python 爬虫1
1 首先我们需要一个模块,Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用(requests 的底层实现其实就是 urllib3)继承了urllib的所有特性,支持 HTTP 连接保持和连接池,支持使用 cookie 保持会话,支持上传文件,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。

如图,在python 中导入模块(如果没有安装模块,可以 pip install requests 安装)
2 基本 GET 请求(headers 参数 和 parmas 参数)
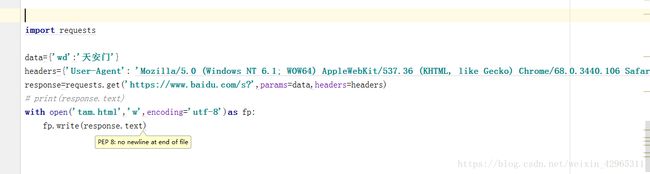
如图,headers参数是模仿一个浏览器,parmas参数结接收一个字典或者字符串的查询参数,字典类型自动转换为url编码。
print(respons.text) #查看响应内容,respons.text 返回的是Unicode格式的数据。
3 基本的 POST 请求(data 参数)
**#导入模块**
import requests
import time
import hashlib
name=input('请输入需要翻译的单词:')
**#地址**
url='http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
**#请求头**
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
# 'Accept-Encoding':'gzip, deflate', #压缩格式(不需要)
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Content-Length':str(len(name)+196), #内容长度(你输入的单词长度加上196,找出的规律)
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'[email protected]; JSESSIONID=aaa6CH4jdaGf-8ePqsNww; OUTFOX_SEARCH_USER_ID_NCOO=2080675206.107373; ___rl__test__cookies=1536110481944',
'Host':'fanyi.youdao.com',
'Origin':'http://fanyi.youdao.com',
'Referer':'http://fanyi.youdao.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'X-Requested-With':'XMLHttpRequest',
}
**# 时间戳:**
salt=int(time.time()*1000)
**##md5加密**
def getMd5(value):
md5=hashlib.md5()
md5.update(bytes(value,encoding='utf-8')) #bytes 值是二进制的
return md5.hexdigest() ##32位的加密串
**#加密之前的字符串**
sign_str="fanyideskweb" + name + str(salt) + "6x(ZHw]mwzX#u0V7@yfwK"
sign=getMd5(sign_str)
**#表单数据**
data={
'i':name,
'from':'AUTO',
'to':'AUTO',
'smartresult':'dict',
'client':'fanyideskweb',
'salt':salt, #时间戳
'sign':sign, # md5加密字符串
'doctype':'json',
'version':'2.1',
'keyfrom':'fanyi.web',
'action':'FY_BY_REALTIME',
'typoResult':'false',
}
response=requests.post(url=url,data=data,headers=headers)
print(response.text)4 爬取图片
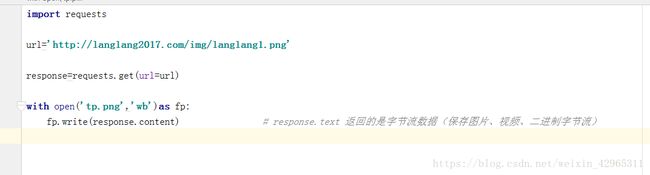
如图,是爬取一张图片的代码,先导入模块,然后将地址输入(先将网站地址输入,然后将图片地址输入,如:/img/langlan1.png 是图片地址),保存。
print(respons.content) #查看响应内容,respons.content返回的是字节流数据。
爬取多张图片,需要正则来爬取
**#导入模块**
import requests
import re
**#提取页面**
response=requests.get(url='http://langlang2017.com/')
**#提取数据(正则表达式)**
pattern=re.compile(r'src="(img/banner\d.png)"')
result=pattern.findall(response.text)
print(result)
base_url='http://langlang2017.com/'
a=1
for i in result:
full_url = base_url + i
response=requests.get(full_url)
file_name='banner%d.png'%a
with open(file_name,'wb')as fp:
fp.write(response.content)
a+=1如代码所示,先将页面爬取出来,之后用正则来匹配页面中图片的地址路径,全部匹配,之后返回列表为多个图片的地址路径,然后遍历后与页面地址连接,用这个新的地址继续请求,最后保存即可把页面中的匹配的图片全部抓取出来。
5 处理 HTTP 请求 SSL 证书验证
Requests 也可以为 HTTPS 请求验证 SSL 证书:
要想检查某个主机的SSL证书,可以使用 verify 参数。
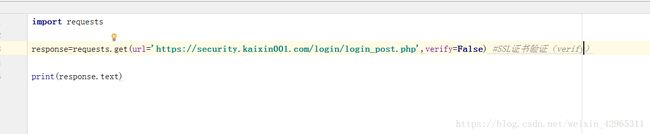
如图,verify=Ture 表示需要验证,verify=False 表示不需要验证。
未完待续