pthread多线程入门-并行计算高维向量
介绍pthread
pthread其实也可以当作C/C++的一个库,所有的函数和数据类型都在
gcc filename.c -lpthread
pthread入门
pthread就是能让C程序的进程在运行时可以分叉为多个线程执行.例如main函数就可以分叉为下面的两个线程.
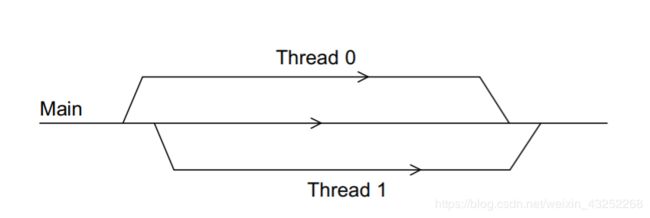
很容易想到,pthread使用分为三个部分:分叉,运行,合并.所有的过程都在下面的程序中给出.
#include 使用pthread_create函数开始分叉.pthread_create函数的第一个参数就是线程的标号,第二个参数暂时用不到,给NULL就可以了;第三个参数是在该线程执行的函数,函数的签名必须返回空指针,传递空指针的参数;第四个参数传递参数,因此也必须转成空指针.
运行线程的过程就是运行4个Hello函数的过程
使用pthread_join合并,结束线程.pthread_join第一个参数是线程的标号;第二个参数暂时不用,给NULL.
多线程计算高维向量加法
目的:
测试计算 1 0 7 10^7 107维的向量加法使用AVX和普通for循环的速度差异
实验测试的数据类型为双精度浮点数double类型,两个向量由 1 0 7 10^7 107个double类型数据组成.
废话少说,上代码.
代码:
#include 以上是main函数和每个线程执行的函数签名,具体相加的函数不是重点,放在下面.普通数组实现加法太过简单,可以参考这篇文章或者这个代码:
void *sum_vec(void *rank)
{
long my_rank = (long)rank;
// 每个线程都计算 __VEC_LENGTH__ / thread_count 个元素相加
int i;
int my_work = __VEC_LENGTH__ / thread_count;
int my_first = my_rank * my_work;
int my_last = (my_rank + 1) * my_work;
for (i = my_first; i < my_last; ++i)
{
result[i] = arr1[i] + arr2[i];
}
return NULL;
}
运行结果
| 1 | 2 | 3 | 4 | 5 | 均值 | |
|---|---|---|---|---|---|---|
| 多线程加法(单位um) | 63294 | 43699 | 42220 | 47738 | 43216 | 48033.4 |
| 单线程加法(单位um) | 81926 | 103015 | 110047 | 122131 | 90447 | 101513.2 |
实验测了5次4线程的情况得到加速比为2.11.
注:程序运行在Ryzen 5 3500U上
讨论
(1)多线程程序运行时间不可能随着线程的增加一直减少,因此这里给出1个线程到11个线程的运行时间图(单位为um):

(2)程序使用了两种不同的方式先计算向量加法,线程数为4时,理论(根据Amdahl定律)上最大的加速比应该为4.但是实际运行的过程中,由于多线程程序有调用函数、分配内存等额外开销,因此加速比远远没有到达4.当然,也有可能是在编译的过程中,编译器对本来不是并行的代码做了优化,把简单的for循环变成并行执行的程序,从而导致加速比低于4.