Python+Pycharm +Scrapy搭建爬虫项目
Python+Pycharm +Scrapy搭建爬虫项目
Scrapy简介:
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中
Scrapy框架的工作流程图如下:
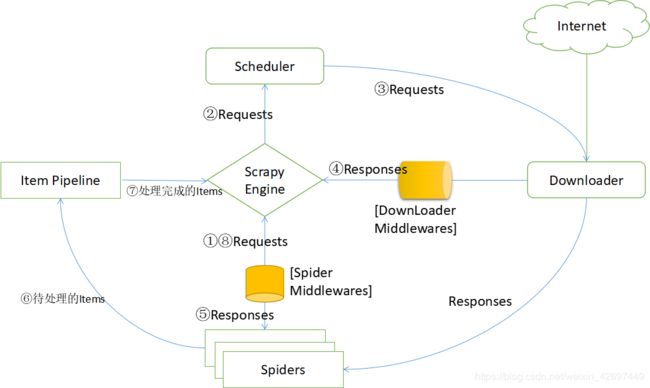
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等
Scheduler(调度器):负责接收engine发送过来的Request请求并按照一定的方式进行整理排列,入队,当engine需要时,交还给engine
Downloader(下载器):负责下载engine 发送的所有Requests请求,并将其获取到的Responses交还给Engine,由Engine交给Spider处理
Spider(爬虫):负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给engine,将URL提交给engine,再次进入Scheduler
Item Pipeline(管道):负责处理Spider中获取的Item,并经行后期处理(详细分析、过滤、存储等)的地方
Downloader Middlewares(下载中间件):自定义扩展下载功能组件,可以进行服务器代理等设置
Spider Middlewares(Spider中间件):可以自定义扩展和操作engine和Spider中间 通信的功能组件(比如进入Spider 的Responses,和从Spider出去的Requests)
一、准备工作
1.安装python3.x
2.下载PyCharm Community
3.安装Scrapy:安装好Python后,在cmd中输入以下命令 pip install scrapy
二、搭建步骤
1.创建一个爬虫项目:通过scrapy startproject命令创建
在cmd中运行命令:scrapy, 出现下图命令说明
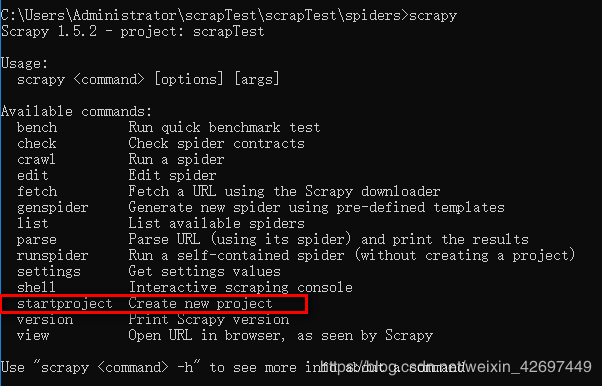
执行 scrapy startproject [项目名],会在当前目录创建一个Scrapy项目

查看创建的scrapy项目的目录结构如下(拿以下项目举例):
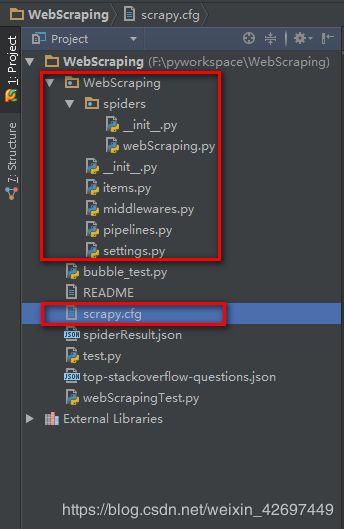
①WebScraping项目根目录下包括一个同名的WebScraping包和一个scrapy.cfg配置文件;其中scrapy.cfg配置文件内容如下:
指定该scrapy项目的setting文件为WebScraping包下的settings.py文件
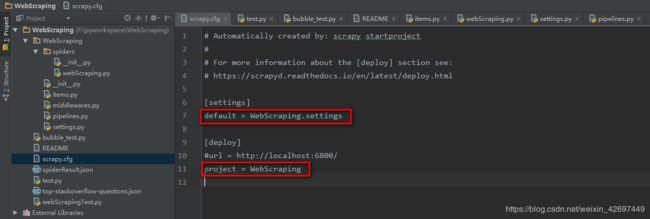
②scrapTest模块下又包含了items、middlewares、pipelines、settings模块以及spider包
(1) items模块中定义了items类,各items类必须继承scrapy.Item;通过scrapy.Field()定义各Item类中的类变量
import scrapy
class StockQuotationItem(scrapy.Item):
'''
'''
order=scrapy.Field()
symbol = scrapy.Field()
instrument_name = scrapy.Field()
price=scrapy.Field()
pchg = scrapy.Field()
chg = scrapy.Field()
speed_up = scrapy.Field()
turnover = scrapy.Field()
QR = scrapy.Field()
swing = scrapy.Field()
vol = scrapy.Field()
floating_shares = scrapy.Field()
floating__net_value=scrapy.Field()
PE = scrapy.Field()
(2) middlewares模块中定义了各中间件类,包括SpiderMiddleWares、DownloadMiddleWares等
(3) pipelines模块,用于处理spider中获取的items(将获取的items保存至文件或者数据库等):
Pipeline类必须实现process_item()方法
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class WebScrapingPipeline(object):
def __init__(self):
self.f= open('spiderResult.json','wb')
def process_item(self, item, spider):
result=json.dumps(dict(item), ensure_ascii=False)+', \n'
self.f.write(result.encode('utf-8'))
#将Item返回至引擎,告知该item已经处理完成,你可以给我下一个item
return item
def close_spider(self,spider):
self.f.close()
(4) settings模块中包含了项目相关配置信息,包括指定SPIDER_MODULES,指定ITEM_PIPELINES等等;如果要使用pipelines模块中定义的各pipelines类,必须在settings模块中指定,格式如下:
ITEM_PIPELINES = {
'WebScraping.pipelines.WebScrapingPipeline': 300,
}
下面显示了一个settings模块中包含的内容:默认设置了当前spider模块的位置以及新建spider模块的位置
# -*- coding: utf-8 -*-
# Scrapy settings for $project_name project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'WebScraping'
SPIDER_MODULES = ['WebScraping.spiders']
NEWSPIDER_MODULE = 'WebScraping.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = '$project_name (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# '$project_name.middlewares.${ProjectName}SpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# '$project_name.middlewares.${ProjectName}DownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'WebScraping.pipelines.WebScrapingPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
(5) spider包中包含各spider模块,spider模块中定义了各spider类:
其中spider类继承了scrapy.Spider类或者scrapy.CrawlSpider,通过parse方法对Response内容进行处理,获取Item字段需要的数据,并将需要跟进的URL提交给engine
在spider类中默认需要定义该spider的名称、start_urls、allowed_domains等内容,其中spider name 必须定义,后续运行spider时,需要指定spider名称
import scrapy
from ..items import StockQuotationItem
class WebScrapingSpider(scrapy.Spider):
name='WebScraping'
allowed_domains=['q.10jqka.com.cn']
start_urls=['http://q.10jqka.com.cn/']
def parse(self, response):
quotation_tb=response.xpath('//*[@id="maincont"]/table/tbody')
quotation_ls=quotation_tb.xpath('tr')
item=StockQuotationItem()
for quotation in quotation_ls:
result=quotation.xpath('td/text()').extract()
#item['order']=order
item['symbol']=result[0]
item['instrument_name']=result[1]
item['price']=result[2]
item['pchg']=result[3]
item['chg']=result[4]
item['speed_up']=result[5]
item['turnover']=result[6]
item['QR']=result[7]
item['swing'] = result[8]
item['vol'] = result[9]
item['floating_shares'] = result[10]
item['floating__net_value'] = result[11]
#item['PE'] = result[12]
yield item
2.运行爬虫项目:通过scrapy crawl [spider 名称] 指定运行某个spider
下面是 通过 scrapy crawl 命令运行 "WebScraping"的结果
F:\pyworkspace\WebScraping>scrapy crawl WebScraping
2019-02-15 14:59:03 [scrapy.utils.log] INFO: Scrapy 1.5.2 started (bot: WebScraping)
2019-02-15 14:59:03 [scrapy.utils.log] INFO: Versions: lxml 4.3.0.0, libxml2 2.9.7, cssselect 1.0.3, parsel 1.5.1, w3lib 1.20.0, Twisted 18.9.0, Python 3.7.2 (tags/v3.7.2:9a3ffc0492, Dec 23 2018, 22:20:52) [MSC v.1916 32 bit (Int
el)], pyOpenSSL 19.0.0 (OpenSSL 1.1.1a 20 Nov 2018), cryptography 2.5, Platform Windows-10-10.0.17763-SP0
2019-02-15 14:59:03 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'WebScraping', 'CONCURRENT_REQUESTS': 32, 'NEWSPIDER_MODULE': 'WebScraping.spiders', 'SPIDER_MODULES': ['WebScraping.spiders']}
2019-02-15 14:59:03 [scrapy.extensions.telnet] INFO: Telnet Password: 7c6e57a3e25c172e
2019-02-15 14:59:03 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2019-02-15 14:59:06 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2019-02-15 14:59:06 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2019-02-15 14:59:07 [scrapy.middleware] INFO: Enabled item pipelines:
['WebScraping.pipelines.WebScrapingPipeline']
2019-02-15 14:59:07 [scrapy.core.engine] INFO: Spider opened
2019-02-15 14:59:07 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2019-02-15 14:59:07 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2019-02-15 14:59:07 [scrapy.core.engine] DEBUG: Crawled (200) 至此,一个简单爬虫项目就搭建完成