Hadoop环境搭建及单机、伪分布式安装问题总结(踩坑实录)
最近上了一门课,叫大数据基础,这是我第一次没有在别人的帮助下自己解决了如此多的问题,感谢百度,感谢CSDN,感谢各位大佬写的博客。我都觉得踩坑大队队长非我莫属了,怎么会有我这么笨的人,给我整懵了好了废话不多说记录一下我踩的坑。
实验名称
- Hadoop单机配置及伪分布式安装
实验环境
- 系统环境:Ubuntu 16.04.6
- JAVA版本:java openjdk 1.8.0_222
- Hadoop版本:Hadoop 3.2.1
实验过程
这个教程写的很好 点击这里打开参考教程 除了我自己笨让我踩了很多坑。
实验所遇问题
温馨提示:建议使用hadoop用户进行实验,否则可能会和我一样踩很多坑。
- 问题1:在解压Hadoop时出现如下问题,原因是有apt进程在运行
tar (child): /home/hadoop/Downloads/hadoop-x.x.x.tar.gz: Cannot open: No such file or derectory
tar (child):Error is not recoverable: exiting now
tar: Child returned status 2
tar: Error is not recoverable: exiting now
错误截图:

- 解决办法:
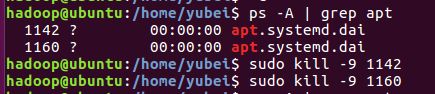
运行如下命令查看正在进行的进程
ps -A | grep apt
使用如下命令关闭进程
sudo kill -9 number
例如:此处存在进程号为1142、1160的进程在运行,使用如下命令将其关闭。
- 问题2:在执行grep例子时报错JAVA_HOME找不到,但是之前java环境都是配好的,使用“java -version”命令也可以查看到java的版本。
ERROR: JAVA_HOME is not set and could not be found.
错误截图:

- 解决办法:
sudo vim hadoop/etc/hadoop/hadoop-env.sh
使用上述语句修改 修改“hdoop-env.sh”文件中的
# export JAVA_HOME=
这一行为
# export JAVA_HOME=/usr/lib/jvm/default-java
并且添加
export JAVA_HOME=/usr/lib/jvm/default-java
(什么?找不到jdk的路径→echo &JAVA_HOME)
实际修改如下:
![]()
- 问题3:启动dfs时报错
Starting namenodes on [localhost]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [slave1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
错误截图:

- 解决办法:
如果不是用Hadoop启动的话,需将root改为对应用户
以下是Hadoop3.2.1版本解决办法,如果你是Hadoop2.x.x版本请参考这里点我点我
在/hadoop/sbin路径下,将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh,stop-yarn.sh顶部也需添加以下参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
修改后重启即可解决。
- 问题4:以为上面那个问题解决了,重新启动dfs就没问题了,结果又报错了
...
Starting namenodes on [localhost]
localhost: ERROR: Unable to write in /usr/local/hadoop/logs. Aborting.
Starting datanodes
localhost: ERROR: Unable to write in /usr/local/hadoop/logs. Aborting.
...
错误截图: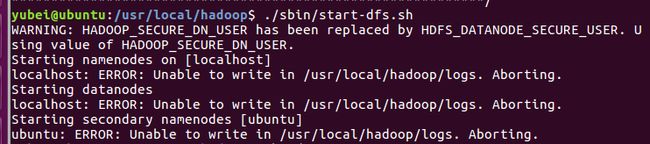
- 解决办法:
此处Warning是由于问题3中新旧版本hadoop参数不对应造成的,后续已解决,可无视。
出现Unable to write问题的原因是因为写入权限不够,因此需将权限给对应的文件夹
执行如下代码:
sudo chmod -R 777 /usr/local/hadoop/logs
实际运行如下:
![]()
- 问题5:我以为上面那个问题解决了,就真的没有问题了,结果给了权限以后又出现了Permission denied的问题。
...
Starting namenodes on [localhost]
localhost: Permission denied (publickey,password)
Starting datanodes
localhost: Permission denied (publickey,password)
...
错误截图:
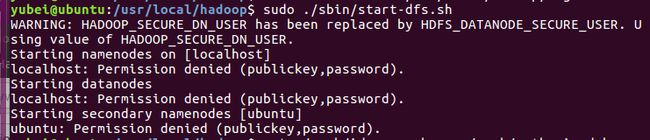
- 解决办法:
重新格式化节点,报错,重新配置ssh还是报错,在Permission denied一下午了之后我思考了一下到底是什么原因,此处总结为用户yubei没有对hadoop的操作权限,所以我是开错了账号,为了避免出现更多问题,我选择了最笨的办法→重新安装了虚拟机重做。(其实上面问题3中有一步需要修改root为实际调用用户yubei,尝试了一下没有成功,所以选择重来,如果是用hadoop用户不会有此问题)
在重新安装虚拟机使用Hadoop用户进行实验后,实验变得顺畅了很多,遇到相同的问题都通过上面的办法解决了,接下来遇到一个新的问题。
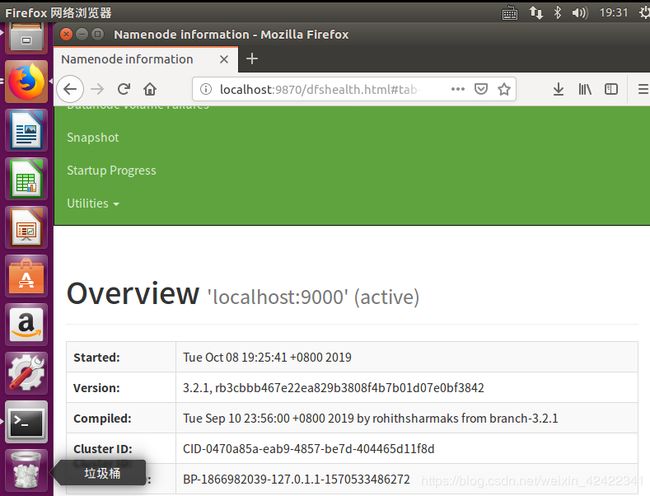
- 问题6:http://localhost:50070 端口错误打不开
- 解决办法:教程中的版本为Hadoop 2.x.x,我的版本是Hadoop 3.x.x,端口不同所以对不上。将端口修改为9870即可解决。即打开 http://localhost:9870
实验结果
- 单机配置运行实例grep结果如下:

- 伪分布式配置运行实例WordCount结果如下(部分截图):

实验心得
需要补一下Linux基础操作语句,遇到问题先百度 不要着急,静下心来你一定可以解决的。纠错QQ2533285193