位零)
crow,ccol = int(rows/2) , int(cols/2)
fshift[crow-30:crow+30, ccol-30:ccol+30] = 0
# 傅里叶反变换
ishift = np.fft.ifftshift(fshift)
iimg = np.fft.ifft2(ishift)
iimg = np.abs(iimg)
# 显示图像
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('original'),plt.axis('off')
plt.subplot(122),plt.imshow(iimg, cmap = 'gray')
plt.title('iimg'),plt.axis('off')
plt.show()
低通滤波
import numpy as np
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('image\\lena.bmp',0)
# 傅里叶变换
dft = cv2.dft(np.float32(img),flags = cv2.DFT_COMPLEX_OUTPUT)
dftShift = np.fft.fftshift(dft)
# 屏蔽高频
rows, cols = img.shape
crow,ccol = int(rows/2) , int(cols/2)
mask = np.zeros((rows,cols,2),np.uint8)
#两个通道,与频谱图像匹配
mask[crow-30:crow+30, ccol-30:ccol+30] = 1
fShift = dftShift*mask
# 傅里叶逆变换
ishift = np.fft.ifftshift(fShift)
iImg = cv2.idft(ishift)
iImg= cv2.magnitude(iImg[:,:,0],iImg[:,:,1])
# 显示图片
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('original'), plt.axis('off')
plt.subplot(122),plt.imshow(iImg, cmap = 'gray')
plt.title('result'), plt.axis('off')
plt.show()
10. 图像特征提取和描述
opencv常见用法参见:
harris角点: https://www.jianshu.com/p/14b92d3fd6f8
特征匹配: https://www.jianshu.com/p/ed57ee1056ab
SIFT / SURF / ORB: https://www.jianshu.com/p/14b92d3fd6f8?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
SIFT: https://blog.csdn.net/yukinoai/article/details/88912586#SIFT%E7%AE%97%E6%B3%95%E7%89%B9%E7%82%B9%E4%B8%8E%E6%AD%A5%E9%AA%A4
surf: https://blog.csdn.net/yukinoai/article/details/88914269
10.1 Harris角点检测
(1)min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(imgray,mask = mask)
- 功能:局部最大最小值
(2)dst = cv2.cornerHarris(src,blockSize,ksize,k)
-
功能:可以用来进行角点检测
-
参数:
* src,输入图像,即源图像,填Mat类的对象即可,且需为单通道8位或者浮点型图像。 * dst – 存储着Harris角点响应的图像矩阵,大小与输入图像大小相同,是一个浮点型矩阵。 * blockSize - 角点检测中要考虑的领域大小。 * ksize - Sobel 求导中使用的窗口大小 * k - Harris 角点检测方程中的自由参数,取值参数为 [0,04,0.06]. -
返回值dst :
存储着Harris角点响应的图像矩阵,大小与输入图像大小相同,是一个浮点型矩阵 -
示例:
import cv2
import numpy as np
img = cv2.imread("./chessboard.jpg")
cv2.imshow("original",img)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #图像灰度化
gray = np.float32(gray) #图像转换为float32
dst = cv2.cornerHarris(gray,2,3,0.04)#角点检测
#result is dilated for marking the corners, not important
dst = cv2.dilate(dst,None) #图像膨胀提升后续图像角点标注的清晰准确度
# 选择较大的相应函数R值的阈值,从而标定角点;阈值选择 [0.03,0.05]为佳
'''
img[dst>0.01*dst.max()]=[0,0,255]这段代码是什么意思吧 dst>0.01*dst.max()这么多返回是满足条件的dst索引值 根据索引值来设置这个点的颜色
这里是设定一个阈值 当大于这个阈值分数的都可以判定为角点
这里的dst其实就是一个个角度分数R组成的
当 λ 1 和 λ 2 都很大,并且 λ 1 ~λ 2 中的时,R 也很大,(λ 1 和 λ 2 中的最小值都大于阈值)说明这个区域是角点。
那么这里为什么要大于0.01×dst.max()呢 注意了这里R是一个很大的值 我们选取里面最大的R
然后 只要dst里面的值大于百分之一的R的最大值 那么此时这个dst的R值也是很大的 可以判定他为角点
也不一定要0.01 可以根据图像自己选取不过如果太小的话 可能会多圈出几个不同的角点
'''
img[dst>0.03*dst.max()]=[0,0,255] #角点位置用红色标记
cv2.imshow('Harris',img)
cv2.waitKey()
cv2.destroyAllWindows()
10.2 SIFT算法
SIFT算法分解为如下四步:
1.尺度空间极值检测:搜索所有尺度上的图像位置。通过高斯微分函数来识别潜在的对于尺度和旋转不变的兴趣点。
2.关键点定位:在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。
3.方向确定:基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
4.关键点描述:在每个关键点周围的邻域内,在选定的尺度上测量图像局部的梯度。这些梯度被变换成一种表示,
这种表示允许比较大的局部形状的变形和光照变化。
(3)cv2.drawKeypoints(image, keypoints, outImage[, color[, flags]]) -> outImage
-
功能:画出特征点
-
参数:
* image:原始图; * keypoints:特征点向量,元素为KeyPoint对象,包含特征点信息; * outImage:outImage,输出图片,一般不写 * color:特征点颜色; * flags:设置特征点需要不要画 cv2.DRAW_MATCHES_FLAGS_DEFAULT:默认值,只绘制特征点的坐标点,显示在图像上就是一个个小圆点,每个小圆点的圆心坐标都是特征点的坐标。 cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS:绘制特征点的时候绘制的是带有方向的圆,这种方法同时显示图像的坐标,size,和方向,是最能显示特征的一种绘制方式。 cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG:只绘制特征点的坐标点,显示在图像上就是一个个小圆点,每个小圆点的圆心坐标都是特征点的坐标。 cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINT:单点的特征点不被绘制 -
返回值dst :outImage
(4)cv2.xfeatures2d_SIFT.create([, nfeatures[, nOctaveLayers[, contrastThreshold[, edgeThreshold[, sigma]]]]]) -> retval
-
功能:创建sift对象
-
参数:
* nfeatures:默认为0,要保留的最佳特征的数量。 特征按其分数排名(在SIFT算法中按局部对比度排序) * nOctaveLayers:默认为3,金字塔每组(Octave)有多少层。 3是D. Lowe纸中使用的值。 * contrastThreshold:默认为0.04,对比度阈值,用于滤除半均匀(低对比度)区域中的弱特征。 阈值越大,检测器产生的特征越少。 * edgeThreshold:默认为10,用来过滤边缘特征的阈值。注意,它的意思与contrastThreshold不同,edgeThreshold越大,滤出的特征越少(保留更多特征)。 * sigma:默认为1.6,高斯金字塔中的σ。 如果使用带有软镜头的弱相机拍摄图像,则可能需要减少数量。 -
返回值dst :sift对象
(5)detectAndCompute(image, mask[, descriptors[, useProvidedKeypoints]]) -> keypoints,descriptors
-
功能:计算特征值和描述符
-
参数:
* image:输入图像 * mask:掩膜 * keypoints:输出特征点 * descriptors:输出描述符 * useProvidedKeypoints:是否使用提供的点,默认False -
返回值dst :特征点,特征描述
-
示例:
import cv2
import numpy as np
################## SIFT算子##################
"""
step1;构建初始图片
"""
# img_org = cv2.imread(r"D:\111111Python\AI\img_project\chapter2_homework\left12.jpg")
img_org = cv2.imread(r"D:\111111Python\AI\img_project\chapter2_homework\scences.jpg")
# 读取原图片的行、列、通道数
rows,cols,channels = img_org.shape
#沿着原图像顺指针旋转90度,并且缩减为原来的0.5
M = cv2.getRotationMatrix2D((cols/2, rows/2), 0, 0.5)
img_rot = cv2.warpAffine(img_org, M, (cols, rows))
# 转换成灰度图片
gray_org = cv2.cvtColor(img_org, cv2.COLOR_BGR2GRAY)
gray_rot = cv2.cvtColor(img_rot, cv2.COLOR_BGR2GRAY)
# 显示初始图片
# cmp_org = np.hstack((gray_org, gray_rot))# 水平拼接两个图片
# cv2.imshow("cmp_org",cmp_org)
"""
step2:提取特征点
"""
# 创建sift对象
sift = cv2.xfeatures2d_SIFT.create()
# 检测、计算特征点和描述子
kp_org,des_org =sift.detectAndCompute(gray_org,None)
kp_rot,des_rot =sift.detectAndCompute(gray_rot,None)
# 画出特征点
pic_org = cv2.drawKeypoints(gray_org, kp_org, None, (0, 0, 255))
pic_rot = cv2.drawKeypoints(gray_rot, kp_rot, None, (0, 0, 255))
# 显示特征点图片
# cmp_kp = np.hstack((pic_org, pic_rot))# 水平拼接两个图片
# cv2.imshow("cmp_org",cmp_kp)
"""
######step3;特征匹配两种方法:1)BFMacther 2)设置FLANN 超参数
"""
# # 创建BFMatcher对象
# bf = cv2.BFMatcher(cv2.NORM_L2)
# # 匹配特征点
# matches = bf.match(des_org,des_rot)
#
# # 画出匹配点
# img_match = cv2.drawMatches(gray_org, kp_org, gray_rot, kp_rot, matches[:100], None,flags=2)
# cv2.imshow("img_match", img_match)
"""
使用bf.match的两个图像检测的特征点错误比较多,简直不能直视
"""
# #######################################
# 设置FLANN 超参数
FLANN_INDEX_KDTREE = 0
# K-D树索引超参数
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
# 搜索超参数
search_params = dict(checks=50)
# 初始化FlannBasedMatcher匹配器
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 通过KNN的方式匹配两张图的描述子
matches = flann.knnMatch(des_org, des_rot, k=2)
print(matches)
# 筛选比较好的匹配点
good = []
for i, (m, n) in enumerate(matches):
if m.distance < 0.6 * n.distance:
good.append(m)
# 画出匹配点
img_nnmatch = cv2.drawMatches(img_org, kp_org, img_rot, kp_rot, good[100:130], None, flags=2)
cv2.imshow("SIFT-FLANN", img_nnmatch)
"""
使用FlannBasedMatcher匹配效果要好的太多
"""
cv2.waitKey()
cv2.destroyAllWindows()
10.3 SURF算法
(6)cv2.xfeatures2d.SURF_create([, hessianThreshold[, nOctaves[, nOctaveLayers[, extended[, upright]]]]]) -> retval
-
功能:创建SURF对象
-
参数:
* hessianThreshold:默认100,关键点检测的阈值,越高监测的点越少 * nOctaves:默认4,金字塔组数 * nOctaveLayers:默认3,每组金子塔的层数 * extended:默认False,扩展描述符标志,True表示使用扩展的128个元素描述符,False表示使用64个元素描述符。 * upright:默认False,垂直向上或旋转的特征标志,True表示不计算特征的方向,False-计算方向。之后也可以通过类似getHessianThreshold(),setHessianThreshold()等函数来获取或修改上述参数值,例如 -
返回值dst :SURF对象
-
示例:
################## sift改进版SURF算子 ##################
import cv2
import numpy as np
######step1;构建初始图片
img_org = cv2.imread(r"D:\111111Python\AI\img_project\chapter2_homework\left12.jpg")
# img_org = cv2.imread(r"D:\111111Python\AI\img_project\chapter2_homework\scences.jpg")
# 读取原图片的行、列、通道数
rows,cols,channels = img_org.shape
#沿着原图像顺指针旋转90度,并且缩减为原来的0.5
M = cv2.getRotationMatrix2D((cols/2, rows/2), 90, 0.5)
img_rot = cv2.warpAffine(img_org, M, (cols, rows))
######step2;提取图像特征点
hessian_threshold = 1000
# 创建检测算子
surf = cv2.xfeatures2d.SURF_create(hessian_threshold)
# 检测特征点、计算描述子
kp_org, des_org = surf.detectAndCompute(img_org, None)
kp_rot, des_rot = surf.detectAndCompute(img_rot, None)
######step3;特征匹配两种方法:1)BFMacther 2)设置FLANN 超参数
# BFMacther类对象创建
# bf = cv2.BFMatcher(cv2.NORM_L1)
# # 匹配描述子
# matches = bf.match(des_org, des_rot)
# #注意:此方法效果较差,出现较多的其他错误检测点,需要将hessian_threshold设置为很高才行。
# #######################################
# 设置FLANN 超参数
FLANN_INDEX_KDTREE = 0
# K-D树索引超参数
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
# 搜索超参数
search_params = dict(checks=50)
# 初始化FlannBasedMatcher匹配器
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 通过KNN的方式匹配两张图的描述子
matches = flann.knnMatch(des_org, des_rot, k=2)
# 筛选比较好的匹配点
good = []
for i, (m, n) in enumerate(matches):
if m.distance < 0.6 * n.distance:
good.append(m)
#####step4;画出相关匹配点
img_nnmatch = cv2.drawMatches(img_org, kp_org, img_rot, kp_rot, good[100:130], None, flags=2)
cv2.imshow("SURF", img_nnmatch)
cv2.waitKey()
cv2.destroyAllWindows()
10.3 FAST算法
(7)cv2.FastFeatureDetector_create([, threshold[, nonmaxSuppression[, type]]]) -> retval
-
功能:创建FAST对象
-
参数:
* threshold:阈值,默认10 * nonmaxSuppression:非极大值抑制,默认True * type:检测器类型: cv2.FAST_FEATURE_DETECTOR_TYPE_5_8 cv2.FAST_FEATURE_DETECTOR_TYPE_7_12 cv2.FAST_FEATURE_DETECTOR_TYPE_9_16,默认 -
返回值dst :FAST对象
-
示例:
################## FAST算子 ##################
import cv2
import numpy as np
######step1;构建初始图片
img_org = cv2.imread(r"D:\111111Python\scences.jpg")
# 读取原图片的行、列、通道数
rows,cols,channels = img_org.shape
#沿着原图像顺指针旋转90度,并且缩减为原来的0.5
M = cv2.getRotationMatrix2D((cols/2, rows/2), 90, 0.5)
img_rot = cv2.warpAffine(img_org, M, (cols, rows))
######step2;提取图像特征点
fast=cv2.FastFeatureDetector_create(threshold=40,nonmaxSuppression=True,type=cv2.FAST_FEATURE_DETECTOR_TYPE_9_16)
kp_org = fast.detect(img_org, None)
kp_rot = fast.detect(img_rot, None)
######step4;计算描述符
# 注意!!!!此处用的是 cv2.BRISK_create
br = cv2.BRISK_create()
kp_org, des_org = br.compute(img_org, kp_org)
kp_rot, des_rot = br.compute(img_rot, kp_rot)
######step3;特征匹配
# 创建BFMatcher对象
bf = cv2.BFMatcher(cv2.NORM_L2)
# 根据描述子匹配特征点
matches = bf.match(des_org, des_rot)
# 初始化Bruteforce匹配器
bf = cv2.BFMatcher()
# 通过KNN匹配两张图片的描述子
matches = bf.knnMatch(des_org, des_rot, k=2)
# 筛选比较好的匹配点
good = []
for i, (m, n) in enumerate(matches):
if m.distance < 0.9 * n.distance:
good.append(m)
#####step4;画出相关匹配点
# img3 = cv2.drawMatches(img_org, kp_org, img_rot, kp_rot, good, None, flags=2)
# cv2.imshow("FAST-BF", img3)
img3 = cv2.drawMatches(img_org, kp_org, img_rot, kp_rot, good, None, flags=2)
cv2.imshow("FAST-BF", img3)
10.4 ORB算法
(8)cv2.ORB_create([, nfeatures[, scaleFactor[, nlevels[, edgeThreshold[, firstLevel[, WTA_K[, scoreType[, patchSize[, fastThreshold]]]]]]]]]) -> retval
-
功能:创建ORB对象
-
参数:
* nfeatures:要保留的特征的最大数量,默认500 * scaleFactor:金字塔抽取比,大于1,默认1.2。scaleFactor==2表示经典金字塔,每一层的像素都比上一层少4倍,但如此大的尺度因子会显著降低特征匹配得分。另一方面,过于接近1的比例因素将意味着要覆盖一定的比例范围,你将需要更多的金字塔级别,因此速度将受到影响。 * nlevels:金字塔层数,默认8。最小级别的线性大小将等于input_image_linear_size/pow(scaleFactor, nlevels - firstLevel)。 * edgeThreshold:边框阈值,这是未检测到特征的边框尺寸,默认31。它应该大致匹配patchSize参数。 * firstLevel:将源图像放置到的金字塔级别,默认0。之前的图层都是放大的源图像。 * WTA_K:产生面向对象的BRIEF描述符的每个元素的点的数量。默认值2表示取一个随机点对并比较它们的亮度,得到0/1响应。其他可能的值是3和4。例如,意味着我们需要3随机点(当然,这些点坐标是随机的,但它们产生的预定义的种子,所以每个元素的简短描述符计算确定性像素矩形),找到的赢家的最大亮度和产出指数(0、1或2)。这样的输出会占据2位,因此它需要汉明距离的一种特殊变体,指示为NORM_HAMMING2(2位/ bin)。当WTA_K=4时,我们取4个随机点来计算每个bin(它也将占用2位,可能值为0、1、2或3)。 * scoreType:默认的HARRIS_SCORE表示使用Harris算法对特征进行排序(分数写为KeyPoint::score,用于保留最佳nfeatures特征);FAST_SCORE是参数的替代值,该参数生成的键值稍微不太稳定,但是计算起来要快一些。 * patchSize:面向对象的BRIEF描述符使用的矩阵的大小,默认31。当然,在较小的金字塔层上,特征所覆盖的感知图像区域会更大。 * fastThreshold:FAST特征检测器阈值,默认20 * 可以使用类似于orb.getScoreType(),orb.setScoreType(ScoreType)查看和更改参数,具体可查看官网: https://docs.opencv.org/master/db/d95/classcv_1_1ORB.html -
返回值dst :ORB对象
-
示例:
################## ORB算子 ##################
import cv2
import numpy as np
######step1;构建初始图片
img_org = cv2.imread(r"D:\111111Python\AI\scences.jpg")
# 读取原图片的行、列、通道数
rows,cols,channels = img_org.shape
#沿着原图像顺指针旋转90度,并且缩减为原来的0.5
M = cv2.getRotationMatrix2D((cols/2, rows/2), 90, 0.5)
img_rot = cv2.warpAffine(img_org, M, (cols, rows))
######step2;提取图像特征点
orb = cv2.ORB_create()
kp_org, des_org = orb.detectAndCompute(img_org,None)
kp_rot, des_rot = orb.detectAndCompute(img_rot,None)
######step3;特征匹配
bf = cv2.BFMatcher(cv2.NORM_L2)
# 通过KNN匹配两张图片的描述子
matches = bf.knnMatch(des_org,des_rot,k=2)
# 筛选较好的匹配点
good = []
for i, (m, n) in enumerate(matches):
if m.distance < 1.1 * n.distance:
good.append(m)
#####step4;画出相关匹配点
img2 = cv2.drawMatches(img_org, kp_org, img_rot, kp_rot, good, None, flags=2)
cv2.imshow("ORB-BF", img2)
cv2.waitKey()
cv2.destroyAllWindows()
10.5 特征匹配
Brute-Force匹配器(暴力匹配)
Brute-Force匹配器很简单,它取第一个集合里一个特征的描述子并用第二个集合里所有其他的特征和他通过一些距离计算进行匹配。最近的返回。
对于BF匹配器,首先我们得用cv2.BFMatcher()创建BF匹配器对象.它取两个可选参数,第一个是normType。它指定要使用的距离量度。默认是cv2.NORM_L2。对于SIFT,SURF很好。(还有cv2.NORM_L1)。对于二进制字符串的描述子,比如ORB,BRIEF,BRISK等,应该用cv2.NORM_HAMMING。使用Hamming距离度量,如果ORB使用VTA_K == 3或者4,应该用cv2.NORM_HAMMING2
第二个参数是布尔变量,crossCheck模式是false,如果它是true,匹配器返回那些和(i, j)匹配的,这样集合A里的第i个描述子和集合B里的第j个描述子最匹配。两个集合里的两个特征应该互相匹配,它提供了连续的结果,当它创建以后,两个重要的方法是BFMatcher.match()和BFMatcher.knnMatch()。第一个返回最匹配的,第二个方法返回k个最匹配的,k由用户指定。当我们需要多个的时候很有用。
想我们用cv2.drawKeypoints()来画关键点一样,cv2.drawMatches()帮我们画匹配的结果,它把两个图像水平堆叠并且从第一个图像画线到第二个图像来显示匹配。
还有一个cv2.drawMatchesKnn来画k个最匹配的。如果k=2,它会给每个关键点画两根匹配线。所以我们得传一个掩图,如果我们想选择性的画的话。
(9)cv2.BFMatcher([, normType[, crossCheck]])
-
功能:Brute-force matcher类对象创建
-
参数:
对于BF匹配器,首先我们得用cv2.BFMatcher()创建BF匹配器对象.它取两个可选参数,第一个是normType。它指定要使用的距离量度。默认是cv2.NORM_L2。对于SIFT,SURF很好。(还有cv2.NORM_L1)。对于二进制字符串的描述子,比如ORB,BRIEF,BRISK等,应该用cv2.NORM_HAMMING。使用Hamming距离度量,如果ORB使用VTA_K == 3或者4,应该用cv2.NORM_HAMMING2 第二个参数是布尔变量,crossCheck模式是false,如果它是true,匹配器返回那些和(i, j)匹配的,这样集合A里的第i个描述子和集合B里的第j个描述子最匹配。两个集合里的两个特征应该互相匹配,它提供了连续的结果, -
返回值dst :Brute-force matcher类对象
-
示例:参见sift算法
FLANN匹配器
FLANN是快速最近邻搜索包(Fast_Library_for_Approximate_Nearest_Neighbors) 的简称。它是一个对大数据集和高维特征进行最近邻搜索的算法的集合,而且 这些算法都已经被优化过了。在面对大数据集时它的效果要好于 BFMatcher。
使用 FLANN 匹配,我们需要传入两个字典作为参数。这两个用来确定要 使用的算法和其他相关参数等。第一个是 IndexParams。各种不同算法的信 息可以在 FLANN 文档中找到。这里我们总结一下,对于 SIFT 和 SURF 等, 我们可以传入的参数是:
indexparams = dict(algorithm = FLANNINDEXKDTREE,trees = 5)
第二个字典是 SearchParams。用它来指定递归遍历的次数。值越高 结果越准确,但是消耗的时间也越多。如果你想修改这个值,传入参数:
searchparams = dict(checks = 100)
(10)cv2.FlannBasedMatcher(index_params,search_params)
-
功能:FlannBasedMatcher类对象创建
-
参数:
使用 FLANN 匹配,我们需要传入两个字典作为参数。这两个用来确定要 使用的算法和其他相关参数等。第一个是 IndexParams。各种不同算法的信 息可以在 FLANN 文档中找到。这里我们总结一下,对于 SIFT 和 SURF 等, 我们可以传入的参数是: indexparams = dict(algorithm = FLANNINDEXKDTREE,trees = 5) 第二个字典是 SearchParams。用它来指定递归遍历的次数。值越高 结果越准确,但是消耗的时间也越多。如果你想修改这个值,传入参数: searchparams = dict(checks = 100) -
返回值dst :FlannBasedMatcher类对象
-
示例:参见sift算法
11. 视频分析
参考链接:
摄像头: https://blog.csdn.net/yukinoai/article/details/85873572
l-k光流: https://blog.csdn.net/yukinoai/article/details/89416795
11.1 摄像头视频
(1) 用摄像头捕获视频
- cv2.VideoCapture(设备索引号):创建一个VideoCapture 对象,他的参数可以是设备的索引号,或者是一个视频文件。设备索引号就是在指定要使用的摄像头。 一般的笔记本电脑都有内置摄像头。参数是 0。
- cap.read(): 返回一个布尔值(True/False)。如果帧读取的是正确的,就是 True。所以最后你可以通过检查他的返回值来查看视频文件是否已经到 了结尾。
- cap.isOpened(): 返回一个布尔值(True/False)。用于检查摄像头是否初始化成功,Ture表示成功,否则要使用cap.open()进行初始化
- cap.get(参数):用于获得视频的一些参数信息
- cap.set(参数,值):用于设置视频的一些参数,参数值如下:

- 示例代码:
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
ret = cap.set(3, 320) # 设置帧宽
ret = cap.set(4, 240) # 设置帧高
if cap.isOpened() is True:
while(True):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转换为灰色通道
cv2.imshow('frame', gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
else:
print('cap is not opened!')
(2) 保存视频
-
cv2.VideoWriter_fourcc(视频格式):设置保存视频的格式,有两种方式,以MJPG为例:(‘M’, ‘J’, ‘P’, ‘G’) ,或者(*‘MJPG’),windows可用DIVX,输出avi格式
-
cv2.VideoWriter(视频文件名,格式,帧率,帧大小,是否为彩色):设置一个输出流out = cv2.VideoWriter()
-
out.write(frame):向输出流内写入一帧
-
示例代码:
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
fourcc = cv2.VideoWriter_fourcc(*'XVID') # 设置视频编码格式
out = cv2.VideoWriter('output.avi', fourcc, 20.0, (640, 480)) # 名称, 格式, 帧率, 帧大小
if cap.isOpened() is True: # 如果摄像头已被初始化返回True
while(True):
ret, frame = cap.read() # 如果帧读取正确则返回True
if ret is True:
frame = cv2.flip(frame, 1) # 反转图像,0:垂直反转,1:水平翻转,2:水平垂直反转
out.write(frame)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
break
cap.release()
cap.release()
cv2.destroyAllWindows()
else:
print('cap is not opened!')
(2) 播放视频
-
播放视频只需将cv2.VideoCapture()参数改为视频即可,播放视频的本质就是图片的连续显示,在播放每一帧时,使用 cv2.waiKey() 设置适当的持续时间就可以控制视频的播放速度。
-
示例代码:
import numpy as np
import cv2
cap = cv2.VideoCapture('output.avi') # 选择要播放的视频
if cap.isOpened() is True:
while(True):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 输出灰色图像
cv2.imshow('frame', gray)
if cv2.waitKey(25) & 0xFF == ord('q'): # 改变cv2.waitKey()中的值可以改变播放速度
break
cap.release()
cv2.destroyAllWindows()
else:
print('cap is not opened!')
11.2光流
一般 L-K光流计算
L-K光流计算过程被OpenCV打包成了一个函数:cv2.calcOpticalFlowPyrLK()。现在我们使用这个函数创建一个小程序来跟踪视频中的一些点。
要跟踪那些点 呢?我们使用函数 cv2.goodFeatureToTrack() 来确定要跟踪的点。
我们首先在视频的第一帧图像中检测一些 Shi-Tomasi 角点,然后我们使用 Lucas-Kanade算法迭代跟踪这些角点。我们要给函数cv2.calcOpticlaFlowPyrLK()传入前一帧图像和其中的点,以及下一帧图像。函数将返回带有状态数的点, 如果状态数是 1,那说明在下一帧图像中找到了这个点(上一帧中角点),如果 状态数是 0,就说明没有在下一帧图像中找到这个点。我们再把这些点作为参 数传给函数,如此迭代下去实现跟踪。
(4)goodFeaturesToTrack(image, maxCorners, qualityLevel, minDistance[, corners[, mask[, blockSize[, useHarrisDetector[, k]]]]]) -> corners
-
功能:该函数可用于初始化对象的基于点的跟踪器。
-
参数:
image:输入8位或浮点32位单通道图像。 corners:输出检测到的角点的矢量。 maxCorners:要返回的最大角点数。如果角落多于找到的角落,则返回最强的角落。maxCorners <= 0意味着不设置最大值限制并返回所有检测到的角点。 qualityLevel:表征图像角落的最小可接受质量的参数。参数值乘以最佳拐角质量度量,即最小特征值(参见cornerMinEigenVal)或Harris函数响应(参见cornerHarris)。质量测量小于产品的角落被拒绝。例如,如果最佳角点的质量度量为1500,质量等级为0.01,则质量度量小于15的所有角落都将被拒绝。 minDistance:返回角落之间的最小可能欧几里德距离。 mask:可选的感兴趣区域。如果图像不为空(它需要具有类型CV_8UC1并且与图像大小相同),则它指定检测到角的区域。 blockSize:用于计算每个像素邻域上的导数共变矩阵的平均块的大小。请参阅cornerEigenValsAndVecs。 useHarrisDetector:参数指示是否使用Harris检测器(请参阅cornerHarris)或cornerMinEigenVal。 k:Harris探测器的自由参数。 -
返回值dst :
-
示例:
(5)calcOpticalFlowPyrLK(prevImg, nextImg, prevPts, nextPts[, status[, err[, winSize[, maxLevel[, criteria[, flags[, minEigThreshold]]]]]]]) -> nextPts, status, err
-
功能:L-K光流估计
使用具有金字塔的迭代Lucas-Kanade方法计算稀疏特征集的光流。 -
参数:
prevImg:由buildOpticalFlowPyramid构造的第一个8位输入图像或金字塔。 nextImg:与prevImg相同尺寸和相同类型的第二输入图像或金字塔 prevPts:需要找到流量的2D点的矢量; 点坐标必须是单精度浮点数。 nextPts:2D点的输出矢量(具有单精度浮点坐标),包含第二图像中输入特征的计算新位置; 当传递OPTFLOW_USE_INITIAL_FLOW标志时,向量必须与输入中的大小相同。 status:输出状态向量(无符号字符); 如果找到相应特征的流,则向量的每个元素设置为1,否则设置为0。 err:输出错误的矢量; 向量的每个元素都设置为相应特征的错误,错误度量的类型可以在flags参数中设置; 如果未找到流,则未定义错误(使用status参数查找此类情况)。 winSize:每个金字塔等级的搜索窗口的大小。 maxLevel:基于0的最大金字塔等级数; 如果设置为0,则不使用金字塔(单级),如果设置为1,则使用两个级别,依此类推; 如果将金字塔传递给输入,则算法将使用与金字塔具有但不超过maxLevel的级别。 criteria:指定迭代搜索算法的终止条件(在指定的最大迭代次数criteria.maxCount之后或当搜索窗口移动小于criteria.epsilon时)。 flags: OPTFLOW_USE_INITIAL_FLOW使用初始估计,存储在nextPts中; 如果未设置标志,则将prevPts复制到nextPts并将其视为初始估计。 OPTFLOW_LK_GET_MIN_EIGENVALS使用最小特征值作为误差测量(参见minEigThreshold描述); 如果没有设置标志,则将原稿周围的色块和移动点之间的L1距离除以窗口中的像素数,用作误差测量。 minEigThreshold:该算法计算光流方程的2×2正常矩阵的最小特征值(该矩阵在[23]中称为空间梯度矩阵),除以窗口中的像素数; 如果此值小于minEigThreshold,则过滤掉相应的功能并且不处理其流程,因此它允许删除坏点并获得性能提升。 -
返回值dst :
-
示例:
import numpy as np
import cv2 as cv
cap = cv.VideoCapture('video.mp4')
# ShiTomasi角落检测的参数
feature_params = dict(maxCorners=100,
qualityLevel=0.3,
minDistance=7,
blockSize=7)
# lucas kanade光流的参数
lk_params = dict(winSize=(15, 15),
maxLevel=2,
criteria=(cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 0.03))
# 创建一些随机颜色
color = np.random.randint(0, 255, (100, 3))
# 拍摄第一帧并在其中找到角落
ret, old_frame = cap.read()
old_gray = cv.cvtColor(old_frame, cv.COLOR_BGR2GRAY)
p0 = cv.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
# 创建一个用于绘图目的的蒙版图像
mask = np.zeros_like(old_frame)
while(1):
ret, frame = cap.read()
frame_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# #计算光流
p1, st, err = cv.calcOpticalFlowPyrLK(
old_gray, frame_gray, p0, None, **lk_params)
# 选择较好的点
good_new = p1[st == 1]
good_old = p0[st == 1]
# 画出曲线
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
mask = cv.line(mask, (a, b), (c, d), color[i].tolist(), 2)
frame = cv.circle(frame, (a, b), 5, color[i].tolist(), -1)
img = cv.add(frame, mask)
cv.imshow('frame', img)
k = cv.waitKey(30) & 0xff
if k == 27:
break
# 现在更新上一帧和前一点
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
cv.destroyAllWindows()
cap.release()
稠密光流计算
Lucas-Kanade 法是计算一些特征点的光流(我们上面的例子使用的是Shi-Tomasi 算法检测到的角点)。OpenCV 还提供了一种计算稠密光流的 方法。它会图像中的所有点的光流。这是基于 Gunner_Farneback 的算法(2003 年)。 下面的例子就是使用上面的算法计算稠密光流。结果是一个带有光流向量(u,v)的双通道数组。通过计算我们能得到光流的大小和方向。我们使用颜 色对结果进行编码以便于更好的观察。方向对应于 H(Hue)通道,大小对应 于 V(Value)通道。
(6)cv.calcOpticalFlowFarneback(prev, next, flow, pyr_scale, levels, winsize, iterations, poly_n, poly_sigma, flags) -> flow
-
功能:计算稠密光流
使用Gunnar Farneback的算法计算密集的光流。 -
参数:
prev:第一个8位单通道输入图像。 next:与prev相同尺寸和相同类型的第二输入图像 flow:计算出的流图像与prev相同,并且类型为CV_32FC2。 pyr_scale:指定图像比例为每个图像构建金字塔; pyr_scale = 0.5表示经典金字塔,其中每个下一层比前一层小两倍。 levels:包括初始图像的金字塔层数; levels = 1表示不创建额外的图层,仅使用原始图像。 winsize:平均窗口大小; 较大的值会增加算法对图像噪声的鲁棒性,并为快速运动检测提供更多机会,但会产生更模糊的运动场。 iterations:算法在每个金字塔等级执行的迭代次数。 poly_n:用于在每个像素中找到多项式展开的像素邻域的大小; 较大的值意味着图像将用更光滑的表面近似,从而产生更稳健的算法和更模糊的运动场,通常poly_n = 5或7。 poly_sigma:高斯的标准偏差,用于平滑导数,用作多项式展开的基础; 对于poly_n = 5,你可以设置poly_sigma = 1.1,对于poly_n = 7,一个好的值是poly_sigma = 1.5。 flags:可以是以下的组合: OPTFLOW_USE_INITIAL_FLOW 使用输入流作为初始流近似值。 OPTFLOW_FARNEBACK_GAUSSIAN 使用winsize×winsize的高斯过滤器而不是相同尺寸的盒式过滤器,用于光流估计; 通常,这个选项比使用箱式过滤器更准确地流动,代价是降低速度; 通常,高斯窗口的winsize应设置为更大的值,以实现相同级别的稳健性。 -
返回值dst :flow见参数说明
-
示例:
》 (7)magnitude, angle = cv.cartToPolar(x, y, magnitude, angle, angleInDegrees)
-
功能:计算2D矢量的大小和角度。
-
参数:
x:x坐标数组; 这必须是单精度或双精度浮点数组。 y:y坐标数组,必须与x具有相同的大小和相同的类型。 magnitude:输出与x相同大小和类型的数量的数组。 angle:输出与x具有相同大小和类型的角度数组; 角度以弧度(从0到2π)或以度(0到360度)测量 angleInDegrees:指示角度是以弧度(默认为False)或以度为单位测量(True)。 -
返回值dst :参见参数说明
-
示例:
import cv2
import numpy as np
cap = cv2.VideoCapture("video.mp4")
ret, frame1 = cap.read()
prvs = cv2.cvtColor(frame1, cv2.COLOR_BGR2GRAY)
hsv = np.zeros_like(frame1)
hsv[..., 1] = 255
while(1):
ret, frame2 = cap.read()
next = cv2.cvtColor(frame2, cv2.COLOR_BGR2GRAY)
flow = cv2.calcOpticalFlowFarneback(
prvs, next, None, 0.5, 3, 15, 3, 5, 1.2, 0)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
hsv[..., 0] = ang*180/np.pi/2
hsv[..., 2] = cv2.normalize(mag, None, 0, 255, cv2.NORM_MINMAX)
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
cv2.imshow('frame2', bgr)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
elif k == ord('s'):
cv2.imwrite('opticalfb.png', frame2)
cv2.imwrite('opticalhsv.png', bgr)
prvs = next
cap.release()
cv2.destroyAllWindows()
12.摄像机标定和3D重构
参考链接
位姿估计: https://blog.csdn.net/yukinoai/article/details/89810400
12.1 相机标定
(1)retval, corners = cv2.findChessboardCorners(image, patternSize, corners, flags)
-
功能:找出棋盘角点
-
参数:
* image:源棋盘图像。它必须是8位灰度或彩色图像 * patternSize:每个棋盘行和列的内角数 * corners:输出检测到的角点阵列 * flags:类型 CALIB_CB_ADAPTIVE_THRESH使用自适应阈值将图像转换为黑白,而不是固定的阈值水平(根据图像的平均亮度计算)。 CALIB_CB_NORMALIZE_IMAGE 在应用固定阈值或自适应阈值之前,先用等化器对图像伽马进行归一化。 CALIB_CB_FILTER_QUADS使用额外的标准(如轮廓面积、周长、方形形状)来过滤轮廓检索阶段提取的假四分位。 CALIB_CB_FAST_CHECK对寻找棋盘角的图像运行快速检查,如果没有找到,则快捷调用。在退化条件下,当没有观察到棋盘时,这可以极大地加快调用。 -
返回值dst :retval->标定是否成功(True/False), corners->角点信息
-
示例:参见cv2.calibrateCamera
(2)image = cv2.drawChessboardCorners(image, patternSize, corners, patternWasFound)
-
功能:画出棋盘角点
-
参数:
* image:目标图像。它必须是8位灰度或彩色图像 * patternSize:每个棋盘行和列的内角数 * corners:输出检测到的角点阵列 * patternWasFound:参数指示是否找到完整的板。 findChessboardCorners的返回值应该在这里传递。 -
返回值dst :
-
示例:参见cv2.calibrateCamera
(3)retval, cameraMatrix, distCoeffs, rvecs, tvecs = cv2.calibrateCamera(objectPoints, imagePoints, imageSize, cameraMatrix, distCoeffs, rvecs, tvecs, flags, criteria)
-
功能:相机标定函数
-
参数:
objectPoints:在新界面中,它是校准模式坐标空间中校准模式点的向量的向量(如std::vector>)。外部向量包含的元素与模式视图的数量相同。如果在每个视图中显示相同的校准模式,并且它是完全可见的,那么所有的向量都是相同的。不过,可以使用部分遮挡的模式,甚至在不同视图中使用不同的模式。那么,向量就不一样了。这些点是三维的,但是由于它们是在一个模式坐标系中,那么,如果钻机是平面的,那么将模型放在XY坐标平面上可能是有意义的,这样每个输入对象点的z坐标就是0。在旧的接口中,来自不同视图的对象点的所有向量被连接在一起。 imagePoints:新界面中它是一个矢量的矢量投影的校准模式点(如 std::vector -
返回值dst :
是否成功,摄像机矩阵,畸变系数,旋转和变换向量 -
示例:
import numpy as np
import cv2
import glob
# termination criteria
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# prepare object points, like (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)
objp = np.zeros((6*6, 3), np.float32)
objp[:, :2] = np.mgrid[0:6, 0:6].T.reshape(-1, 2)
# Arrays to store object points and image points from all the images.
objpoints = [] # 3d point in real world space
imgpoints = [] # 2d points in image plane.
images = glob.glob('E:\\Program\\Python\\OpenCV-test\\Chessboard\\*.png')
i = 0
for fname in images:
img = cv2.imread(fname)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Find the chess board corners
ret, corners = cv2.findChessboardCorners(gray, (6, 6), None)
# If found, add object points, image points (after refining them)
if ret:
i += 1
objpoints.append(objp)
corners2 = cv2.cornerSubPix(gray, corners, (11, 11), (-1, -1), criteria)
imgpoints.append(corners)
# Draw and display the corners
cv2.drawChessboardCorners(img, (6, 6), corners2, ret)
cv2.imshow('img', img)
cv2.imwrite('E:\\Program\\Python\\OpenCV-test\\\chessresult\\00'+str(i)+'.jpg', img)
cv2.waitKey(50)
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)
np.savez('B.npz', mtx=mtx, dist=dist, rvecs=rvecs, tvecs=tvecs)
cv2.destroyAllWindows()
12.2 位置和姿态估计
(4)cv2.solvePnP(objectPoints, imagePoints, cameraMatrix, distCoeffs[, rvec[, tvec[, useExtrinsicGuess[, flags]]]]) -> retval, rvec, tvec
-
功能:在通过相机标定获取相机的畸变矩阵、相机内参等固有参数后,可以通过平面图片获取物体相对位姿状态 的函数
-
参数:
objectPoints:对象坐标空间中对象点的数组,Nx3为1通道或1xN/Nx1为3通道,其中N为点的个数。 imagePoints:对应的图像点数组,Nx2 1通道或1xN/Nx1 2通道,其中N为点的个数。 cameraMatrix:输入相机矩阵 distCoeffs:输入失真系数向量 rvec:输出旋转矢量,它与tvec一起将模型坐标系中的点带到摄像机坐标系中。 tvec:输出平移失量 useExtrinsicGuess:默认false。用于SOLVEPNP_ITERATIVE的参数.如果为真(1),则函数使用所提供的rvec和tvec值分别作为旋转矢量和平移矢量的初始近似,并进一步优化。 flags(使用的算法,默认第一个): SOLVEPNP_ITERATIVE: (默认)迭代法基于Levenberg-Marquardt优化。在本例中,函数找到这样一个最小化重投影误差的位姿,即观察到的投影图像点与投影(使用投影点)对象点之间距离的平方之和。 SOLVEPNP_P3P: Method is based on the paper of X.S. Gao, X.-R. Hou, J. Tang, H.-F. Chang "Complete Solution Classification for the Perspective-Three-Point Problem" ([70]). In this case the function requires exactly four object and image points. SOLVEPNP_AP3P: Method is based on the paper of T. Ke, S. Roumeliotis "An Efficient Algebraic Solution to the Perspective-Three-Point Problem" ([107]). In this case the function requires exactly four object and image points. SOLVEPNP_EPNP: Method has been introduced by F.Moreno-Noguer, V.Lepetit and P.Fua in the paper "EPnP: Efficient Perspective-n-Point Camera Pose Estimation" ([118]). SOLVEPNP_DLS: Method is based on the paper of Joel A. Hesch and Stergios I. Roumeliotis. "A Direct Least-Squares (DLS) Method for PnP" ([91]). SOLVEPNP_UPNP: Method is based on the paper of A.Penate-Sanchez, J.Andrade-Cetto, F.Moreno-Noguer. "Exhaustive Linearization for Robust Camera Pose and Focal Length Estimation" ([165]). In this case the function also estimates the parameters fx and fy assuming that both have the same value. Then the cameraMatrix is updated with the estimated focal length. SOLVEPNP_AP3P: Method is based on the paper of Tong Ke and Stergios I. Roumeliotis. "An Efficient Algebraic Solution to the Perspective-Three-Point Problem" ([107]). In this case the function requires exactly four object and image points. 但我们有了变换矩阵之后,我们就可以利用cv2.projectPoints()将这些坐标轴点映射到图像平面中去。 -
返回值dst :retval:是否成功, rvec:旋转矩阵, tvec:平移矩阵
-
示例:
(4)cv2.projectPoints(objectPoints, rvec, tvec, cameraMatrix, distCoeffs[, imagePoints[, jacobian[, aspectRatio]]]) -> imagePoints, jacobian
-
功能:将3D功能投影到2D平面上
-
参数:
objectPoints:对象坐标空间中对象点的数组,Nx3为1通道或1xN/Nx1为3通道,其中N为点的个数。 rvec:旋转矢量 tvec:位移矢量 cameraMatrix:输入相机矩阵 distCoeffs:输入失真系数向量 imagePoints:图像点的输出数组,2xN/Nx2 1通道或1xN/Nx1 2通道 jacobian:可选输出2Nx(10+)图像点对旋转矢量分量、平移矢量分量、焦距分量、主点坐标分量和畸变系数的导数雅可比矩阵。在旧的接口中,雅可比矩阵的不同分量通过不同的输出参数返回。 aspectRatio:可选“固定长宽比”参数。如果参数不为0,则函数假设长径比(fx/fy)是固定的,并相应地调整雅可比矩阵。 -
返回值dst :
-
示例:
# 将3D 空间中的点(3,0,0),(0,3,0),(0,0,3) 相对应的和原点组成的3条直线投影到2D图像中显示
import numpy as np
import cv2 as cv
import glob
# 导入数据
with np.load('B.npz') as X:
mtx, dist, _, _ = [X[i] for i in ('mtx', 'dist', 'rvecs', 'tvecs')]
# 画坐标轴
def draw(img, corners, imgpts):
corner = tuple(corners[0].ravel())
img = cv.line(img, corner, tuple(imgpts[0].ravel()), (255, 0, 0), 5)
img = cv.line(img, corner, tuple(imgpts[1].ravel()), (0, 255, 0), 5)
img = cv.line(img, corner, tuple(imgpts[2].ravel()), (0, 0, 255), 5)
return img
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 30, 0.001)
objp = np.zeros((6*6, 3), np.float32)
objp[:, :2] = np.mgrid[0:6, 0:6].T.reshape(-1, 2)
axis = np.float32([[3, 0, 0], [0, 3, 0], [0, 0, -3]]).reshape(-1, 3)
images = glob.glob('E:\\Program\\Python\\OpenCV-test\\Chessboard\\*.png')
for fname in images:
img = cv.imread(fname)
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
ret, corners = cv.findChessboardCorners(gray, (6, 6), None)
if ret:
corners2 = cv.cornerSubPix(gray, corners, (11, 11), (-1, -1), criteria)
# 寻找旋转和平移矢量
ret, rvecs, tvecs = cv.solvePnP(objp, corners2, mtx, dist)
# 将3D点投影到平面
imgpts, jac = cv.projectPoints(axis, rvecs, tvecs, mtx, dist)
img = draw(img, corners2, imgpts)
cv.imshow('img', img)
k = cv.waitKey(0) & 0xFF
if k == ord('s'):
cv.imwrite(fname+'AXIS'+'.png', img)
cv.destroyAllWindows()
13.机器学习
参考
knn: 参见help(cv2.ml.KNearest_create)
k-means: https://www.cnblogs.com/gezhuangzhuang/p/10775716.html
svm: 参见help(cv2.ml.SVM_create)
前言
cv2.ml.svm---------------------支持向量机
cv2.ml.knn---------------------K.近邻
cv2.ml.bayesian----------------正态贝叶斯分类器
cv2.ml.em----------------------期望最大化
cv2.ml.boost.tree--------------boost分类器
cv2.ml.tree--------------------决策树分类器
cv2.ml.ann.mlp-----------------感知器神经网络分类器
cv2.ml.cnn---------------------卷积神经网络
cv2.ml.random.trees-----------------随机树分类器
cv2.ml.extremely.randomized.trees---随机森林分类器
cv2.ml.gradient.boosting.trees------梯度boost分类器
等等
当然大部分人学习机器学习,使用scikitlearn比较多,有兴趣可以对比一下。
其实opencv中也有很多机器学习相关的库函数,可能使用的人比较少,可以去官网查看一下,就不详细展开说明了。
13.1 K近邻(k-Nearest Neighbour, knn)
kNN 可以说是最简单的监督学习分类器了。想法也很简单,就是找出测试数据在特征空间中的最近邻居。
kNN 算法分类器的首先要进行初始化,我们要传入一个训练数据集,以及与训练数据对应的分类来训练 kNN 分类器(构建搜索树)。最后要使用 OpenCV 中的 kNN 分类器,我们给它一个测试数据,让它来进行分类。在使用 kNN 之前,我们应该对测试数据有所了解。我们的数据应该是大小为数据数目乘以特征数目的浮点性数组。然后我们就可以通过计算找到测试数据最近的邻居了。
我们可以设置返回的最近邻居的数目。返回值包括:
1. 由 kNN 算法计算得到的测试数据的类别标志(0 或 1)。如果你想使用
最近邻算法,只需要将 k 设置为 1,k 就是最近邻的数目。
2. k 个最近邻居的类别标志。
3. 每个最近邻居到测试数据的距离。
ml_KNearest(ml_StatModel)是opencv中KNN分类器的类对象,常用方法函数:
create() -> retval
train(trainData[, flags]) -> retval
train(samples, layout, responses) -> retval
findNearest(samples, k[, results[, neighborResponses[, dist]]]) -> retval, results, neighborResponses, dist
predict(samples[, results[, flags]]) -> retval, results 等等
(1)knn = cv2.ml.KNearest_create()
- 功能:创建knn对象
(2)knn.train(samples, layout, responses) -> retval
- 功能:knn通过样本数据训练模型
- 参数:
samples:训练样本sample
layout: sample type, 参见ml::SampleTypes
responses: 与样本相关的反应向量 - 返回值dst :训练好的模型
(3)knn.findNearest(samples, k[, results[, neighborResponses[, dist]]]) -> retval, results, neighborResponses, dist
-
功能:将新样本的分类
-
参数:
samples:按照行存储的样本数据,它是一个单精度浮点矩阵, 样本尺寸是* k。 k:使用的最临近数目值(nearest neighbors),应该设置 > 1 results:对于预测(分类或者回归)的结果向量,应该是具有 尺寸的单精度矩阵 neighborResponses:对于neighbors的相应输出值,应该是 * k尺寸的单精度矩阵 dist:对于新样本到最近neighbors的距离,应该是 * k尺寸的单精度矩阵 -
返回值dst :
retval:成功与否 results:newcomer(新样本)的标签,如果最近邻算法,k=1 neighborResponses:k-Nearest Neighbors的标签 dist:从newcomer到每个最近邻居的相应距离 -
示例:
# encoding:utf-8
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Feature:设置为25行2列的包含(x,y)的已知的训练数据
trainData = np.random.randint(0, 100, (25, 2)).astype(np.float32)
# print(trainData)
# labels:设置为0:代表Red, 1:代表Blue
labels = np.random.randint(0, 2, (25, 1)).astype(np.float32)
# print(labels)
# 找出红色并绘制
# print(labels.ravel())
red = trainData[labels.ravel() == 0] # ravel()降维
plt.scatter(red[:, 0], red[:, 1], 80, 'r', '^') # 绘制三角散点图
# 找出蓝色并绘制
blue = trainData[labels.ravel() == 1]
plt.scatter(blue[:, 0], blue[:, 1], 80, 'b', 's')
# 测试数据被标记为绿色
'''
返回值包括:
1、由KNN算法计算得到的测试数据的类别标志0或1,如果想要使用最近邻算法,只需将k置为1。
2、k个最近邻居的类别标志。
3、每个最近邻居到测试数据的距离
'''
newcomer = np.random.randint(0, 100, (1, 2)).astype(np.float32)
plt.scatter(newcomer[:, 0], newcomer[:, 1], 80, 'g', 'o')
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, labels)
ret, results, neighbours, dist = knn.findNearest(newcomer, 3)
print("result: ", results, "\n")
print("neighbours: ", neighbours, "\n")
print("distance: ", dist)
plt.show()
# 我们可以直接传入一个数组。对应的结同样也是数组
# 10 new comers
newcomers = np.random.randint(0, 100, (10, 2)).astype(np.float32)
ret, results, neighbours, dist = knn.findNearest(newcomer, 3)
13.2 SVM支持向量机
SVM支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)
ml_SVM(ml_StatModel)是opencv中svm的类,常用的方法函数如下:
cv2.ml.SVM_create()
setKernel(cv2.ml.SVM_LINEAR)
setType(cv2.ml.SVM_C_SVC)
setC(2.67)
setGamma(5.383)
说明:
C: 目标函数的惩罚系数C,用来平衡分类间隔margin和错分样本的,default C = 1.0;
Kernel:参数选择有RBF, Linear, Poly, Sigmoid, 默认的是”RBF”;
Gamma:核函数的系数(‘Poly’, ‘RBF’ and ‘Sigmoid’), 默认是gamma = 1 / n_features;
Type: 这里用的SVC就是分类
(4)svm = cv2.ml.SVM_create()
- 功能:创建svm对象
*示例:使用支持向量机进行手写数字分类
# encoding:utf-8
import cv2
import numpy as np
SZ = 20
bin_n = 16
affine_flags = cv2.WARP_INVERSE_MAP | cv2.INTER_LINEAR
# 使用方向梯度直方图HOG作为特征向量
def deskew(img):
m = cv2.moments(img) # 计算图像中的中心矩(最高到三阶)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11'] / m['mu02']
M = np.float32([[1, skew, -0.5 * SZ * skew], [0, 1, 0]])
# 图像的平移,参数:输入图像、变换矩阵、变换后的大小
img = cv2.warpAffine(img, M, (SZ, SZ), flags=affine_flags)
return img
# 计算图像的 X 方向和 Y 方向的 Sobel 导数
def hog(img):
gx = cv2.Sobel(img, cv2.CV_32F, 1, 0)
gy = cv2.Sobel(img, cv2.CV_32F, 0, 1)
mag, ang = cv2.cartToPolar(gx, gy) # 笛卡尔坐标转换为极坐标, → magnitude, angle
bins = np.int32(bin_n * ang / (2 * np.pi))
bin_cells = bins[:10, :10], bins[10:, :10], bins[:10, 10:], bins[10:, 10:]
mag_cells = mag[:10, :10], mag[10:, :10], mag[:10, 10:], mag[10:, 10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]
hist = np.hstack(hists)
return hist
# 将大图分割为小图,使用每个数字的前250个作为训练数据,后250个作为测试数据
img = cv2.imread('../data/digits.png', 0)
cells = [np.hsplit(row, 100) for row in np.vsplit(img, 50)]
# 第一部分是训练数据,剩下的是测试数据
train_cells = [i[:50] for i in cells]
test_cells = [i[50:] for i in cells]
deskewed = [list(map(deskew, row)) for row in train_cells]
hogdata = [list(map(hog, row)) for row in deskewed]
# print(hogdata)
trainData = np.float32(hogdata).reshape(-1, 64)
labels = np.repeat(np.arange(10), 250)[:, np.newaxis]
svm = cv2.ml.SVM_create()
svm.setKernel(cv2.ml.SVM_LINEAR)
svm.setType(cv2.ml.SVM_C_SVC)
svm.setC(2.67)
svm.setGamma(5.383)
svm.train(trainData, cv2.ml.ROW_SAMPLE, labels)
svm.save('svm_data.dat')
deskewed = [list(map(deskew, row)) for row in test_cells]
hogdata = [list(map(hog, row)) for row in deskewed]
testData = np.float32(hogdata).reshape(-1, bin_n * 4)
ret, result = svm.predict(testData)
mask = result == labels
correct = np.count_nonzero(mask)
print(correct * 100.0 / len(result), '%')
13.3 K值聚类
(5)kmeans(data, K, bestLabels, criteria, attempts, flags[, centers]) -> retval, bestLabels, centers
-
功能:
*##### > 参数:data:应该是np.float32类型的数据,每个特征应该放在一列。 K:聚类的最终数目 criteria:终止迭代的条件。当条件满足,算法的迭代终止。它应该是一个含有3个成员的元组,它们是(type,max_iter, epsilon): type终止的类型:有如下三种选择: - cv2.TERM_CRITERIA_EPS 只有精确度epslion满足时停止迭代 - cv2.TERM_CRITERIA_MAX_ITER 当迭代次数超过阈值时停止迭代 – cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER 上面的任何一个条件满足时停止迭代 max_iter:最大迭代次数 epsilon:精确度阈值 attempts:使用不同的起始标记来执行算法的次数。算法会返回紧密度最好的标记。紧密度也会作为输出被返回 flags:用来设置如何选择起始中心。通常我们有两个选择:cv2.KMEANS_PP_CENTERS和 cv2.KMEANS_RANDOM_CENTERS。 -
返回值dst :
compactness:紧密度返回每个点到相应中心的距离的平方和 labels:标志数组,每个成员被标记为0,1等 centers:有聚类的中心组成的数组 -
示例:
# coding: utf-8
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取原始图像灰度颜色
img = cv2.imread('scenery.png', 0)
print img.shape
#获取图像高度、宽度
rows, cols = img.shape[:]
#图像二维像素转换为一维
data = img.reshape((rows * cols, 1))
data = np.float32(data)
#定义中心 (type,max_iter,epsilon)
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
#设置标签
flags = cv2.KMEANS_RANDOM_CENTERS
#K-Means聚类 聚集成4类
compactness, labels, centers = cv2.kmeans(data, 4, None, criteria, 10, flags)
#生成最终图像
dst = labels.reshape((img.shape[0], img.shape[1]))
#用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
#显示图像
titles = [u'原始图像', u'聚类图像']
images = [img, dst]
for i in xrange(2):
plt.subplot(1,2,i+1), plt.imshow(images[i], 'gray'),
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
14 深度学习 (待补充)
15 多目标跟踪(待补充)
后续持续补充,敬请期待…