Python爬虫之商情报网站的数据
简介:很多网站上,都会以表格的形式展示数据,而我们获取这种数据只需要通过几十行代码就可以搞定网页爬虫,实现高效办公
之前有位朋友和我说需要迁移某站的数据,经过分析发现他网站的数据主要是以表格的形式保存,那这样就简单很多了。所以今天就写了关于爬取表格数据的爬虫小程序。
知识点
爬虫基本原理
requests库的简单使用
pandas库
开发环境
windows10
pycharm2020.1
获取网页信息
URL地址:https://s.askci.com/stock/a/0-0?reportTime=2020-03-31&pageNum=1#QueryCondition
在这个网页中有四个表格数据。
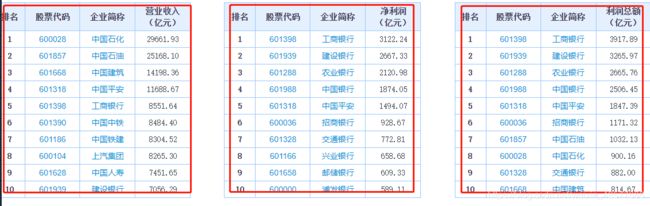
我们需要获取的是最后一个表格的数据。获取数据的方法有很多,可以通过正则表达式、xpath语法,beautifulsoup。
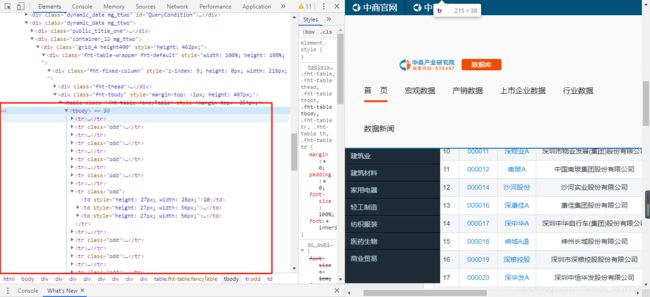
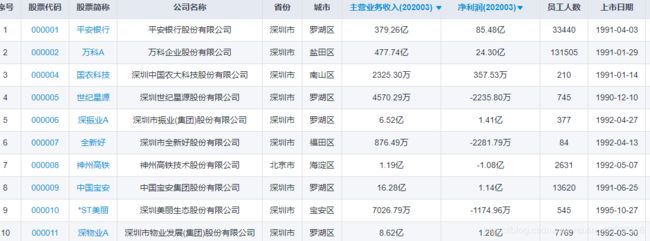
从上图可以看出,我们需要的数据都保存在表格中,所以在这里可以使用pandas库获取表格数据。在pandas库中有一个方法read_html方法可以直接读取网页中的table,然后通过遍历出每一个表,然后将表转化成DataFrame数据即可保存在csv文件中。pandas是非常常用的数据处理库。
首先导入必要的第三方库,及构建headers头信息
import requests
import pandas as pd
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'
}

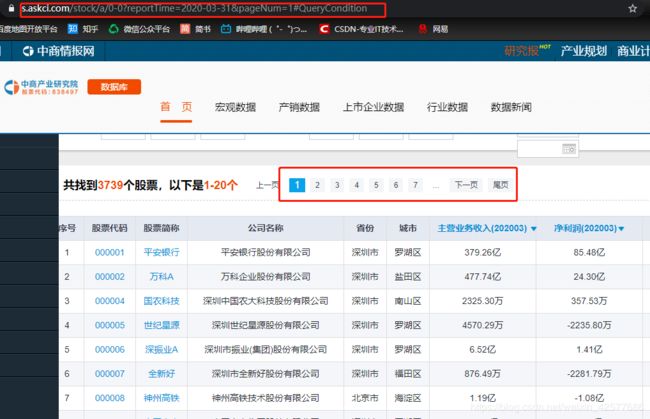
从上面两图中可以看出,要做URL地址的拼接,并且url地址会根据页码的不同而发生改变,但是这个改变是有规律的。当pageNum=1时那么这就是第一页的数据,以此类推。
在这里需要做URL地址的拼接:

def get_html(url, page):
'''
:param url: https://s.askci.com/stock/a/0-0
:param page: pageNum
:return: html class->str
'''
params = {
'reportTime': '2019-06-30',
'pageNum': page
}
response = requests.get(url, params=params).content.decode('utf-8')
# print(url)
return response第二步提取数据
在提取数据的过程中,使用pandas库,提取表格数据。将get_html方法获取到的HTML代码传入read_html方法中,获取到第四个表格数据。
def parse_html(html):
# header 标题行,为0表示取消标题行
data = pd.read_html(html, header=0)[3] # 获取第四个表格元素
return data第三步:定义主函数并保存数据
def parse_html(html):
# header 标题行,为0表示取消标题行
data = pd.read_html(html, header=0)[3] # 获取第四个表格元素
return data在保存数据的过程中,需要做的是将主函数中获取到的每一页数据进行拼接,再保存至csv文件中。
def save_data(data_company):
# company_data = []
df = pd.concat(data_company) # 拼接表格
df.to_csv('上市公司信息5.csv', index=False, encoding='utf-8-sig')最后结果如图所示:

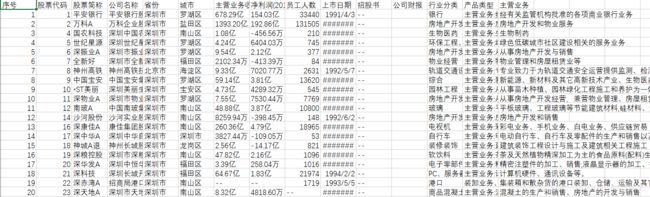
好了,到这里又要跟大家说再见的时候了。希望我的文章能带给您知识,带给您帮助!同时也谢谢您能抽出宝贵的时间阅读,创作不易,如果您喜欢的话,点个关注再走吧。您的支持是我创作的动力,希望今后能带给大家更多优质的文章。
欢迎大家关注公众号或者添加我的个人微信将第一时间获得更新
公众号回复:中商情报
即可获取源码!!

