pytorch cycleGAN代码学习1
一. 新的东西
p.s :很多架构都和之前一样,就举些不同的
1. ReplayBuffer()
# Buffers of previously generated samples
fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()
这是什么??看看utils.py中的
class ReplayBuffer():
def __init__(self, max_size=50):
assert (max_size > 0), 'Empty buffer or trying to create a black hole. Be careful.'
self.max_size = max_size
self.data = []
def push_and_pop(self, data):
to_return = []
for element in data.data:
element = torch.unsqueeze(element, 0)
if len(self.data) < self.max_size:
self.data.append(element)
to_return.append(element)
else:
if random.uniform(0,1) > 0.5:
i = random.randint(0, self.max_size-1)
to_return.append(self.data[i].clone())
self.data[i] = element
else:
to_return.append(element)
return Variable(torch.cat(to_return))push and pop这是buffer的进栈和入栈?先理解为为了训练稳定把。以后遇到再补充,网上资源好少。
补充:
通过对训练过程的学习发现,生成器生成的 fake 图片还要经过另一生成器,生成 cycle 图片
所以通过该buffer函数寄存 fake 图片,用于判别器更新?算有了点感性认识把。
2. patchGAN
# Calculate output of image discriminator (PatchGAN)
patch = (1, opt.img_height // 2**4, opt.img_width // 2**4)p.s: patch大小为16x16,前一篇也用到了,网上资源也好少,举下大神们的见解
(pix2pix : pix2pix和SRGAN的一个异曲同工的地方是都有用重建解决低频成分,用GAN解决高频成分的想法。在pix2pix中,这个思想主要体现在两个地方。一个是loss函数,加入了L1 loss用来让生成的图片和训练的目标图片尽量相似,而图像中高频的细节部分则交由GAN来处理:
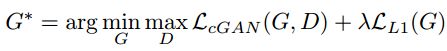
还有一个就是PatchGAN,也就是具体的GAN中用来判别是否生成图的方法。PatchGAN的思想是,既然GAN只负责处理低频成分,那么判别器就没必要以一整张图作为输入,只需要对NxN的一个图像patch去进行判别就可以了。这也是为什么叫Markovian discriminator,因为在patch以外的部分认为和本patch互相独立。
具体实现的时候,作者使用的是一个NxN输入的全卷积小网络,最后一层每个像素过sigmoid输出为真的概率,然后用BCEloss计算得到最终loss。这样做的好处是因为输入的维度大大降低,所以参数量少,运算速度也比直接输入一张快,并且可以计算任意大小的图。作者对比了不同大小patch的结果,对于256x256的输入,patch大小在70x70的时候,从视觉上看结果就和直接把整张图片作为判别器输入没什么区别了)
(字体MC-GAN: Discriminator 引用了 PatchGAN [1]的思想,即在公共网络加了 3 层卷积层采用了 21 × 21 Local Discriminator 去衡量局部真假,然后又在公共网络上平行加了 2 层作为 Global Discriminator 去衡量整个图片的真假。)
数字图像处理?低频部分L1loss, 高频部分用patchGAN。
以下是本篇关于patch部分的代码
# Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *patch))), requires_grad=False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *patch))), requires_grad=False)
#...
loss_GAN_AB = criterion_GAN(D_B(fake_B), valid)对比一下没用patch的某篇文章的代码
valid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)
#...
d_real_loss = adversarial_loss(validity_real, valid)嗯哼,原来是将valid改成16x16的去计算D的loss
二. Models
1. GeneratorResNet
生成器采用ResNet

##############################
# RESNET
##############################
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
conv_block = [ nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features) ]
self.conv_block = nn.Sequential(*conv_block)
def forward(self, x):
return x + self.conv_block(x)
class GeneratorResNet(nn.Module):
def __init__(self, in_channels=3, out_channels=3, res_blocks=9):
super(GeneratorResNet, self).__init__()
# Initial convolution block
model = [ nn.ReflectionPad2d(3),
nn.Conv2d(in_channels, 64, 7),
nn.InstanceNorm2d(64),
nn.ReLU(inplace=True) ]
# Downsampling
in_features = 64
out_features = in_features*2
for _ in range(2):
model += [ nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True) ]
in_features = out_features
out_features = in_features*2
# Residual blocks
for _ in range(res_blocks):
model += [ResidualBlock(in_features)]
# Upsampling
out_features = in_features//2
for _ in range(2):
model += [ nn.ConvTranspose2d(in_features, out_features, 3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True) ]
in_features = out_features
out_features = in_features//2
# Output layer
model += [ nn.ReflectionPad2d(3),
nn.Conv2d(64, out_channels, 7),
nn.Tanh() ]
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)可视化:

2. Discriminator
##############################
# Discriminator
##############################
class Discriminator(nn.Module):
def __init__(self, in_channels=3):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalize=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(in_channels, 64, normalize=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1)
)
def forward(self, img):
return self.model(img)
源代码网址:https://github.com/eriklindernoren/PyTorch-GAN/tree/master/implementations/cyclegan