Python学习之爬取微博评论
前言
2020年4月23日,是吃瓜群众最劲爆的一天,各大自媒体平台都有罗志祥被爆出轨的头条。大家刷抖音的时候想必应该看过这样的评论:“全体渣男起立,向祖师爷致敬!”。看到这些信息的时候,你是否有个疑问:“同样是男的,他为何如此优秀!?”那么,单身程序员如何才能找到对象?
这里重点说下罗志祥的时间管理案例:一边参加综艺,一边边和这么多人保持不正当联系,凌晨三四点也要跟女朋友说晚安,这时间管理真的是天下无敌。
今天我也想看看网友们都是怎么样评论的,所有做了个微博的爬虫
第一步:分析网站
爬虫的步骤都是老生长谈了,第一步肯定是分析网站了。当然,这个可不是静态网页,所以要还是要拿到api接口数据。
今天,爬的内容是手机端的微博,今天要爬的网址是:https://m.weibo.cn/detail/4497103885505673
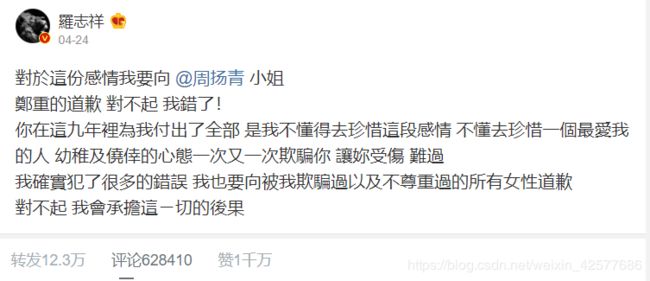
爬取的评论是上图的最新微博评论。首先,评论这些都是动态加载的数据,不同于静态网页,可以很方便的直接从HTML网页里面获取到你想要的信息。那么我们应该如何拿到API接口数据呢?
还是和往常一样,打开开发者模式,点击network,一般来说(以往的经验)API接口数据都是存放在XRH中

接下来

点开之后你就会惊讶的发现

这就是我们朝思暮想的数据,它的数据是json格式的,一般接口数据都是json格式的。
当我们点开data下的data时你会发现,只有18条数据,

妈耶,这也太尴尬了,这不是我要的结果啊,怎么办呢?
没办法,继续将评论往下翻,我居然发现了这个:
发现居然多
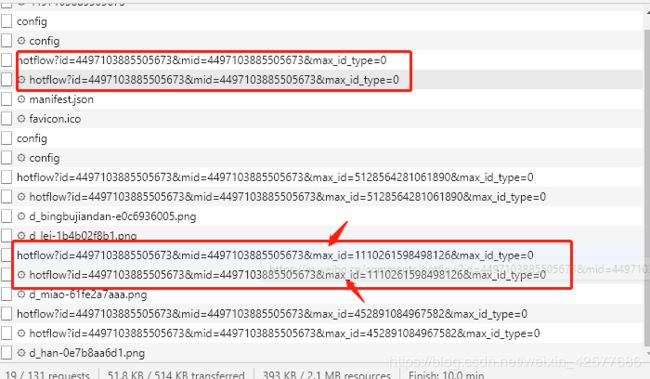
个查询参数,max_id 。这个参数是怎么样出现的呢?点开之后发现每一页评论的max_id 其实都是不一样的。
![]()
其实并没有多一个查询参数,第一个只是被隐藏了起来,那么分析到了这里我就基本上明白怎么回事了。主要的查询参数主要有四个:id mid max_id max_id_type
第二步:请求数据
我们都知道哦,Python是面向对象编程的语言,那么我们今天就用面向对象的方式来获取数据
首先,还是要导入几个爬虫的常用第三方库,再定义几个必要的全局变量
import requests
import random
import time
class Main(object):
url = 'https://m.weibo.cn/comments/hotflow?'
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6:
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25",
]
headers = {'User-Agent': random.choice(user_agent),
'Cookie':'_T_WM=67954101541; WEIBOCN_FROM=1110006030; ALF=1590415353; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WhN5rhgG_uShngJOGPuYWdQ5JpX5K-hUgL.FoqE1h-pSh-E1hB2dJLoI0YLxK-L1KqL1-eLxKqLB-eLBKzLxK-LB--L1h-LxKML1-2L1hBLxKnL1heL12eLxK-L12eL1h-LxK-LB--LBKzt; MLOGIN=1; SCF=Ah6JwxSMn5LDB0ydZ9Vj5ZHhwj7C7bszFmMgek6bWfeg52_oVVdr0AmgYn-DBeHwC8E8EE7IIdOuaGMeETrvfOk.; SUB=_2A25zoDkKDeRhGeBM41cQ9CvOwziIHXVRa0dCrDV6PUJbktANLRDzkW1NRKhXeh3SU4V1v-Nwt_Nz0gDSz0bgGotq; SUHB=0pHxwnzn4f_iPS; SSOLoginState=1587824986; XSRF-TOKEN=3f8415; M_WEIBOCN_PARAMS=oid%3D4497103885505673%26luicode%3D20000061%26lfid%3D4497103885505673%26uicode%3D20000061%26fid%3D4497103885505673',
'Referer':'https://m.weibo.cn/detail/4497103885505673',
'Sec-Fetch-Mode':'navigate'
}
params = {}
list_text = []
file = './'
proxies = {
'http':'http://118.113.247.115:9999',
'https': 'https://118.113.247.115:9999'
}接下来就是要获取到max_id和max_id_type
def get_max_id(self):
response = requests.get(url=self.url, headers=self.headers,params=self.params).json()
# print(response)
max_id = response['data']['max_id']
max_id_type = response['data']['max_id_type']
data = response['data']['data']
for i in range(0, len(data)):
text = data[i]['text']
print(text)
self.list_text.append(text)
return max_id, max_id_type在这里,可以做一下解释就是函数的返回值可以是多个,以元组的形式存在,比如(max_id, max_id_type)
接下来还是要回到我们的初始化函数内:
ef __init__(self):
num_page = int(input('请输入你要爬的页数'))
ID = input('请输入你要爬取内容的id:')
return_info = ('0', '0')
for i in range(0, num_page):
print(f'正在爬取第{i + 1}页')
time.sleep(20)
self.params = {
'id': ID,
'mid': ID,
'max_id': return_info[0],
'max_id_type': return_info[1]
}
return_info = self.get_max_id()
self.save_data()这里主要做的就是将制作查询参数
最后就是要保存数据至txt文件
def save_data(self):
for text in self.list_text:
with open('weibo.txt', 'a', encoding='utf-8') as f:
f.write(text)
f.write('')
f.write('\n')那么,至此基本上就解决了,评论就到手了。
拿到这

些评论之后,我敲键盘的两只手都在颤抖啊,我也是两部手机,一部明着用,另一部明着用,哈哈。黑眼圈还很严重,这是典型的渣男表现啊。完了,一群无辜的人就这样躺枪了,所有程序员们都站起来抗议吧!!嗯,我是撸代码撸黑圆圈的......
如果上面的评论,这样看的话,感觉一点都不好看,什么是热评都不知道。
所以我就做个词云,如下图所示:

看了上面的词云效果是不是舒服很多
致谢
好了,到这里又要跟大家说再见的时候了。希望我的文章能带给您知识,带给您欢笑!同时也谢谢您能抽出宝贵的时间阅读,创作不易,如果您喜欢的话,点个关注再走吧。您的支持是我创作的动力,希望今后能带给大家更多优质的文章。