Python爬虫之爬取瓜子二手车信息- requests方法
最近在做二手车市场数据分析,试着爬取瓜子二手车在售车辆信息,做一下记录
大致思路如下:
1、从https://www.guazi.com/www/buy页面获取下面每个页码跳转的链接a
2、从a链接页面获取每辆车详情页的链接b
3、进入b抓取我需要的车辆信息:
car_model = Field() # 车型信息
registertime = Field() # 上牌日期
mileage = Field() # 行驶里程
sec_price = Field() # 二手车报价
new_price = Field() # 新车指导价(含税) daiqueding
registeraddress = Field() # 所在地
displacement = Field() # 排放标准1、页码链接构造比较简单,如图:
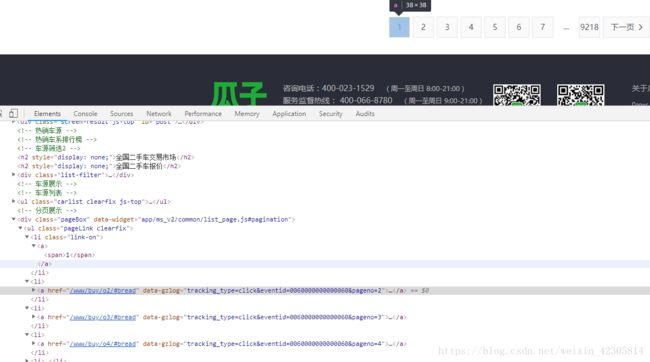
直接https://www.guazi.com/www/buy/o2/#bread中更改页码值就行
2、详情页链接构造如图
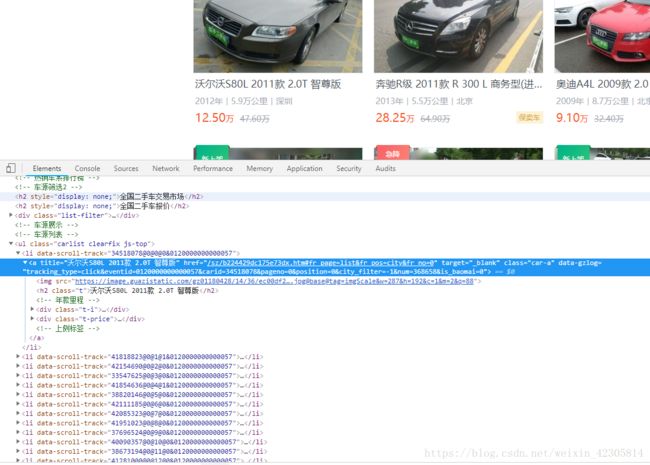
3、详情信息结构也比较好找

附上源码如下:
# -*- coding: utf-8 -*-
# 仅供交流学习
import requests
from pyquery import PyQuery as pq
import time,random
#请求头 cookie 必须需要加上,爬前request网址试下可以get到全内容不,不能的话换下cookie
headers = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate,br',
'Accept-Language':'zh-CN,zh;q=0.9',
'Cache-Control':'no-cache',
'Connection':'keep-alive','Cookie':'uuid=02724092-c319-4ba3-89e5-7bf432065f79; ganji_uuid=1367370650065045912399; Hm_lvt_936a6d5df3f3d309bda39e92da3dd52f=1528970077,1528970098; cityDomain=sz; lg=1; clueSourceCode=%2A%2300; sessionid=7273bfb7-b191-4334-f256-30ec9febf860; cainfo=%7B%22ca_s%22%3A%22sem_baiduss%22%2C%22ca_n%22%3A%22bdpc_sye%22%2C%22ca_i%22%3A%22-%22%2C%22ca_medium%22%3A%22-%22%2C%22ca_term%22%3A%22%25E4%25BA%258C%25E6%2589%258B%25E8%25BD%25A6%22%2C%22ca_content%22%3A%22-%22%2C%22ca_campaign%22%3A%22-%22%2C%22ca_kw%22%3A%22-%22%2C%22keyword%22%3A%22-%22%2C%22ca_keywordid%22%3A%2249888355177%22%2C%22scode%22%3A%2210103188612%22%2C%22ca_transid%22%3Anull%2C%22platform%22%3A%221%22%2C%22version%22%3A1%2C%22client_ab%22%3A%22-%22%2C%22guid%22%3A%2202724092-c319-4ba3-89e5-7bf432065f79%22%2C%22sessionid%22%3A%227273bfb7-b191-4334-f256-30ec9febf860%22%7D; antipas=2496334kL545T396w008C21ez41; preTime=%7B%22last%22%3A1531722065%2C%22this%22%3A1528850701%2C%22pre%22%3A1528850701%7D',
'Host':'www.guazi.com',
'Pragma':'no-cache',
'Referer':'https://www.guazi.com/sz/buy/o1r3_16_6/',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
# headers ={
# 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
# # cookie 必须需要加上,爬前request网址试下可以get到全内容不,不能的话换下cookie
# 'Cookie':'uuid=2276c0ec-9654-440b-b583-788b4a4b7788; ganji_uuid=1526893422532532003974; lg=1; Hm_lvt_936a6d5df3f3d309bda39e92da3dd52f=1531222100; clueSourceCode=10103000312%2300; antipas=2496334IBPB545K39a6U008T21x41; sessionid=94cd5b73-23cf-4515-d5a1-b7b03461d083; cainfo=%7B%22ca_s%22%3A%22pz_baidu%22%2C%22ca_n%22%3A%22tbmkbturl%22%2C%22ca_i%22%3A%22-%22%2C%22ca_medium%22%3A%22-%22%2C%22ca_term%22%3A%22-%22%2C%22ca_content%22%3A%22-%22%2C%22ca_campaign%22%3A%22-%22%2C%22ca_kw%22%3A%22-%22%2C%22keyword%22%3A%22-%22%2C%22ca_keywordid%22%3A%22-%22%2C%22scode%22%3A%2210103000312%22%2C%22ca_transid%22%3Anull%2C%22platform%22%3A%221%22%2C%22version%22%3A1%2C%22client_ab%22%3A%22-%22%2C%22guid%22%3A%222276c0ec-9654-440b-b583-788b4a4b7788%22%2C%22sessionid%22%3A%2294cd5b73-23cf-4515-d5a1-b7b03461d083%22%7D; close_finance_popup=2018-07-16; cityDomain=sz; preTime=%7B%22last%22%3A1531725774%2C%22this%22%3A1531222098%2C%22pre%22%3A1531222098%7D'
# }
# 代理ip
proxies = {
'http':'http://60.177.231.103:18118',
'https':'http://60.177.231.103:18118'
}
# proxies = {
# 'http':'http://60.177.226.225:18118',
# 'https':'http://60.177.226.225:18118'
# }
# proxies = {
# 'http':'http://14.118.252.228:6666',
# 'https':'http://14.118.252.228:6666'
# }
class GuaziSpider():
# 初始化爬虫
def __init__(self):
# 目标url
self.baseurl = 'https://www.guazi.com'
'''
在进行接口测试的时候,我们会调用多个接口发出多个请求,在这些请求中有时候需要保持一些共用的数据,例如cookies信息。
requests库的session对象能够帮我们跨请求保持某些参数,也会在同一个session实例发出的所有请求之间保持cookies。
'''
self.s = requests.Session()
self.s.headers = headers
# 本地ip被封的话启用该处ip代理池
# self.s.proxies = proxies
# 其中www代表瓜子二手车全国车源,如果只想爬某个城市的,如深圳的用sz替换www
self.start_url = 'https://www.guazi.com/www/buy/'
self.infonumber = 0 # 用来记录爬取了多少条信息用
# get_page用来获取url页面
def get_page(self, url):
return pq(self.s.get(url).text)
# page_url用来生成第n到第m页的翻页链接
def page_url(self,n,m):
page_start = n
page_end = m
# 新建空列表用来存翻页链接
page_url_list = []
for i in range(page_start,page_end+1,1):
base_url = 'https://www.guazi.com/www/buy/o{}/#bread'.format(i)
page_url_list.append(base_url)
return page_url_list
# detail_url用来抓取详情页链接
def detail_url(self, start_url):
# 获取star_url页面
content = self.get_page(start_url)
# 解析页面,获取详情页链接content=pq(self.s.get(start_url).text)
for chref in content('ul[@class="carlist clearfix js-top"] > li > a').items():
url = chref.attr.href
detail_url = self.baseurl + url
yield detail_url
# carinfo用来抓取每辆车的所需信息
def carinfo(self, detail_url):
content = self.get_page(detail_url)
d = {}
d['model'] = content('h2.titlebox').text().strip() # 车型
d['registertime'] = content('ul[@class="assort clearfix"] li[@class="one"] span').text() # 上牌时间
d['mileage'] = content('ul[@class="assort clearfix"] li[@class="two"] span').text() # 表显里程
d['secprice'] = content('span[@class="pricestype"]').text() # 报价
d['newprice'] = content('span[@class="newcarprice"]').text() # 新车指导价(含税)
d['address'] = content('ul[@class="assort clearfix"]').find('li').\
eq(2).find('span').text() # 上牌地
d['displacement'] = content('ul[@class="assort clearfix"]').\
find('li').eq(3).find('span').text() # 排量
return d
def run(self,n,m):
page_start = n
page_end = m
with open('guazidata{}to{}.txt'.format(page_start,page_end),'a',encoding='utf-8') as f:
for pageurl in self.page_url(page_start,page_end):
print(pageurl)
print("让俺歇歇10-15秒啦,太快会关小黑屋的!")
time.sleep(random.randint(10, 15))
for detail_url in self.detail_url(pageurl):
print(detail_url)
d = self.carinfo(detail_url)
f.write(d['model']+',')
f.write(d['registertime'] + ',')
f.write(d['mileage'] + ',')
f.write(d['secprice'] + ',')
f.write(d['newprice'] + ',')
f.write(d['address'] + ',')
f.write(d['displacement'] + '\n')
time.sleep(0.3)
self.infonumber += 1
print('爬了%d辆车,continue!'%self.infonumber)
print('+'*10)
if __name__ == '__main__':
gzcrawler = GuaziSpider()
# 这儿改数字,例如:爬取第1页到第100页的信息
gzcrawler.run(1,100)
总结:
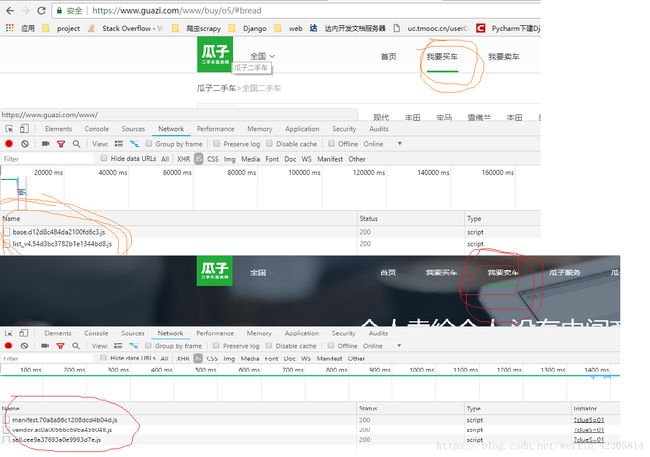
1、最开始没加cookie,然后get不全网页,然后不知道为何,本机chrome里得到的cookie怎么也不好使,这儿需要继续研究,希望懂得给说道一下。当时对比查看我要买车跟我要卖车获得的js,一度以为这些页面是js渲染防爬的,都想放弃了,幸好叫别人试了一下,才发现只要加cookie就好,我只能copy别人电脑的cookie
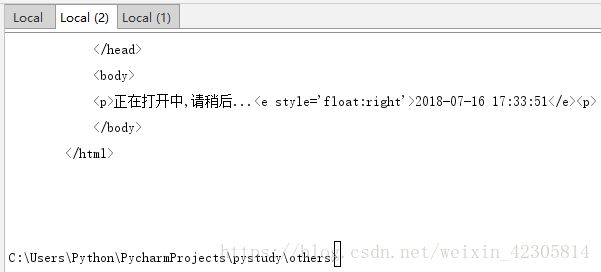
未加cookie,get不全信息显示是这样子的:
2、爬取速度过快会被封IP,只能换代理IP解决;同时速度稍快,中间就会出现爬几页然后跳过几页不爬的情况,大概每7页只能爬取一页,而且40辆车还爬不完全,原因也想不明白。具体阈值没测试,因为不急着用数据,就开了几个终端使用几个代理ip挂着慢点爬。