python入门爬虫 60行代码抓取amazon中国站
这次用requests+pyquery教大家写amazon.cn爬虫!欢迎各位跟我一起交流,学习。
- 废话不说,直接上源码,(兄弟,你又飘了!)
import requests
from pyquery import PyQuery as pq
import time
import pymysql
import datetime
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8`',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control':'max-age=0',
'Cookie':'x-wl-uid=1C5tB2vN8c7lavnzfYDgHUImOM4TnKW4RDPJRHqltEo/CzfweQDRpdn8vABF8x1AJGiV5fs7nxxs=; session-id=458-1818727-1656342; ubid-acbcn=460-9298287-9372958; session-token="qLgiMsjH5EkTiN1gyNgsmUtrW2cKLf2Y9N6fpJoYpV6d1nqVt6vvuukTz02ezeMaWJfwZGeXxoPVwGjydlOwEX1ENh0A1ZebwcEN9T69+WYA/1cV4OHxfvOPrxjIVFhMgaZqLjkHt4KZ+sGOP4gT7bAt14UlSx9tq1pyNX/8JDmQ8ouZKTL0KYAqzVA+tLgHJqlJYLNt+ovqT7ad6WamIA=="; session-id-time=2082729601l; csm-hit=tb:4DGRV0CH4S37H6HK0TQ5+s-5882EJ35HSPBDQRTWVYS|1547819207778&adb:adblk_no&t:1547818974223',
'Connection':'keep-alive',
'Host':'www.amazon.cn',
'Referer':'https://www.amazon.cn/',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
def Get_food_url(page):
for x in range(21):
page = page + 1
if page <=20:
time.sleep(5)
url = 'https://www.amazon.cn/s/ref=sr_pg_'+str(page)+'?rh=i%3Aaps%2Ck%3A%E9%9B%B6%E9%A3%9F&page='+str(page)+'&keywords=%E9%9B%B6%E9%A3%9F&ie=UTF8'
response = requests.get(url,headers=headers)
print('....正在請求網頁....')
time.sleep(2)
doc = pq(response.text)
print('....正在解析網頁....')
time.sleep(2)
data_food = doc('.s-item-container').items()
print('正在抓取第:'+str(page)+'頁信息')
time.sleep(1)
for i in data_food:
print('-'*80)
title = i.find('.s-access-title').text()
food_urls = i.find('.a-link-normal').attr('href')
time_now = str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M'))
print('名称:'+title)
print('零食鏈接:'+food_urls)
print('當前時間:'+time_now)
time.sleep(1)
#提前導入pymysql,然後開啓數據庫把抓取的數據,寫入數據庫保存
db =pymysql.connect(host='localhost',user='root',password='root',port=3306,db='amazon')
cursor = db.cursor()
sql = "insert into food_url(title,url,time) values(%s,%s,%s)"
params = (title,food_urls,time_now)
cursor.execute(sql,params)
db.commit()
db.close()
print('....數據保存完成-正在跳轉到下一頁....')
Get_food_url(0)
我們首先捋一下思路,請求頭別忘記寫了,不然請求可能不成功。
1. 我們抓取的不是單頁的,so!我們分析一下每一頁的url
1.https://www.amazon.cn/s/ref=nb_sb_noss_1?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&url=search-alias%3Daps&field-keywords=%E9%9B%B6%E9%A3%9F
2.https://www.amazon.cn/s/ref=sr_pg_1?rh=i%3Aaps%2Ck%3A%E9%9B%B6%E9%A3%9F&page=1&keywords=%E9%9B%B6%E9%A3%9F&ie=UTF8&qid=1547819011
3.https://www.amazon.cn/s/ref=sr_pg_2?rh=i%3Aaps%2Ck%3A%E9%9B%B6%E9%A3%9F&page=2&keywords=%E9%9B%B6%E9%A3%9F&ie=UTF8&qid=1547818975
4.https://www.amazon.cn/s/ref=sr_pg_3?rh=i%3Aaps%2Ck%3A%E9%9B%B6%E9%A3%9F&page=3&keywords=%E9%9B%B6%E9%A3%9F&ie=UTF8&qid=1547819011
對比一下可以發現每一條url都是有規律的,我們來構造url的時候後綴的qid可以忽略,也就是不帶qid這個參數,同樣也能請求到的,我直接上構造后的代碼
url = 'https://www.amazon.cn/s/ref=sr_pg_'+str(page)+'?rh=i%3Aaps%2Ck%3A%E9%9B%B6%E9%A3%9F&page='+str(page)+'&keywords=%E9%9B%B6%E9%A3%9F&ie=UTF8'
url寫的沒那麽人性化,見諒!這裏我直接傳入“page”寫個for循環就可以了
我們這裏抓取零食為例子,顯示的20頁

2. url分析完畢,現在我們來寫請求頭以及網頁分析!
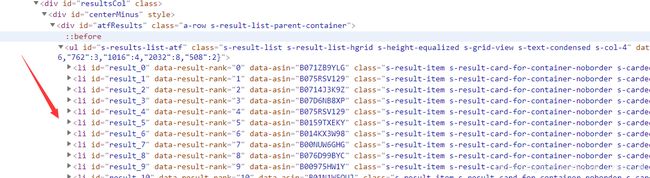
發現商品的信息全在這個li標簽下面,并且都是在li標簽裏面同一個class
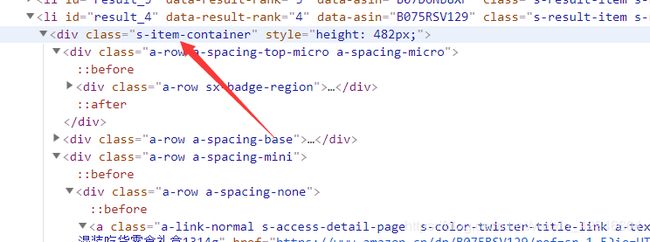
所以這裏我們直接便利這個class=“s-item-container”就行了,上圖

這次我們只抓取商品的名稱,url,後續我會繼續放出抓取每個商品的詳情。這次我們還是用pyquery來解析獲取到的response
我直接上圖了

我們只要抓取title以及url
上代碼
title = i.find('.s-access-title').text()
food_urls = i.find('.a-link-normal').attr('href')
time_now = str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M'))
我這裏因爲是存入數據庫的 所以我還添加了一個插入的時間,
獲取屬性的使用到“attr()”方法,然後我當時建表的時間,把時間的字段類型改成了str類型,所以我這裏用str()將時間轉為字符串
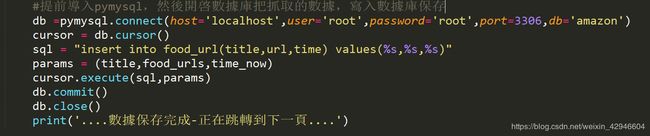
3. 分析完成,接下來我們要把提取的數據存入數據庫中,因爲比較簡單我就不贅述了,直接上圖
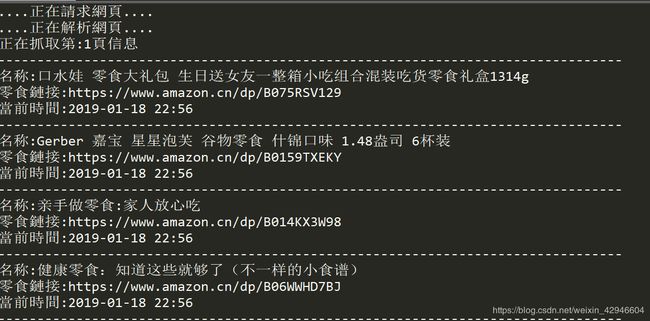
最後就成功提取信息啦------------呐!
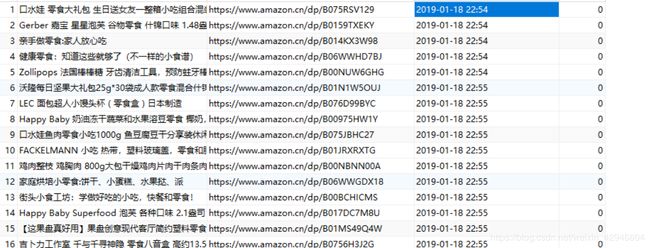
最後説一下,建立status這個字段,會用到下一篇的爬蟲上,例如讀取數據庫時,讀取一條就把狀態改成1,這樣就有個限制。
當然還有更多的方法,個人喜好!