最直白的编译原理-基础知识(清华-王书3版)
目录
- 欢迎进入乱码IT的精神世界,请多指教~
- 编译程序
- 编译的过程
- 编译程序和解释程序的区别
- 文法与语言
- 若对小主有用,求赞哟~
- <也欢迎收藏,一起学习交流>
欢迎进入乱码IT的精神世界,请多指教~
编译程序
Q:什么是编译程序?
A:功能上看,编译程序就是一个语言翻译程序。它把高级语言编写的源程序翻译成等价的低级语言程序。
如下图:
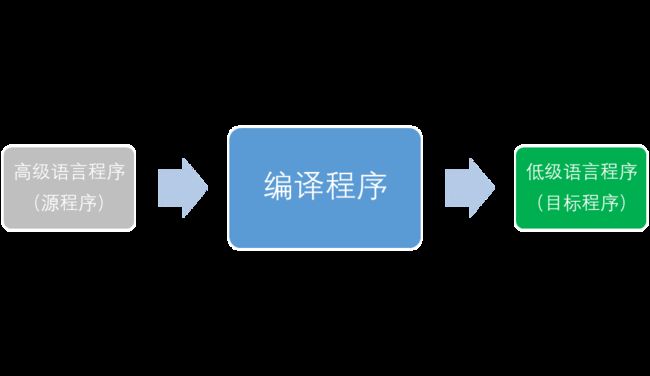
编译的过程
分阶段:
注:
-
源程序: 高级语言编写
-
词法分析: 从左到右,逐个字符读入源程序,对构成源程序的字符流进行扫描和分解,从而识别出一个个单词(源程序是以输入字符流形式被读入,词法分析就是对该紧凑的字符流进行解析,将字符流重整为一个个单词)
-
语法分析: 在词法分析基础上将单词序列分解成各类语法短语(相当于把词法分析得到的单词序列重构成语法短语,例如:将单词序列重构成‘语句’、‘表达式’等)
-
语义分析(语法制导来实现): 审查源程序有无语义错误,为代码生成阶段收集类型信息
-
中间代码生成: 将源程序变成一种内部表示形式,即中间代码,例:三元式、四元式等(为了编译的下一步操作方便)
-
代码优化: 对前一阶段产生的中间代码进行变换或改造(不应改变程序运行结果的前提下进行,程序的根本功能未变),使生成的目标代码更为高效(省时间和省空间)
-
目标代码生成: 将中间代码变换成特定机器上的绝对指令代码(机器可直接接受的)或可重定位的指令代码或汇编指令代码
-
目标程序: 等价(针对于源程序而言)的低级语言程序
另:
可重定位: 程序 在运行时,实际的物理起始位置是不确定,所以不能在编译时就把地址给写死,否则,如果实际运行时物理空间起始位置与编译时写死的起始地址不一致的话,程序就会出问题。之所以可以存在可重定位,是因为现实里程序执行时,存储分配环节有一个从逻辑地址空间到物理地址空间的映射过程,这个猫腻在,就有了重定位的操作空间了。重定位是由操作系统安排的,它是实现多道程序在内存中同时运行的基础。
语法制导翻译:由语法分析程序的分析过程来主导语义分析和翻译过程(就是在语法分析的过程里同时进行语义分析,比如在构造语法分析树结点的同时附加上语义规则,遍历到该结点同时进行语义计算)
编译过程还可以分为: 前端 和 后端
- 前端(依赖于源语言而与目标机无关):包括词法分析、语法分析、语义分析、中间代码生成、某些优化工作、相关出错处理工作、符号表管理工作
- 后端(依赖于目标机而一般与源语言无关):包括目标代码生成、相关出错处理工作、符号表操作
出错处理和符号表操作,在整个编译过程都有进行
编译程序和解释程序的区别
1.编译程序结果是生成目标代码,期间并没有执行源程序,而解释程序不生成目标代码,对源程序是边解释边运行,直接输出结果
2.
解释程序是具有可交互性的,在解释运行过程中可交互,而编译程序不具备
3.
编译程序与解释程序的存储组织也有很大不同
4.
程序的解释是非常慢的,而且空间开销也比较大
文法与语言
一种语言的完整定义包含两方面:语法 和 语义
语言,是符合该语言语法的 全部句子的集合(无穷性)
句子:仅由终结符构成,不可再推导
- 语法: 一组规则,定义了什么样结构才算是符合语言合法性的(比如:语法要求主谓宾结构,只有满足该主谓宾结构才算符合该语法对应语言,所以,‘我爱你’符合该语法对应语言,‘我你爱’不符合)
- 语义: 即含义
文法是以有穷集合刻画无穷集合的一个工具
(有穷的可以穷举法列举,无穷的可以利用其构成规则来描述,这就是一种思维跳跃)
字母表(非空有穷集合): 字母表中元素被称为符号(所以,字母表也被称为符号集)
符号串: 由字母表中符号组成的任何有穷序列
(空符号串(任意串包含空串):ε )
符号串的头尾 例:z = abc ,z的头:ε,a,ab,abc,固有头:ε,a,ab,z的尾:ε,c,bc,abc,z的固有尾:ε,c,bc(固有,是因为其前或者后,存在非空)
符号串的连接: 按顺序拼接在一起即可
符号串的方幂: 将自身连接n次得到(规定:方幂n为0时,结果为:ε,即,x0 = ε )
符号串的集合: 该集合内元素为符号串。
(笛卡尔积:假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积AB为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)})
∑*(闭包,∑ 为一个集合) :∑ 集合上的所有有穷串的集合
∑+(正闭包) :闭包基础上去掉空串ε
文法G被定义为四元组:(VN,VT,P,S)
(VN:非终结符集)
(VT:终结符集)< 助记:Terminal ,终端>
(P:产生式集)
(S:开始符或叫识别符)
(V = VN∪VT:V 称为文法的字母表)
VN非终结符,一般为大写字母或尖括号括起来,例:S、T等
VT终结符,一般为小写字母或不用尖括号括起来,例:a、b、c等
推导(上面加‘*’表示0步及以上推导;上面加‘+’表示1步及以上推导):
![]()
产生式: →
文法的类型(区别:对产生式施加不同的限制):
- 0型文法(短语文法):左部至少含一个非终结符,右部随意
- 1型文法(上下文有关文法):在0型的基础上,右部长度>=左部长度,S→ε 除外,例:S→A
- 2型文法(上下文无关文法):在1型文法的基础上,左部只由一个非终结符构成,例:S→任意
- 3型文法(正则文法):在2型文法的基础上,右部只能是只有一个终结符或一个终结符加一个非终结符。例:S→a或S→bC
语法树(推导树):如何构建?
根据推导过程构建,从根出发,最左推导则从左到右进行,递归地对顺序里的第一个可推导元素添加推导结果作为其子孙结点,直到不可在推。(标号为顺序)
如下图:

文法的二义: 文法的某一个句子推导对应了多棵语法树
文法等价: 两个文法的所有句子相同
最左推导: 右部从最左边开始推导(从左往右)。
最右推导(规范推导): 右部从最右边开始推导(从右往左)。
<其所得句型为右句型或规范句型>
根据语法树找到句柄、短语、直接短语(简单短语)
- 短语: 看语法树叶子结点,所有叶子结点+所有叶子结点的可能组合(注意,重复的合并掉)
- 直接短语: 短语里的所有非组合叶子节结点(无分叉直达叶子结点的那些叶子结点值)
- 句柄: 语法树中最左直接短语
如下图:
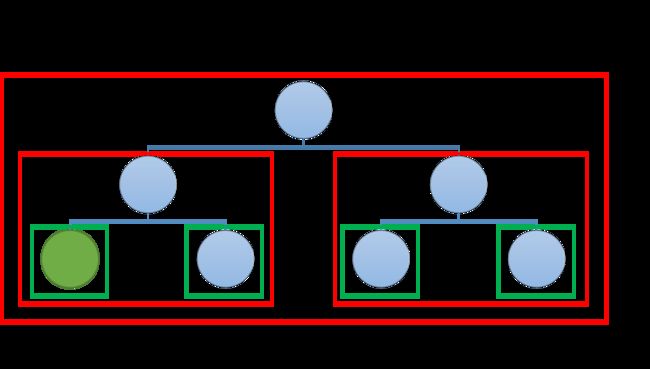
注:
- 不论颜色,每个框代表一个短语
- 绿色框代表直接短语
- 句柄为:绿圆+绿框那个结点(最左边直接短语)