python关于字典包括嵌套字典的文件读写
python
电影推荐(V3.0版本)
–每个用户有对电影打分,根据用户喜好来确定与当前用户最相似(多维欧几里得距离)的用户,然后再根据最相似用户的喜好为当前用户进行推荐
–采用字典嵌套字典来存放数据,格式为{用户1:{电影名称1:打分1,电影名称2:打分2,…},用户2:{…}}.
–3.0版本新增功能:
•将用户、不同用户看过的电影以及对电影的评分等原始数据存入文件。
•追加一部分新用户以及他们看过的电影及评分,并加到文件中。
•根据录入的用户及相关信息找出观影习惯最接近的用户,并给出推荐的电影
。
知识点 嵌套字典的生成,随机数的运用,字典存入文件,min\max的运用
我们直接上代码,易于理解。
from random import randrange
import json
#历史电影打分数据
data ={}
for i in range(10):
items={}
for j in range(randrange(3,10)):
items['film'+str(randrange(1,15))]=randrange(1,6)
data['user'+str(i)]=items
fo=open("filefile1.txt","w+")#存入文件中。。。
fo.write(json.dumps(data))
fo.write('\n')
fo.close()
#新用户
user={'film'+str(randrange(1,15)):randrange(1,6) for i in range(5)}
fo=open("filefile1.txt","a+")#添加新成员....
fo.write(json.dumps(user))
fo.close()
#最相似的用户及其对电影打分情况
#两个用户共同打分的电影最多
#并且所有电影打分差值平方和最小
similarUser,films=min(data.items(),
key=lambda item:(-len(item[1].keys()&user),
sum(((item[1].get(film)-user.get(film))**2
for film in user.keys()&item[1].keys()))))
print("原本的数据".center(50,'='))
for u, f in data.items():
print(u, f, sep=':')
print("新用户的数据".center(50,'='))
print(user)
print("最相似的用户,和他看过的电影".center(50,'='))
print(similarUser,films,sep=':')
print("推荐的电影".center(50,'='))
print(max(films.keys()-user.keys(),key=lambda film:films[film]))
几个步骤,
1.记得引用json库,笔者一开始就忘记引用了。
2.嵌套字典的生成,格式为{用户1:{电影名称1:打分1,电影名称2:打分2,…},用户 2:{…}}
这里可以用生产式的方法,一条式子就可以,但分开写能易于理解吧吧吧///
逐步式:
data ={}
for i in range(10):
items={}
for j in range(randrange(3,10)):
items['film'+str(randrange(1,15))]=randrange(1,6)
data['user'+str(i)]=items
一步生成式,防止粘贴缺漏,用截图吧
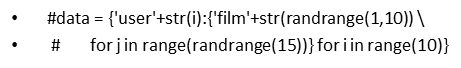
3.写入文档有以下两种
.write()和.writelines(),前者为字符串,后者为list,但没有直接将字典写入的,借用json.dumps()
fo=open("filefile1.txt","w+")#存入文件中。。。
fo.write(json.dumps(data))
fo.write('\n')
fo.close()
注意要写入文件,需要“w+”模式,
4.添加新成员
user={'film'+str(randrange(1,15)):randrange(1,6) for i in range(5)}
fo=open("filefile1.txt","a+")#添加新成员....
fo.write(json.dumps(user))
fo.close()
这里注意是“a+”模式,在文件后加入新信息,不影响旧的信息
还有这里可以思考如何加多个用户。。。。。。。。
4.比较看电影的相识度,根据多维欧几里得距离算,不懂的百度可得
similarUser,films=min(data.items(),
key=lambda item:(-len(item[1].keys()&user),
sum(((item[1].get(film)-user.get(film))**2
for film in user.keys()&item[1].keys()))))
5.最后呢,就是输出格式的控制问题
这个也是我最近才知道的
print("原本的数据".center(50,'='))
for u, f in data.items():
print(u, f, sep=':')
print("新用户的数据".center(50,'='))
print(user)
print("最相似的用户,和他看过的电影".center(50,'='))
print(similarUser,films,sep=':')
print("推荐的电影".center(50,'='))
print(max(films.keys()-user.keys(),key=lambda film:films[film]))
.center()的用法非常好用
原本数据的输出用这个非常方便,有的人用循环输出,感觉视觉体验感不好
下面直接看我的运行结果
- 运行截图 ,

2.文件的内容 直接截图上

能精准找到这道题的估计我们是同个老师,哈哈哈。。。。