嵩天老师-Python语言程序设计-Python123配套练习测验题目汇总整理
测验1:Python基本语法元素
知识点概要:
- 普遍认为Python语言诞生于1991年
- Python语言中的缩进在程序中长度统一且强制使用,只要统一即可,不一定是4个空格(尽管这是惯例)
- IPO模型指:Input Process Output
- 字符串的正向递增和反向递减序号体系:正向是从左到右,0到n-1,反向是从右到左,-1到-n,举例
str = "csdn"
#str[0]就表示字符串c, str[-1]表示"n"
- Python的合法命名规则:命名包含字母,数字,下划线,但是首字符不能是数字
- Python中获得用户输入的方式为:input()
- Python中的保留字:type不是,是内置函数,def elif import 都是保留字
- Python的数据类型有整数、列表、字符串等,但是不包括实数,实数是数学概念,在Python中对应着浮点数
- 保留字if-elif-else用于表示分支结构,in用来进行成员判断
- print()格式化输出,控制浮点数的小数点后两位输出应为:print("{:.2f}".format(XX)) :.2f哪一个都不能少
编程测试:
- Hello World 的条件输出:获得用户输入的一个整数,参考该整数值,打印输出"Hello World",要求:
如果输入值是0,直接输出"Hello World"
如果输入值大于0,以两个字符一行方式输出"Hello World"(空格也是字符)
如果输入值小于0,以垂直方式输出"Hello World"
# eval()函数可以将默认输入的字符串去掉双引号并进行表达式运算,如输入500+20,默认
#得到的输入为一个字符串“500+20”,但是使用eval()函数我们得到的是一个整型数字:520
Number = eval(input())
if Number == 0:
print("Hello World")
elif Number > 0:
print("He\nll\no \nWo\nrl\nd")
else:
for c in "Hello World":
print(c)
- 数值运算:获得用户输入的一个字符串,格式如下:M OP N ,其中,M和N是任何数字,OP代表一种操作,表示为如下四种:+, -, *, /(加减乘除)根据OP,输出M OP N的运算结果,统一保存小数点后2位。
注意:M和OP、OP和N之间可以存在多个空格,不考虑输入错误情况。
print("{:.2f}".format(eval(input())))
测验2:Python基本图形绘制
知识点概要:
- 正确引用turtle库的方式:
import turtle
#t是别名,可以更换其他名称
import turtle as t
from turtle import setup
from turtle import *
import setup from turtle是不正确的
- turtle库是一个直观有趣的图形绘制函数库,最早成功应用于LOGO编程语言,turtle绘图体系以水平右侧为绝对方位的0度,turtle坐标系的原点****默认在屏幕正中间
turtle.circle(-90,90)表示绘制一个半径为90像素的弧形,圆心在小海龟当前行进的右侧
# circle(x,y)表示以x长度为半径,y为角度,
#当前方向左侧x处为圆心画圆,其中x,y都可以是负数,相应取反
#当前方向是水平向右的,对应直角坐标系中的x轴正方向
#x为正,则圆心在y轴正方向上,y为正,逆时针画圆,圆弧角度为y
#x为负则相反,圆心在y轴负方向上,y为正,顺时针画圆,圆弧角度为y
- turtle.seth(to_angle)函数的作用是设置小海龟当前行进方向为to_angle,to_angle是角度的整数值
- turtle.fd(distance)函数的作用是向小海龟当前行进方向前进distance距离
- turtle.pensize(size)函数的作用是改变画笔的宽度为size像素
- turtle**.circle**()函数不能绘制椭圆形
- turtle.circle(x,y)函数绘制半圆,第二个参数y是180的奇数倍
- turtle.penup()的别名有turtle.pu(),turtle.up()
- turtle.colormode()的作用是设置画笔RGB颜色的表示模式
- turtle.width()和turtle.pensize()都可以用来设置画笔尺寸
- turtle.pendown()只是放下画笔,并不绘制任何内容
- 改变turtle画笔的运行方向有left()、right()和seth()函数,bk()只能后退,但是不改变方向
- turtle.done()用来停止画笔绘制,但绘图窗体不关闭,建议在每个turtle绘图最后增加turtle.done()
- 循环相关保留字是:for…in和while,def用于定义函数
编程测试:
- turtle八边形绘制:使用turtle库,绘制一个八边形
import turtle as t
t.pensize(2)
for i in range(8):
t.fd(100)
t.left(45)
- turtle八角图形绘制:使用turtle库,绘制一个八角图形
import turtle as t
t.pensize(2)
for i in range(8):
t.fd(150)
t.left(135)
测验3:基本数据类型
知识点概要:
- pow(x,0.5)能够计算x的平方根,计算负数的平方根将产生复数
- 字符串.strip()方法的功能是去掉字符串两侧指定的字符
- 字符串.split()方法的功能是按照指定字符分隔字符串为数组
- 字符串.repalce()方法的功能是替换字符串中特定字符
- +操作符用来连接两个字符串序列
- 字符串是一个连续的字符序列,使用\n可以实现打印字符信息的换行
val = pow(2,1000)
#返回val结果的长度值要使用 len(str(val)),因为整型没有len()方法,要通过str()函数
#将数字类型转换为字符串- 正确引用time库的方式如下:
import time
from time import strftime
from time import *
- Python语言的整数类型表示:十进制(一般表示)二进制(0b或0B开头)八进制(0o或0O开头)十六进制(0x或0X开头)
- %运算符的意思是取余数
- 字符串切片操作:s[N:M],从N到M,但是不包括M
name="Python语言程序设计课程"
print(name[0],name[2:-2],name[-1])
#输出结果为:P thon语言程序设计 程
print("{0:3}".format('PYTHON'))代码执行的结果是PYTHON,{0:3}表示输出的宽度是3,但是如果字符串长度超过3就以字符串长度显示
编程测试:
- 平方根格式化:获得用户输入的一个整数a,计算a的平方根,保留小数点后3位,并打印输出。输出结果采用宽度30个字符、右对齐输出、多余字符采用加号(+)填充,如果结果超过30个字符,则以结果宽度为准
a = eval(input())
print("{:+>30.3f}".format(a**0.5))
# +是填充字符 >是右对齐 30是宽度 .3f是保留小数点后3位
#若平凡根后是一个复数,复数的实部和虚部都是浮点数,.3f可以将实部和虚部分别取三位小数
- 字符串分段组合:获得输入的一个字符串s,以字符减号(-)分割s,将其中首尾两段用加号(+)组合后输出
InputStr = input()
strs = InputStr.split('-')
print(strs[0]+'+'+strs[-1])
print("{}+{}".format(strs[0], strs[-1]))
#s.split(k)以k为标记分割s,产生一个列表
#通过该题目,掌握split()方法的使用,注意:k可以是单字符,也可以是字符串
测验4:程序的控制结构
知识点概要:
- for…in…中in的后面需要的是一个迭代类型(组合类型),{1;2;3;4;5}不是Python的有效数据类型
- range(x,y)
for i in range(0,2):
print(i)
#输出结果为:0 1
- 程序的三种基本结构:顺序结构,循环结构和分支结构
- 循环是程序根据条件判断结果向后反复执行的一种运行方式,是一种程序的基本控制结构,条件循环和遍历循环结构都是基本的循环结构,死循环能够用于测试性能,形式上的死循环可以用break来退出,例如
x = 10
while True:
x = x -1
if x == 1:
break
p = -p #表示给p赋值为它的负数,Python中的=是赋值符号- 缩进表达层次关系,同时用来判断当前Python语句在分支结构中
- continue结束当次循环,但是不跳出循环
- random库中用于生产随机小数的函数是random(),而randint()/getrandbits()/randrange()都产生随机整数
- 程序错误是一个大的概念,不仅指代码运行错误,更代表功能逻辑错误。使用异常处理try-excepy,可以对程序的异常进行捕捉和处理,程序运行可能不会出错,但逻辑上可能会出错
编程测试:
- 四位玫瑰数:四位玫瑰数是4位数的自幂数。自幂数是指一个 n 位数,它的每个位上的数字的 n 次幂之和等于它本身
例如:当n为3时,有1^3 + 5^3 + 3^3 = 153,153即是n为3时的一个自幂数,3位数的自幂数被称为水仙花数
请输出所有4位数的四位玫瑰数,按照从小到大顺序,每个数字一行
#个人思路:求四位数的各个位数abcd
for i in range(1000,10000):
a = i%10
b = (i//10)%10
c = (i//100)%10
d = (i//1000)%10
if a**4 + b**4 + c**4 + d**4 == i:
print(i)
#参考答案:字符串+eval()
s = ""
for i in range(1000, 10000):
t = str(i)
if pow(eval(t[0]),4) + pow(eval(t[1]),4) + pow(eval(t[2]),4) + pow(eval(t[3]),4) == i :
print(i)
- 100以内素数之和:求100以内所有素数之和并输出
素数指从大于1,且仅能被1和自己整除的整数,提示:可以逐一判断100以内每个数是否为素数,然后求和
sum = 0
for i in range(2,100):
isFlag = 1 #判断是否为素数
for j in range(2,i): #遍历2-i-1,看是否能被i整除
if i%j == 0: #被整除说明不是素数
isFlag = 0
break
if isFlag == 1:
sum += i
print(sum)
#参考答案:将判断是否为素数封装为一个函数,倾向于这种解题思路
def is_prime(n):
for i in range(2,n):
if n%i == 0:
return False
return True
sum = 0
for i in range(2,100):
if is_prime(i):
sum += i
print(sum)
测验5:函数和代码复用
知识点概要:
- 函数作用:增强代码可读性、降低编程复杂度、复用代码,函数不能直接提高代码的执行速度
- 全局变量与局部变量:函数的参数一般为局部变量,函数内使用
global s表示变量s为全局变量 - 函数在调用前必须已经存在函数定义,否则无法执行,Python内置函数直接使用,不需要引用任何模块
- 模块内高耦合,模块间低耦合:高耦合的特点是复用较为困难,模块间关系应尽可能简单,模块之间耦合度低,尽可能合理划分功能块,功能块内部耦合度高
- 递归不会提高程序的执行效率,任何递归程序都可以通过堆栈或队列变为非递归程序
- 函数是一段具有特定功能的、可重用的语句组,可以看做是一段具有名字的程序,通过函数名来调用,同时不需要知道函数的内部实现原理,只需要知道调用方法(接口)即可
def func(*a,b):是错误的函数定义,*a表示可变参数,可变参数只能放在函数参数的最后,即def func(a,*b):- 函数可以包含0个或多个return语句
- 每个递归函数至少存在一个基例,但可能存在多个基例,基例表示不再进行递归,同时决定了递归的深度
编程测试:
- 随机密码生成:以整数17为随机数种子,获取用户输入整数N为长度,产生3个长度为N位的密码,密码的每位是一个数字。每个密码单独一行输出,产生密码采用random.randint()函数
import random
def genpwd(length):
a = 10**(length-1)
b = 10**length - 1
return "{}".format(random.randint(a, b))
length = eval(input())
random.seed(17)
for i in range(3):
print(genpwd(length))
#思路类似,同样过了
def genpwd(length):
high = 10**length
low = 10**(length-1)
return random.randrange(low,high)
- 连续质数计算:获得用户输入数字N,计算并输出从N开始的5个质数,单行输出,质数间用逗号,分割。
注意:需要考虑用户输入的数字N可能是浮点数,应对输入取整数;最后一个输出后不用逗号
def prime(m): #判断是否为质数
for i in range(2,m):
if m%i == 0:
return False
return True
n = eval(input())
if n != int(n): #考虑输入为浮点数的情况
n = int(n) + 1
else:
n = int(n)
times = 0 #统计质数的次数
res = [] #存放输出结果
while times < 5:
if prime(n):
res.append(n)
times += 1
n += 1
for i in res[:len(res)-1]:
print(i,end=",")
print(res[-1]) #最后一个不输出逗号
#参考答案
def prime(m):
for i in range(2,m):
if m % i == 0:
return False
return True
#需要对输入小数情况进行判断,获取超过该输入的最小整数(这里没用floor()函数)
n = eval(input())
n_ = int(n)
n_ = n_+1 if n_ < n else n_
count = 5
#对输出格式进行判断,最后一个输出后不增加逗号(这里没用.join()方法)
while count > 0:
if prime(n_):
if count > 1:
print(n_, end=",")
else:
print(n_, end="")
count -= 1
n_ += 1
测验6:组合数据类型
知识点概要:
- 列表ls,
ls.append(x)表示只能向列表最后增加一个元素,如果x是一个列表,则该列表作为一个元素增加到ls中 - 集合“交并差补”四种运算分别对应的运算符是:
& | - ^ - 字典d,
d.values()返回的是dict_values类型,包括字典中的所有值,通常与for…in组合使用 - Python的元组类型:元组采用逗号和圆括号(可选)来表示,一旦创建就不能修改,一个元组可以作为另一个元祖的元素,可用多级索引获取信息,序列类型(元组、列表)中的元素都可以是不同类型
- 创建字典时,如果相同键对应不同值,字典采用最后一个"键值对"
d= {'a': 1, 'b': 2, 'b': '3'}
print(d['b'])
#输出结果:3
- 集合与字典类型最外侧都用{}表示,不同在于集合类型元素是普通元素,字典类型元素是键值对。字典在程序设计中非常常用,因此直接采用{}默认生成一个空字典
- 对于字典d:
x in d表示判断x是否是字典d中的键,键是值的序号,也是字典中值的索引方式 - Python序列类型有:列表类型、元组类型、字符串类型(Python内置数据类型中没有数组类型)
- 组合数据类型能够将多个相同类型或不同类型的数据组织起来,通过单一的表示使数据操作更有序、更容易
- 组合数据类型可以分为3类:序列类型、集合类型和映射类型;
- Python的字符串、元组和列表类型都属于序列类型,序列类型总体上可以看成一维向量,如果其元素都是序列,则可被当作二维向量
- 对于序列s:
s.index(x)返回序列s中元素x第一次出现的序号,并不返回全部序号
编程测试:
- 数字不同数之和:获得用户输入的一个整数N,输出N中所出现不同数字的和
例如:用户输入 123123123,其中所出现的不同数字为:1、2、3,这几个数字和为6
#参考答案:字符串可以通过list()直接变成列表,或通过set()直接变成集合
n = input()
ss = set(n)
s = 0
for i in ss:
s += eval(i)
#s += int(i) #同样可以
print(s)
- 人名最多数统计:给出了一个字符串,其中包含了含有重复的人名,请直接输出出现最多的人名
#先使用字典建立"姓名与出现次数"的关系,然后找出现次数最多数对应的姓名
s = '''双儿 洪七公 赵敏 赵敏 逍遥子 鳌拜 殷天正 金轮法王 乔峰 杨过 洪七公 郭靖
杨逍 鳌拜 殷天正 段誉 杨逍 慕容复 阿紫 慕容复 郭芙 乔峰 令狐冲 郭芙
金轮法王 小龙女 杨过 慕容复 梅超风 李莫愁 洪七公 张无忌 梅超风 杨逍
鳌拜 岳不群 黄药师 黄蓉 段誉 金轮法王 忽必烈 忽必烈 张三丰 乔峰 乔峰
阿紫 乔峰 金轮法王 袁冠南 张无忌 郭襄 黄蓉 李莫愁 赵敏 赵敏 郭芙 张三丰
乔峰 赵敏 梅超风 双儿 鳌拜 陈家洛 袁冠南 郭芙 郭芙 杨逍 赵敏 金轮法王
忽必烈 慕容复 张三丰 赵敏 杨逍 令狐冲 黄药师 袁冠南 杨逍 完颜洪烈 殷天正
李莫愁 阿紫 逍遥子 乔峰 逍遥子 完颜洪烈 郭芙 杨逍 张无忌 杨过 慕容复
逍遥子 虚竹 双儿 乔峰 郭芙 黄蓉 李莫愁 陈家洛 杨过 忽必烈 鳌拜 王语嫣
洪七公 韦小宝 阿朱 梅超风 段誉 岳灵珊 完颜洪烈 乔峰 段誉 杨过 杨过 慕容复
黄蓉 杨过 阿紫 杨逍 张三丰 张三丰 赵敏 张三丰 杨逍 黄蓉 金轮法王 郭襄
张三丰 令狐冲 赵敏 郭芙 韦小宝 黄药师 阿紫 韦小宝 金轮法王 杨逍 令狐冲 阿紫
洪七公 袁冠南 双儿 郭靖 鳌拜 谢逊 阿紫 郭襄 梅超风 张无忌 段誉 忽必烈
完颜洪烈 双儿 逍遥子 谢逊 完颜洪烈 殷天正 金轮法王 张三丰 双儿 郭襄 阿朱
郭襄 双儿 李莫愁 郭襄 忽必烈 金轮法王 张无忌 鳌拜 忽必烈 郭襄 令狐冲
谢逊 梅超风 殷天正 段誉 袁冠南 张三丰 王语嫣 阿紫 谢逊 杨过 郭靖 黄蓉
双儿 灭绝师太 段誉 张无忌 陈家洛 黄蓉 鳌拜 黄药师 逍遥子 忽必烈 赵敏
逍遥子 完颜洪烈 金轮法王 双儿 鳌拜 洪七公 郭芙 郭襄 赵敏'''
names = s.split()
d = {}
for name in names:
d[name] = d.get(name, 0) + 1
Maxkey = ""
MaxValue = 0
for k in d:
if d[k] > MaxValue:
Maxkey = k
MaxValue = d[k]
print(Maxkey)
#参考答案
ls = s.split()
d = {}
for i in ls:
d[i] = d.get(i, 0) + 1
max_name, max_cnt = "", 0
for k in d:
if d[k] > max_cnt:
max_name, max_cnt = k, d[k]
print(max_name)
测验7:文件和数据格式化
知识点概要:
- 数据组织的纬度:一维数据采用线性方式组织,对应于数学中的数组和集合等概念;二维数据采用表格方式组织,对应于数学中的矩阵;高维数据由键值对类型的数据构成,采用对象方式组织,字典就用来表示高维数据,一般不用来表示一二纬数据
- Python对文件操作采用的统一步骤是:打开-操作-关闭(其中关闭可以省略)
- CSV文件格式是一种通用的、相对简单的文件格式,应用于程序之间转移表格数据,CSV文件的每一行是一维数据,可以使用Python中的列表类型表示,整个CSV文件是一个二维数据,一般来说,CSV文件都是文本文件,由相同的编码字符组成
- 二维列表切片
ls = [[1,2,3],[4,5,6],[7,8,9]]获取其中的元素5要使用:ls[1][1] - 文件可以包含任何内容,是数据的集合和抽象,是存储在辅助存储器上的数据序列,而函数或类才是程序的集合和抽象
- 打开文件后采用close()关闭文件是一个好习惯。如果不调用close(),当前Python程序完全运行退出时,该文件引用被释放,即程序退出时,相当于调用了close(),默认关闭
- Python文件的"+"打开模式,与r/w/a/x一同使用,在原功能基础上同时增加了读写功能,同时赋予文件的读写权限
- 同一个文件既可以用文本方式打卡,也可以用二进制方式打开
- 列表元素如果都是列表,其可能表示二维数据,如
[[1,2],[3,4],[5,6]],如果列表元素不都是列表,则它表示一维数据 - Python文件读操作有:read()、readline()、readlines(),没有readtext()方法
编程测试:
- 文本的平均列数:打印输出附件文件的平均列数,计算方法如下:
(1)有效行指包含至少一个字符的行,不计算空行
(2)每行的列数为其有效字符数
(3)平均列数为有效行的列数平均值,采用四舍五入方式取整数进位
#for line in f 获取的line包含每行最后的换行符(\n),所以去掉该换行符再进行统计
f = open("latex.log", "r", encoding="utf-8")
lines = 0
columns = 0
for line in f:
line = line.strip("\n")
if len(line):
lines += 1
columns += len(line)
print("{:.0f}".format(columns/lines))
f.close()
#参考答案如下:
f = open("latex.log")
s, c = 0, 0
for line in f:
line = line.strip("\n")
if line == "":
continue
s += len(line)
c += 1
print(round(s/c))
-CSV格式清洗与转换:附件是一个CSV格式文件,提取数据进行如下格式转换:
(1)按行进行倒序排列
(2)每行数据倒序排列
(3)使用分号(;)代替逗号(,)分割数据,无空格
按照上述要求转换后将数据输出
f = open("data.csv", "r", encoding="utf-8")
txt = f.readlines()
txt.reverse() #按行进行倒序排列
for line in txt:
#line = line.strip("\n") #去除末尾换行符
#line = line.replace(" ","") #去空格
line = line.strip("\n").replace(" ", "")
#ls = line.split(",")
#ls = ls[::-1]
ls = line.split(",")[::-1] #逗号分隔并将分隔后的元素倒序
print(";".join(ls)) #元素间插入分号
f.close()
#参考答案(使用strip()方法去掉每行最后的回车,使用replace()去掉每行元素两侧的空格)
f = open("data.csv")
ls = f.readlines()
ls = ls[::-1]
lt = []
for item in ls:
item = item.strip("\n")
item = item.replace(" ", "")
lt = item.split(",")
lt = lt[::-1]
print(";".join(lt))
f.close()
测验8:程序设计方法学
知识点概要:
- 用户体验:编程只是手段,程序最终为人类服务,用户体验很重要,一个提醒进度的进度条、一个永不抛出异常的程序、一个快速的响应、一个漂亮的图标、一个合适尺寸的界面等都是用户体验的组成部分。总的来说,用户体验是一切能够提升程序用户感受的组成
- 计算思维是基于计算机的思维模式,计算机出现之前,由于没有快速计算装置,计算所反映的思维模式主要是数学思维,即通过公式来求解问题。当快速计算装置出现后,计算思维才真正形成
- 软件产品 = 程序功能 + 用户体验 ;产品不仅需要功能,更需要更好的用户体验。往往,产品都需要综合考虑技术功能和人文设计,这源于产品的商业特性。即,商业竞争要求产品不能只关心技术功能,更要关心用户易用和喜好需求
- os库:
os.system()可以启动进程执行程序 - 函数是自顶向下设计的关键元素,通过定义函数及其参数逐层开展程序设计
- os.path子库:
os.path.relpath(path)用来计算相对路径 - Python第三方库安装:使用pip命令、使用集成安装工具或访问UCI网站下载安装文件,请不要直接联系作者索要第三方库
- 计算思维的本质是:抽象和自动化
- os库是Python重要的标准库之一,提供了路径操作、进程管理等几百个函数功能,覆盖与操作系统、文件操作等相关的众多功能;os库适合所有操作系统
- 计算生态以竞争发展、相互依存和迅速更迭为特点,在开源项目间不存在顶层设计,以类自然界"适者生存"的方式形成技术演进路径
编程测试:
- 英文字符的鲁棒输入:获得用户的任何可能输入,将其中的英文字符进行打印输出,程序不出现错误
inputStr = input()
for i in inputStr:
if i.islower() or i.isupper():
print(i,end="")
#参考答案:采用遍历字符的方式实现,通过约束字母表达到鲁棒效果
alpha = []
for i in range(26):
alpha.append(chr(ord('a') + i))
alpha.append(chr(ord('A') + i))
s = input()
for c in s:
if c in alpha:
print(c, end="")
- 数字的鲁棒输入:获得用户输入的一个数字,可能是浮点数或复数,如果是整数仅接收十进制形式,且只能是数字。对输入数字进行平方运算,输出结果,要求:
1)无论用户输入何种内容,程序无错误
2)如果输入有误,请输出"输入有误"
number = input()
try:
#complex()和complex(eval())之间的比较
#将能够排除非数字类型的输入
if complex(number) == complex(eval(number)):
print(eval(number) ** 2)
except:
print("输入有误")
'''
不能直接使用eval(),否则用户可以通过输入表达式(如100**2)输入数字
与要求不同(在实际应用中会带来安全隐患)
'''
测验9:Python计算生态纵览
知识点概要:
- Python网络爬虫方向第三方库有:Requests、Scrapy、pyspider
- Python数据可视化方向第三方库有:Mayavi、Matplotlib、Seaborn
- Python Web信息提取方向第三方库有:Beautiful Soup、Python-Goose、Re
- Python游戏开发第三方库有:Panda3D、cocos2d、PyGame
- Python数据分析方向第三方库有:Numpy、Pandas、Scipy
- Python图形用户界面方向(GUI)第三方库有:PyQt5、wxPython、PyGObject
- Python网站开发框架方向第三方库有:Django、Pyramid、Flask
- Python文本处理方向第三方库有:NLTK、python-docx、PyPDF2
- Python网络应用开发方向第三方库有:aip、MyQR、WeRobot
- aip是百度的人工智能功能Python访问接口
- Python人工智能方向第三方库有:TensorFlow、Scikit-learn、MXNet
- Vizard是虚拟现实第三方库
- pyovr是增强现实开发库
- redis-py是redis数据的Python访问接口
编程测试:
- 系统基本信息获取:获取系统的递归深度、当前执行文件路径、系统最大UNICODE编码值等3个信息,并打印输出;输出格式如下:
RECLIMIT:<深度>, EXEPATH:<文件路径>, UNICODE:<最大编码值>
提示:请在sys标准库中寻找上述功能
import sys
print("RECLIMIT:{}, EXEPATH:{}, UNICODE:{}".format(sys.getrecursionlimit(), sys.executable, sys.maxunicode))
- 二维数据表格输出:tabulate能够对二维数据进行表格输出,是Python优秀的第三方计算生态。编写程序,能够输出如下风格效果的表格数据
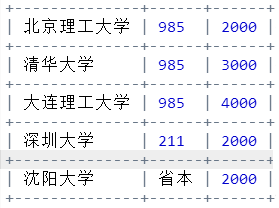
data = [ ["北京理工大学", "985", 2000], \
["清华大学", "985", 3000], \
["大连理工大学", "985", 4000], \
["深圳大学", "211", 2000], \
["沈阳大学", "省本", 2000], \
]
from tabulate import tabulate
print(tabulate(data, tablefmt="grid"))
期末测验
*编程测试:
- 无空隙回声输出:获得用户输入,去掉其中全部空格,将其他字符按收入顺序打印输出
print(input().replace(" ",""))
- 文件关键行数:关键行指一个文件中包含的不重复行。关键行数指一个文件中包含的不重复行的数量。统计附件文件中关键行的数量
f = open("latex.log", "r", encoding="utf-8")
d = {}
for line in f:
d[line] = d.get(line, 0) + 1
print("共{}关键行".format(len(d)))
#参考答案:如果需要"去重"功能,请使用集合类型
f = open("latex.log")
ls = f.readlines()
s = set(ls)
print("共{}关键行".format(len(s)))
- 剩余两题与测验九重复,不重复记录