Python爬虫之多线程图虫网数据爬取(十六)
原创不易,转载前请注明博主的链接地址:Blessy_Zhu https://blog.csdn.net/weixin_42555080
本次代码的环境:
运行平台: Windows
Python版本: Python3.x
IDE: PyCharm
一、 前言
今天要爬取的网站是图虫网(网址:https://tuchong.com/explore/),这是一个个人非常喜欢的图片分享展示和交流的平台。上面的作品质量非常高,对于我这个摄影小白来说是一个非常不错的学习和欣赏大家作品的优质平台。没有做广告哦,只是纯属个人喜欢的推荐。本篇博文的主要内容是利用队列数据存取以及多线程爬虫的方法爬取图虫网上面的图片数据。好啦,ENOUGH TALK,LET‘S START IT!!!!!!!!!!!
二、思路过程
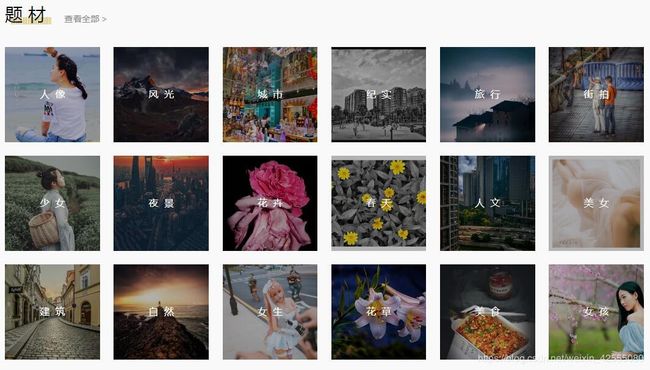
对于上面图片上的题材,想必广大宅男们肯定和我一样,会毫不犹豫的选择——风光。别问为什么,作为宅男,天天宅在家里,哪有时间旅游去欣赏自然风光。所以还不如下载一下图片聊以慰藉。![]()
好,继续继续!!!!!!

首先点开风光图,一直下来,可以看到一个点击加载更多的按钮,这说明它的数据传输方式是AJAX。
 接下里摁下F12,找到Network,点击XHR,然后刷新,接着点击加载更多发现通过AJAX传过来的数据包就会又出现一个。可以看到这些发过来的数据包很有规律,它们的命名都是
接下里摁下F12,找到Network,点击XHR,然后刷新,接着点击加载更多发现通过AJAX传过来的数据包就会又出现一个。可以看到这些发过来的数据包很有规律,它们的命名都是
posts?page={ }&count=20&order=weekly也就是只有page属性的值在改变。
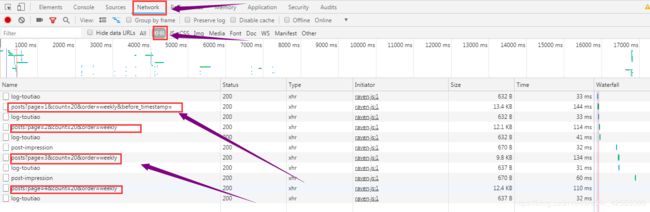
接下来看一下它的请求URL(Request URL):https://tuchong.com/rest/tags/风光/posts?page={}&count=20&order=weekly ,也是只有page属性改变。这下子就太好了!!!

然后访问Request URL,wonderful!!!!!!!!!!!拿到数据了,而且这个数据还是字典型的。那就更Easy了!!!
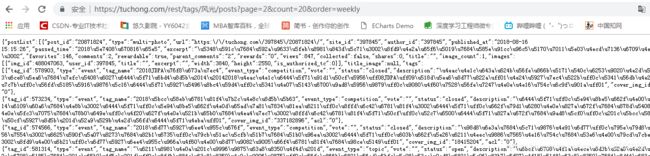
继续探究,点开preview,可以看到,这些AJAX数据。

随便点开一个,看看它里面的内容,这里面的内容几乎是我们可见即可爬的全部数据,”但是如水三千,只取一瓢饮“,既然是只下载图片,那么就只看一个属性就可以:cover_image_src: “https://photo.tuchong.com/397845/g/488047063.webp”,可以看到他的值除了两部分数字,其他都是固定的,这样只需要搞懂那两部分数字是干什么的就可以了。通过观察可以看到,前一部分数字实际上就是属性author_id的值,后一部分实际上就是属性img_id的值,而这两个值,通过字典的方式就可以获取,这样就可以拼接成一个完整的图片下载地址了:
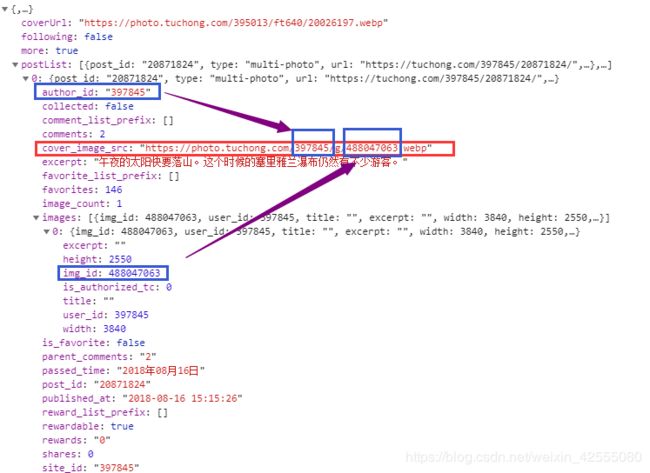
通过上面的过程,可以准确的找到一个完整数据包的访问地址,每个完整数据包包括20个图片信息。然后通过访问数据包可以将图片的下载地址进行拼接,从而最后实现图片的下载。
思路已经清晰啦,接下来就开始爬取代码的编写吧!!!!
三、代码及结果分析展示
3.1 queue相关知识
本次使用python中的queue,也就是队列来模拟数据的存取过程。
首先对于基本爬虫初期,可以简单的使用到queue的知识可以如下所示:
1. 初始化: class Queue.Queue(maxsize) FIFO 先进先出
2. 包中的常用方法:
- queue.qsize() 返回队列的大小
- queue.empty() 如果队列为空,返回True,反之False
- queue.full() 如果队列满了,返回True,反之False
- queue.full 与 maxsize 大小对应
- queue.get([block[, timeout]])获取队列,timeout等待时间
3. 创建一个“队列”对象
import queue
myqueue = queue.Queue(maxsize = 10)
4. 将一个值放入队列中
myqueue.put(10)
5. 将一个值从队列中取出
myqueue.get()
6. from queue import Queue,这个数据包在Python3中是内置了,不需要安装
3.2 多线程框架
首先先实现多线的框架:
import threading
for queue import Queue
class ThreadCrawl(threading.Thread):
def __init__(self, thread_name, page_queue, data_queue):
# threading.Thread.__init__(self)
# 调用父类初始化方法
super(ThreadCrawl, self).__init__()
self.threadName = thread_name
self.page_queue = page_queue
self.data_queue = data_queue
def run(self):
print(self.threadName + ' 启动************')
def main():
# 声明一个队列,使用循环在里面存入100个页码
page_queue = Queue(100)
for i in range(1,101):
page_queue.put(i)
# 采集结果(等待下载的图片地址)
data_queue = Queue()
# 记录线程的列表
thread_crawl = []
# 每次开启4个线程
craw_list = ['采集线程1号','采集线程2号','采集线程3号','采集线程4号']
for thread_name in craw_list:
c_thread = ThreadCrawl(thread_name, page_queue, data_queue)
c_thread.start()
thread_crawl.append(c_thread)
# 等待page_queue队列为空,也就是等待之前的操作执行完毕
while not page_queue.empty():
pass
if __name__ == '__main__':
main()
运行结果:

线程已经开启,在run方法中,补充爬取数据的代码就好了,这个地方引入一个全局变量,用来标识爬取状态
CRAWL_EXIT = False
CRAWL_EXIT = False
class ThreadCrawl(threading.Thread):
def __init__(self, thread_name, page_queue):
# threading.Thread.__init__(self)
# 调用父类初始化方法
super(ThreadCrawl, self).__init__()
self.threadName = thread_name
self.page_queue = page_queue
def run(self):
print(self.threadName + ' 启动************')
while not CRAWL_EXIT:
try:
#global tag, url, img_format # 把全局的值拿过来
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', }
# 队列为空 产生异常
page = self.page_queue.get(block=False) # 从里面获取值
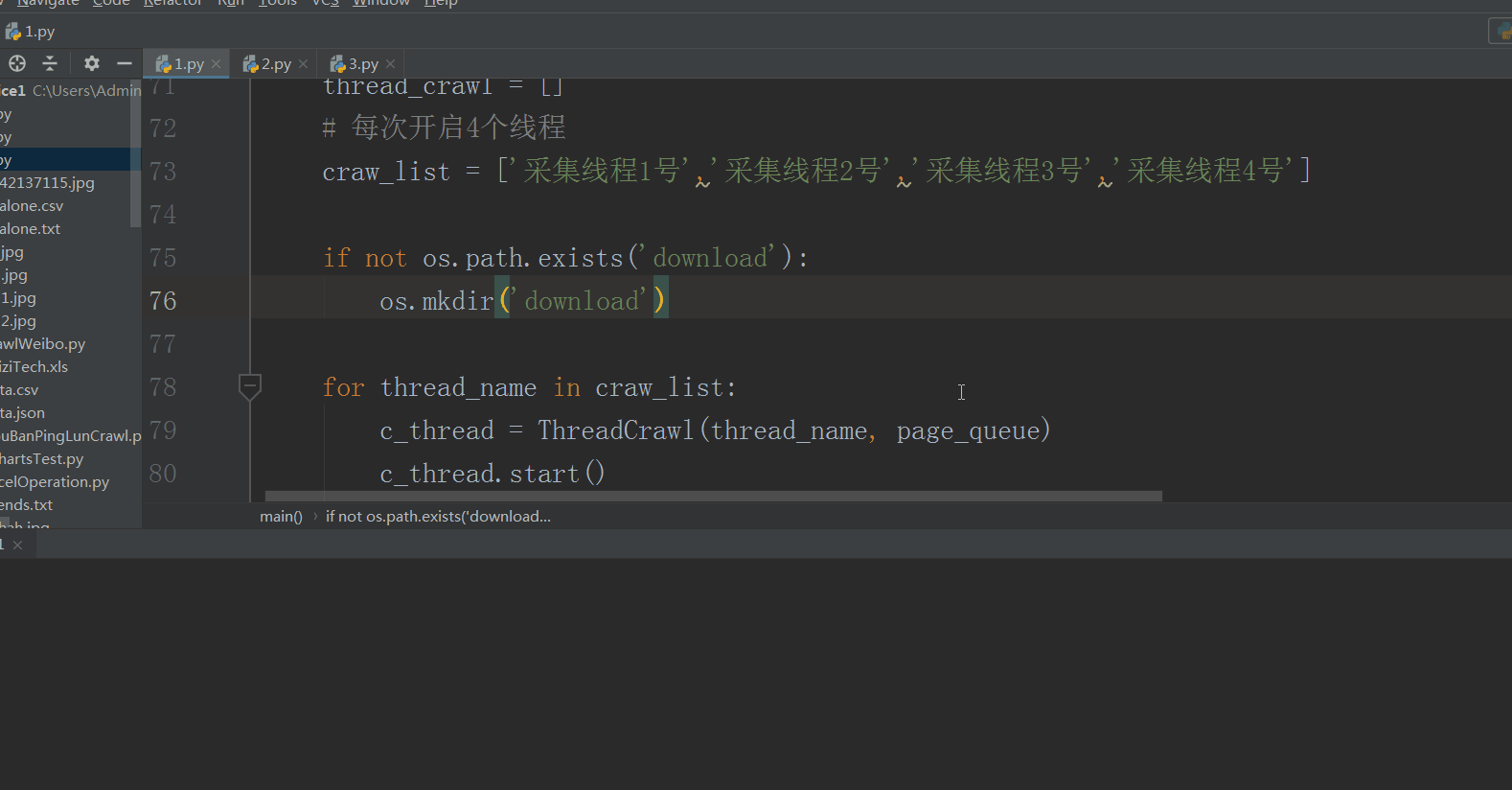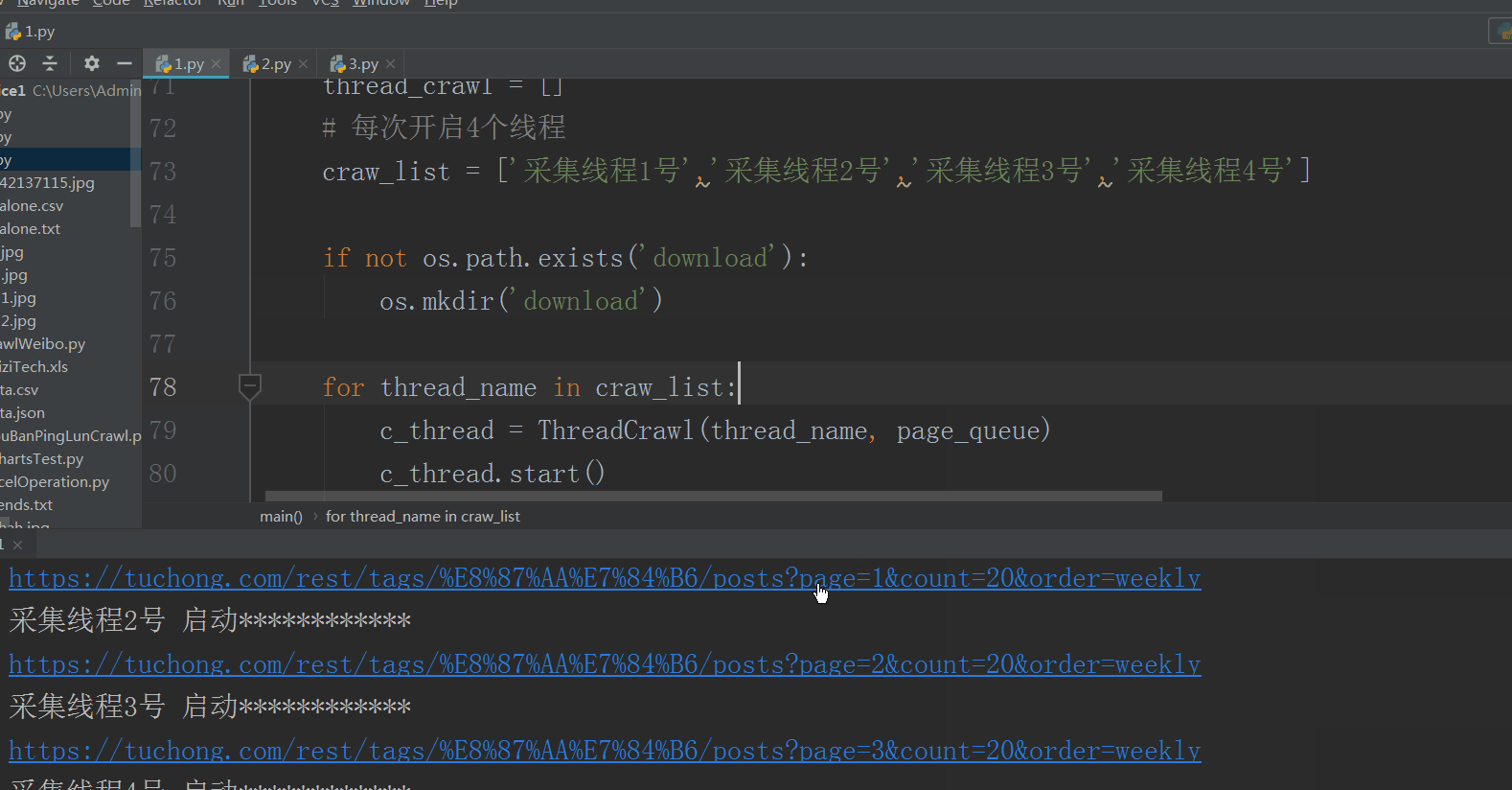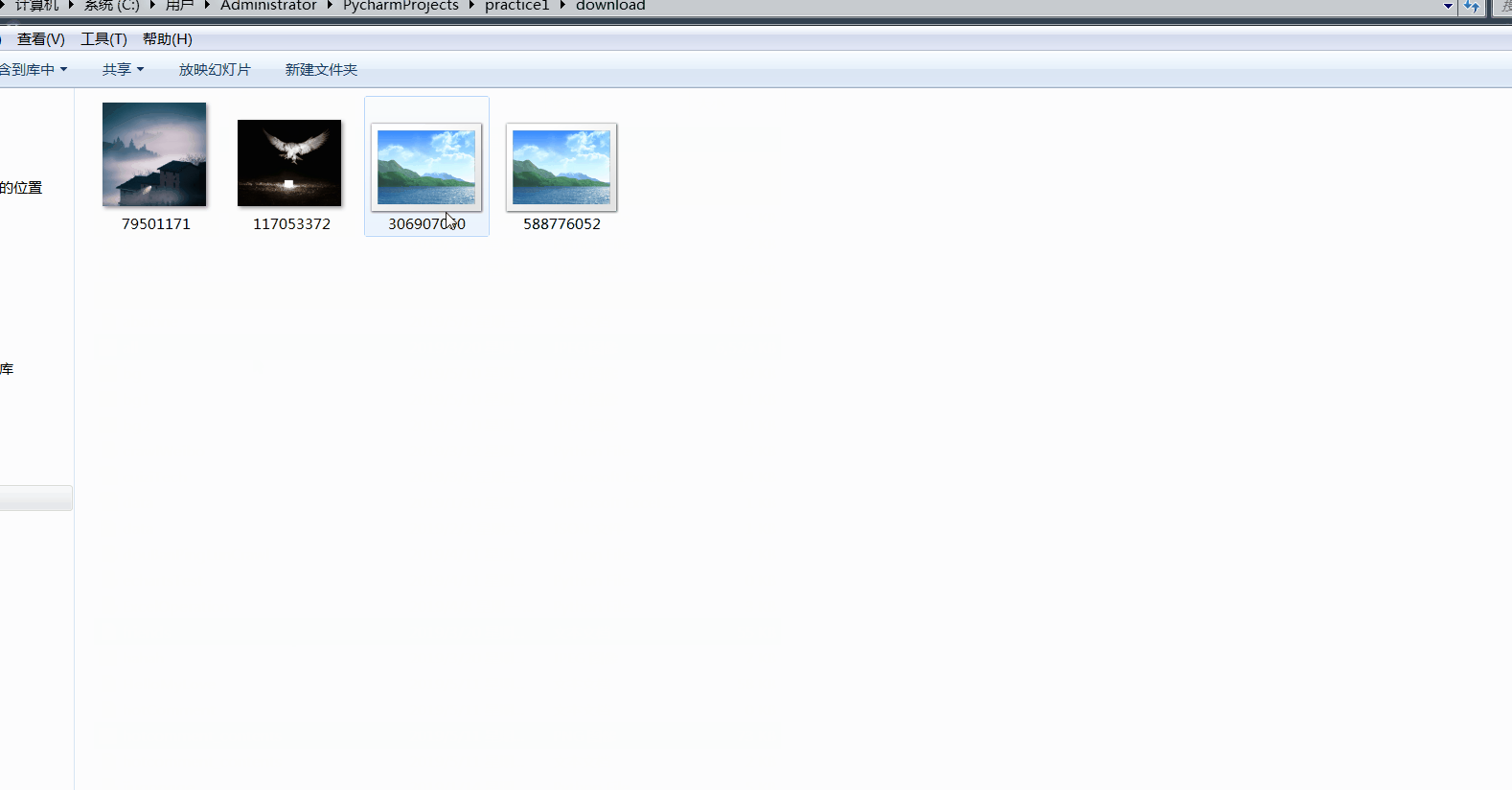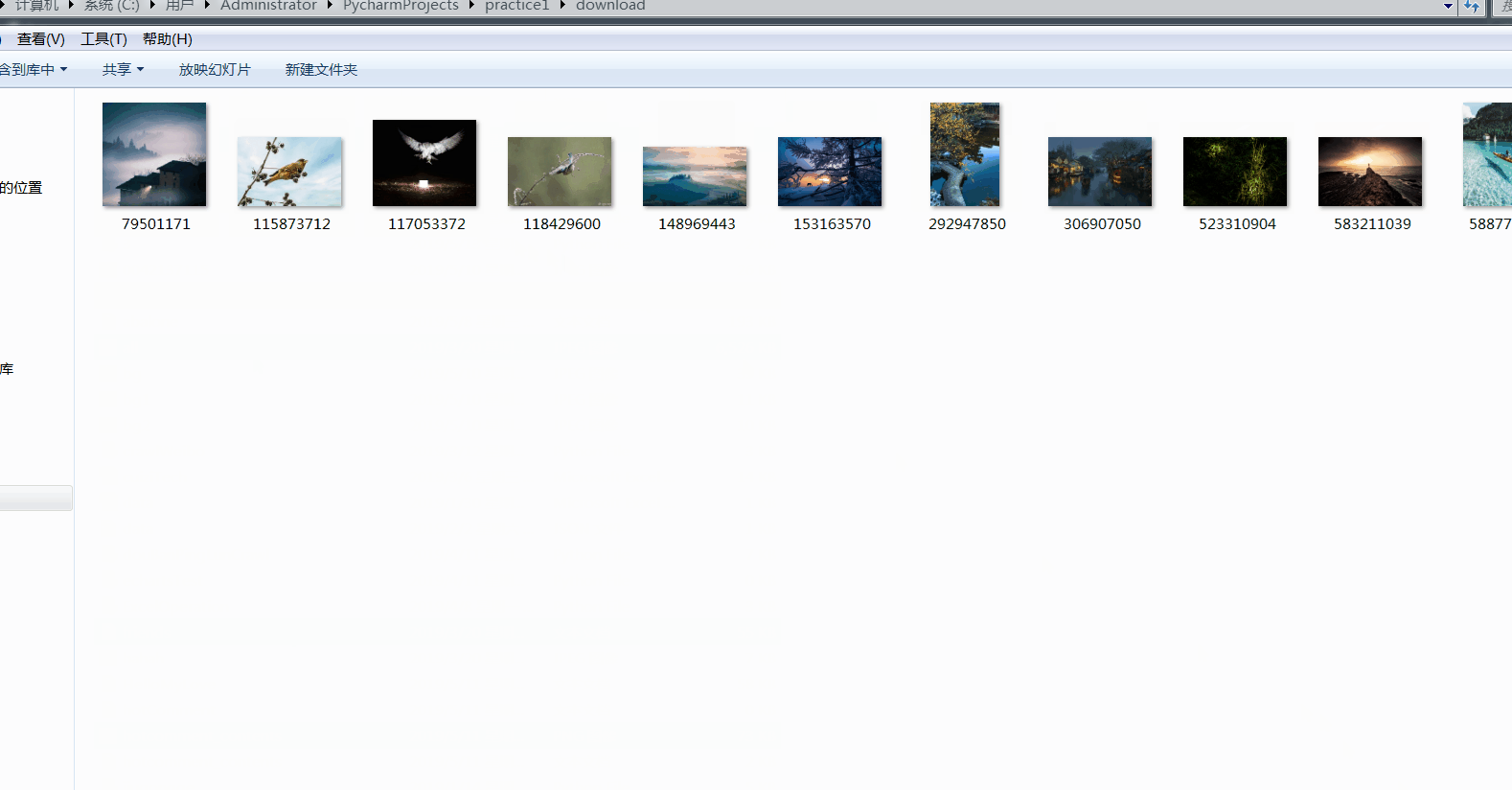
spider_url = 'https://tuchong.com/rest/tags/%E8%87%AA%E7%84%B6/posts?page={}&count=20&order=weekly'.format(page)
print(spider_url)
except:
break
timeout = 4 # 合格地方是尝试获取3次,3次都失败,就跳出
while timeout > 0:
timeout -= 1
try:
with requests.Session() as s:
response = s.get(spider_url, headers=headers, timeout=3)
json_data = response.json()
if json_data is not None:
imgs = json_data["postList"]
for i in imgs:
imgs = i["images"]
for img in imgs:
user_id = img["user_id"]
img_id = img["img_id"]
img_url = 'https://photo.tuchong.com/{}/f/{}.jpg'.format(user_id, img_id)
#self.data_queue.put(img_url) # 捕获到图片链接,之后,存入一个新的队列里面,等待下一步的操作
title = 'download/' + str(img_id)
response = requests.get(img_url)
# 保存图片名字有问题,不知道会不会重复
with open(title + '.jpg', 'wb') as f:
f.write(response.content)
time.sleep(3)
break
except Exception as e:
print(e)
if timeout <= 0:
print('time out!')
然后在main函数中添加如下代码:
......
while not page_queue.empty():
pass
# 如果page_queue为空,采集线程退出循环
global CRAWL_EXIT
CRAWL_EXIT = True
结果如下:
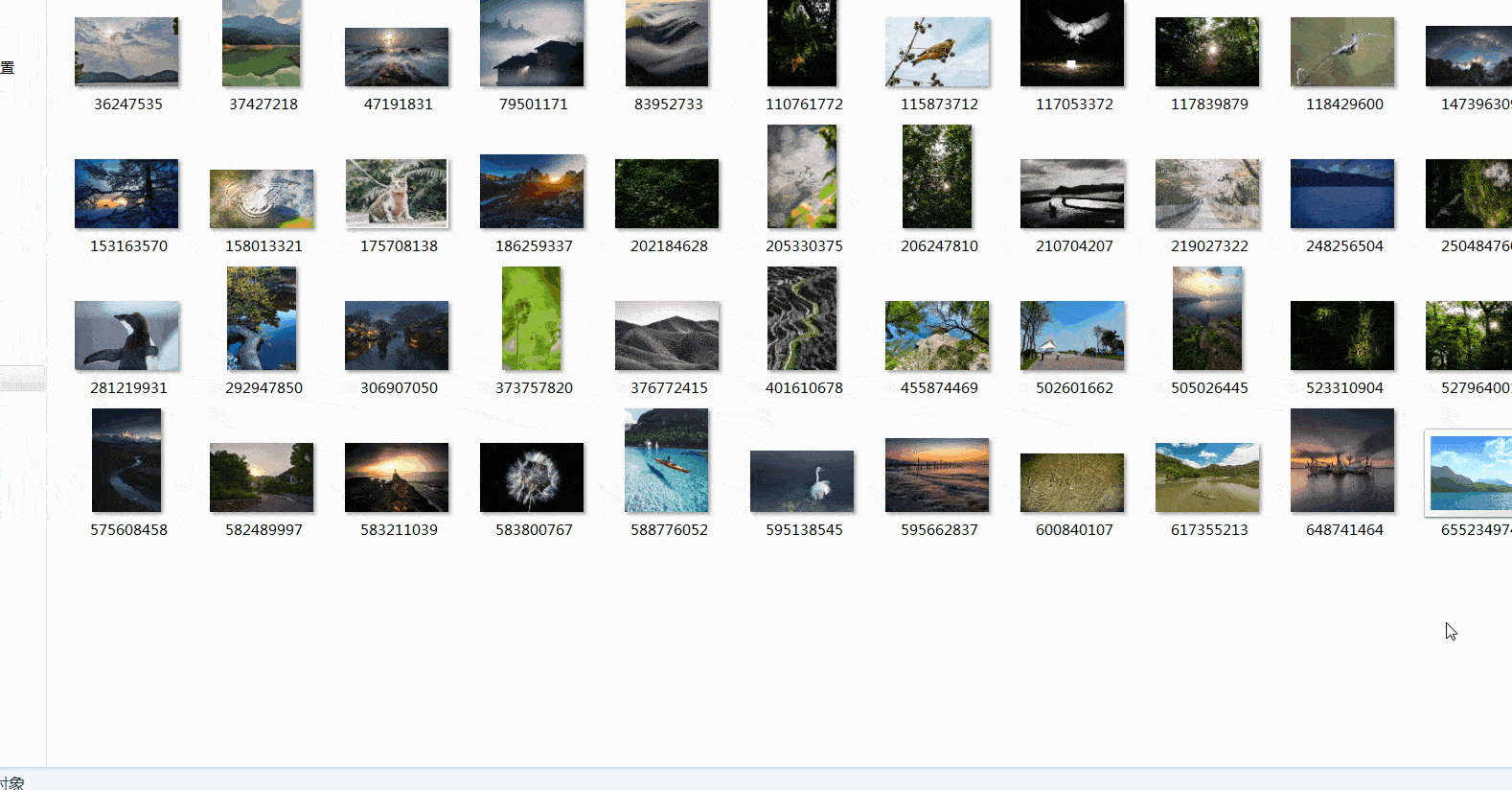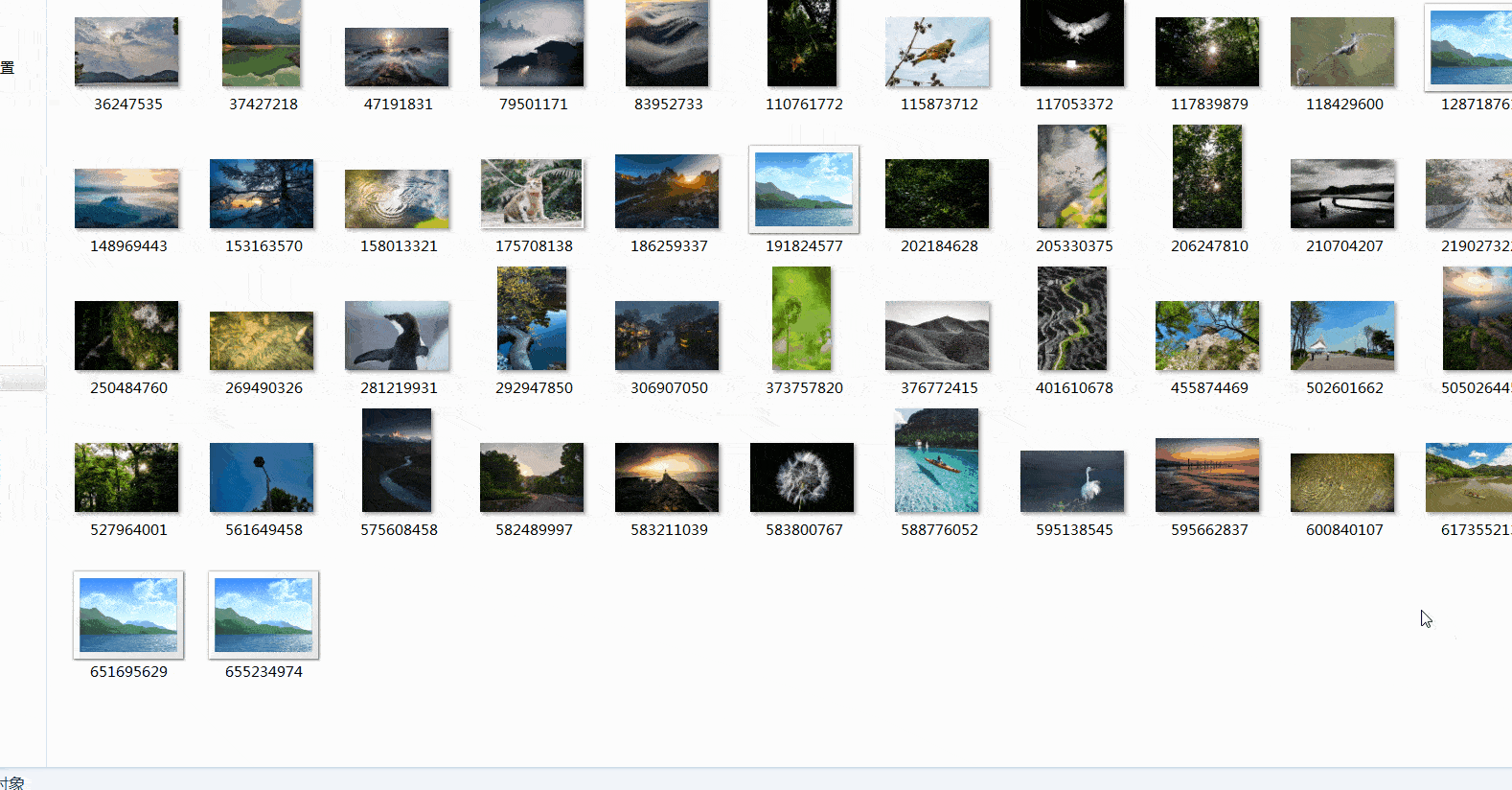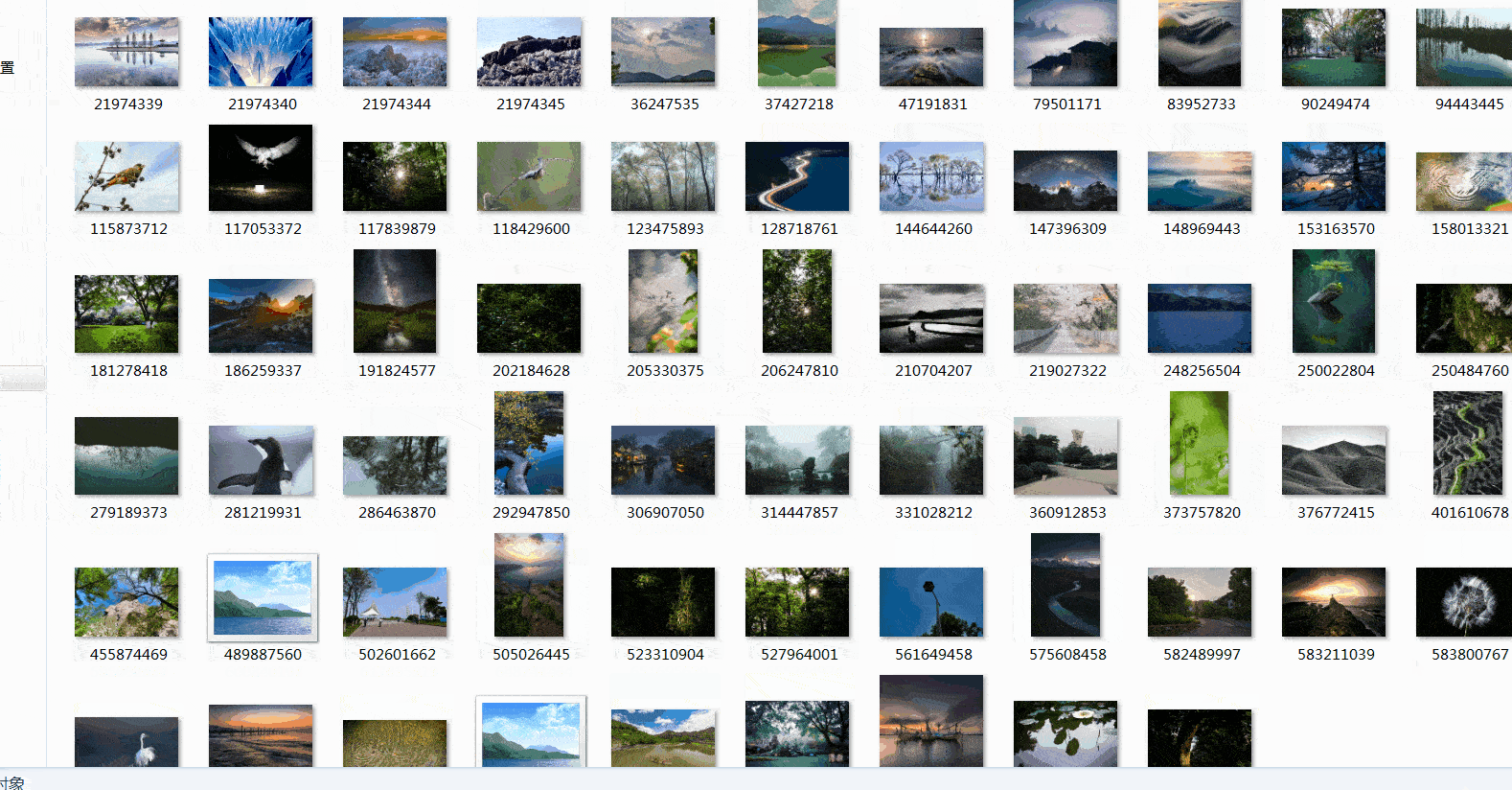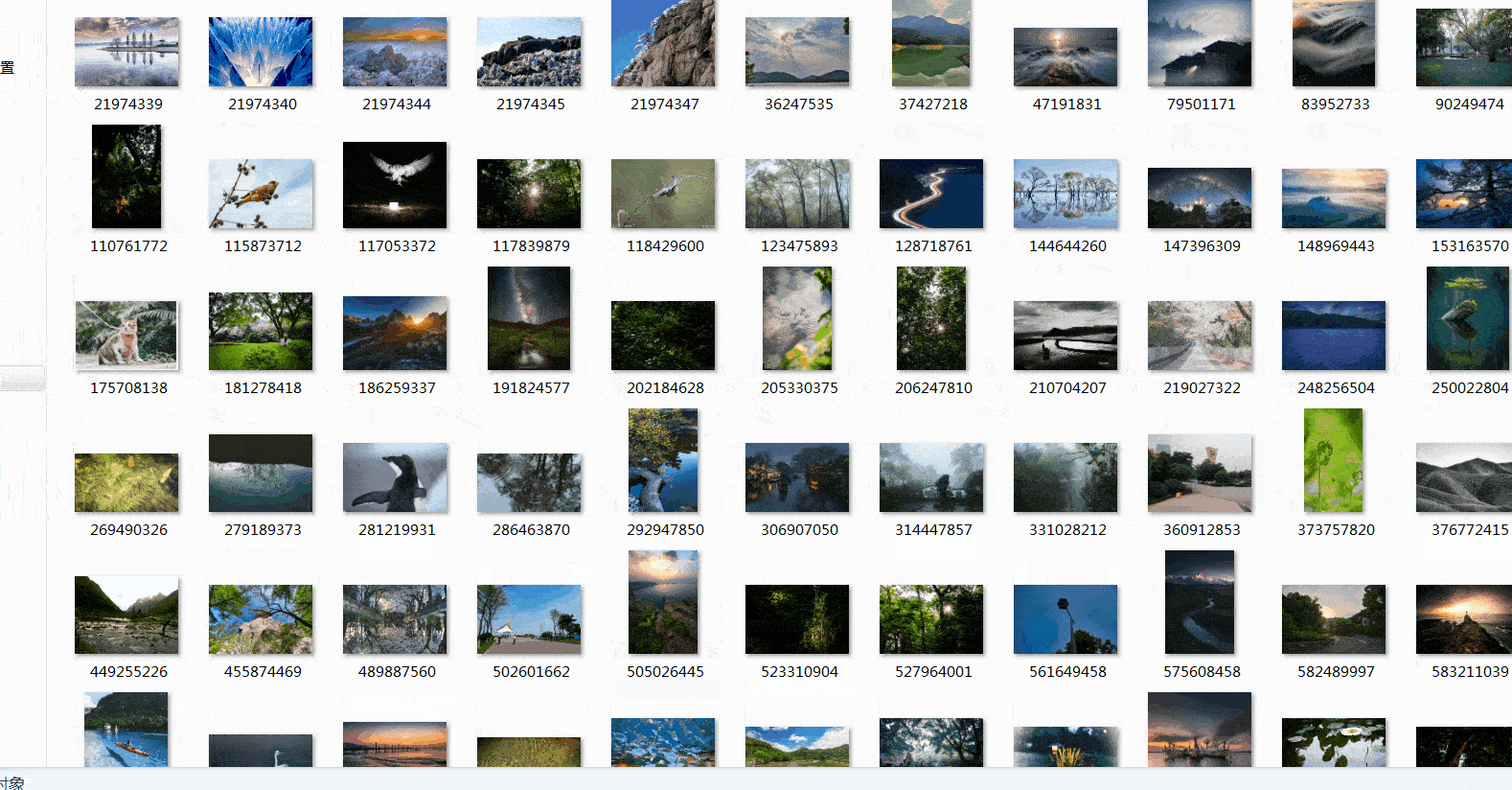
四、总结
这篇文章是图虫网图片数据的爬取,用到了队列的思想存取数据,同时采用多线程提高速度。这篇文章就到这里了,欢迎大佬们多批评指正,也欢迎大家积极评论多多交流。

附完整代码:
import threading
from queue import Queue
import requests
import os
import time
CRAWL_EXIT = False
class ThreadCrawl(threading.Thread):
def __init__(self, thread_name, page_queue):
# threading.Thread.__init__(self)
# 调用父类初始化方法
super(ThreadCrawl, self).__init__()
self.threadName = thread_name
self.page_queue = page_queue
def run(self):
print(self.threadName + ' 启动************')
while not CRAWL_EXIT:
try:
#global tag, url, img_format # 把全局的值拿过来
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', }
# 队列为空 产生异常
page = self.page_queue.get(block=False) # 从里面获取值
spider_url = 'https://tuchong.com/rest/tags/%E8%87%AA%E7%84%B6/posts?page={}&count=20&order=weekly'.format(page)
print(spider_url)
except:
break
timeout = 4 # 合格地方是尝试获取3次,3次都失败,就跳出
while timeout > 0:
timeout -= 1
try:
with requests.Session() as s:
response = s.get(spider_url, headers=headers, timeout=3)
json_data = response.json()
if json_data is not None:
imgs = json_data["postList"]
for i in imgs:
imgs = i["images"]
for img in imgs:
user_id = img["user_id"]
img_id = img["img_id"]
img_url = 'https://photo.tuchong.com/{}/f/{}.jpg'.format(user_id, img_id)
#self.data_queue.put(img_url) # 捕获到图片链接,之后,存入一个新的队列里面,等待下一步的操作
title = 'download/' + str(img_id)
response = requests.get(img_url)
# 保存图片名字有问题,不知道会不会重复
with open(title + '.jpg', 'wb') as f:
f.write(response.content)
time.sleep(3)
break
except Exception as e:
print(e)
if timeout <= 0:
print('time out!')
def main():
# 声明一个队列,使用循环在里面存入100个页码
page_queue = Queue(100)
for i in range(1,101):
page_queue.put(i)
# 采集结果(等待下载的图片地址)
#data_queue = Queue()
# 记录线程的列表
thread_crawl = []
# 每次开启4个线程
craw_list = ['采集线程1号','采集线程2号','采集线程3号','采集线程4号']
if not os.path.exists('download'):
os.mkdir('download')
for thread_name in craw_list:
c_thread = ThreadCrawl(thread_name, page_queue)
c_thread.start()
thread_crawl.append(c_thread)
# 等待page_queue队列为空,也就是等待之前的操作执行完毕
while not page_queue.empty():
pass
# 如果page_queue为空,采集线程退出循环
global CRAWL_EXIT
CRAWL_EXIT = True
if __name__ == '__main__':
main()