语法1:LOAD DATA
LOAD DATA INFILE 'file_name' [REPLACE | IGNORE] INTO TABLE tbl_name [CHARACTER SET charset_name] [{FIELDS | COLUMNS} [TERMINATED BY 'string'] [[OPTIONALLY] ENCLOSED BY 'char'] [ESCAPED BY 'char'] ] [LINES [STARTING BY 'string'] [TERMINATED BY 'string'] ] [IGNORE number {LINES | ROWS}] [(col_name_or_user_var [, col_name_or_user_var] ...)] [SET col_name={expr | DEFAULT} [, col_name={expr | DEFAULT}] ...]
语法2:
SELECT ... INTO OUTFILE
备注:...可参考select语法
LOAD DATA与SELECT ... INTO OUTFILE是一个互补语法。SELECT ... INTO OUTFILE从表中读取数据然后存入文件中,而LOAD DATA是从文件中读取数据放入表中。
一:示例准备
1.1:创建表
CREATE TABLE blog.`abc` ( `id` int NOT NULL, `a` varchar(45) DEFAULT NULL, `b` varchar(45) DEFAULT NULL, `c` varchar(45) DEFAULT NULL, PRIMARY KEY (`id`) )
1.2: 插入表数据
INSERT INTO `abc` VALUES (1,'a','b','c'),(2,'a1','b1','c1'),(3,'a2','b2','c2');
二:从表中导出数据到文件
2.1示例1:默认格式导出数据
步骤一:登录服务器 mysql -u root -p
步骤二:执行导出语句如下
SELECT id,a,b,c from abc INTO OUTFILE '/var/lib/mysql-files/abc.txt';
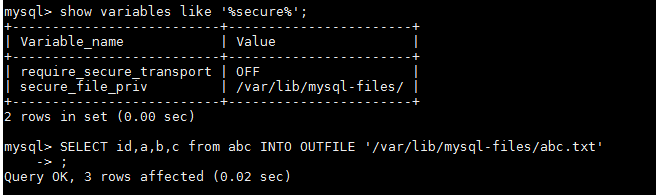
备注:注意我导出的路径,和上图中查询出的变量名和值的关系。waring:当指定其他路径会报错(老弟请自己体会其中的含义吧!!)
步骤3:查看导出数据
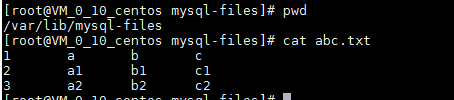
请注意观察数据的导出样式
2.1示例2:指定导出样式
SELECT id,a,b,c from abc INTO OUTFILE '/var/lib/mysql-files/abc2.txt' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"';
备注:即与示例1区别在于每列数据通过逗号(,)分割 ,每个数据被引号引注
查看导出样式

三:从文件导入数据到表中朱
3.1示例3:分析文件格式,确定导入语句
分析点包括,1.数据是否被符号包囊,2.数据与数据之间的分割,3。行与行之间的分割
根据前面的导出的文件abc.txt(默认导出样式),即使用默认的导入语句
load data infile '/var/lib/mysql-files/abc.txt' INTO TABLE blog.abc;
根据前面的导出的文件abc2.txt(指定一些样式),即使用相应的导出语句
load data infile '/var/lib/mysql-files/abc2.txt' INTO TABLE blog.abc FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"';

备注:当我们没有指定列或行的限制时,其实程序是为我们默认指定了一些规则的(该规则也适用于导出),其规则如下
FIELDS TERMINATED BY '\t' ENCLOSED BY '' ESCAPED BY '\\' LINES TERMINATED BY '\n' STARTING BY ''
即列默认1.通过空格分割2.数据没有被任何符号包括3.忽视\\
行默认1.一行为一条数据2.行开头开始读取
四:对导入的思考
4.1 重复的数据(即id重复如何操作?“终止”:“跳过”)
4.2 列的顺序(根定的文件列与表的列不一致?)
备注:除以上考点外,我们还可以思考一下这种导入是否支持分区表,这种导入的安全性,并发等等