scrapy框架之爬取豆瓣电影
scrapy框架之爬取豆瓣电影
思路:
1.建立项目
scrapy startproject douban
创建爬虫者:scrapy genspider douban movie.douban.com
2.明确目标,主要是处理items.py
3.编写爬虫处理,数据爬取和解析
4.数据存储,可以存储格式一般是json/csv/mongodb/redis/mysql,本练习主要是采用mongodb数据存储
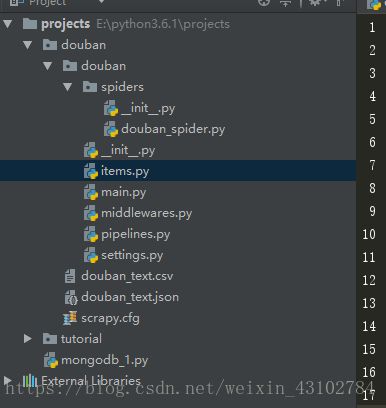
整个部署的目录结构
1. items.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
serial_number = scrapy.Field()
movie_name = scrapy.Field()
introduce = scrapy.Field()
star =scrapy.Field()
evaluate = scrapy.Field()
describe = scrapy.Field()
2.douban_spider.py
-- coding: utf-8 --
import scrapy
from douban.items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = ‘douban_spider’
allowed_domains = [‘movie.douban.com’]
#入口url
start_urls = [‘https://movie.douban.com/top250‘]
def parse(self, response):
movice_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
for i_item in movice_list:
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em//text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s = "".join(i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//div[@class='info']//div[@class='star']//span[2]/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='info']//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//div[@class='info']//p[@class='quote']//span/text()").extract_first()
#extract()方法是提取出节点,extract_first()提取该节点的第一个元素
#需要将数据yield到Pipelines里面去
yield douban_item
#解析下一页的规则,取得后页的XPATTH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
3.main.py 作为python 调试
from scrapy import cmdline
cmdline.execute(‘scrapy crawl douban_spider’.split())
4.pipelines.py
清理HTML数据
验证爬取数据,检验爬取字段
查看并丢弃重复内容
将爬取结果保存到数据库
import pymongo
from douban.settings import mongo_host,mongo_port,mongo_db_name,mongo_db_collection
class DoubanPipeline(object):
def init(self):
host = mongo_host
port = mongo_port
dbname = mongo_db_name
sheetname = mongo_db_collection
client =pymongo.MongoClient(host=host,port=port)
mydb = client[dbname]
self.port = mydb[sheetname]
def process_item(self, item, spider):
data = dict(item)
self.port.insert(data)
return item
5.settings.py
-- coding: utf-8 --
BOT_NAME = ‘douban’
SPIDER_MODULES = [‘douban.spiders’]
NEWSPIDER_MODULE = ‘douban.spiders’
USER_AGENT = ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36’
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
‘douban.pipelines.DoubanPipeline’: 300,
}
mongo_host = ‘127.0.0.1’
mongo_port = 27017
mongo_db_name = ‘douban’
mongo_db_collection = ‘douban_movie’
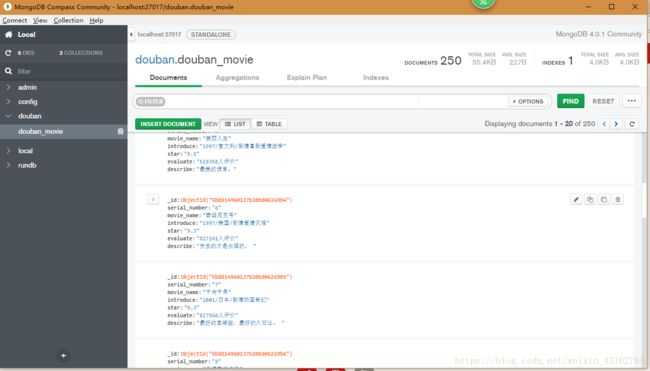
运行结果: