字符串
(1)面试题05. 替换空格
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
示例 1:
输入:s = "We are happy."
输出:"We%20are%20happy."
class Solution {
public:
string replaceSpace(string s) {
string res;
for(int i=0; i<s.size(); i++){
if(s[i]==' '){ //好像只能 ' '
res += "%20"; //这是 "%20"
}
else{
res += s[i];
}
}
return res;
}
};
(2)面试题38. 字符串的排列(LC46 数字全排列(已归 DFS / 回溯))
与LC46(无重复元素)区别在于,该题可能有重复元素,比如"aab"输出为[“aba”,“aab”,“baa”]而不是[“aab”,“aba”,“aab”,“aba”,“baa”,“baa”]
输入一个字符串,打印出该字符串中字符的所有排列。
你可以以任意顺序返回这个字符串数组,但里面不能有重复元素。
示例:
输入:s = "abc"
输出:["abc","acb","bac","bca","cab","cba"]
讲解:
/*
* 回溯法
*
* 字符串的排列和数字的排列都属于回溯的经典问题
*
* 回溯算法框架:解决一个问题,实际上就是一个决策树的遍历过程:
* 1. 路径:做出的选择
* 2. 选择列表:当前可以做的选择
* 3. 结束条件:到达决策树底层,无法再做选择的条件
*
* 伪代码:
* result = []
* def backtrack(路径,选择列表):
* if 满足结束条件:
* result.add(路径)
* return
* for 选择 in 选择列表:
* 做选择
* backtrack(路径,选择列表)
* 撤销选择
*
* 核心是for循环中的递归,在递归调用之前“做选择”,
* 在递归调用之后“撤销选择”。
*
* 字符串的排列可以抽象为一棵决策树:
* [ ]
* [a] [b] [c]
* [ab] [ac] [bc] [ba] [ca] [cb]
* [abc] [acb] [bca] [bac] [cab] [cba]
*
* 考虑字符重复情况:
* [ ]
* [a] [a] [c]
* [aa] [ac] [ac] [aa] [ca] [ca]
* [aac] [aca] [aca] [aac] [caa] [caa]
*
* 字符串在做排列时,等于从a字符开始,对决策树进行遍历,
* "a"就是路径,"b""c"是"a"的选择列表,"ab"和"ac"就是做出的选择,
* “结束条件”是遍历到树的底层,此处为选择列表为空。
*
* 本题定义backtrack函数像一个指针,在树上遍历,
* 同时维护每个点的属性,每当走到树的底层,其“路径”就是一个全排列。
* 当字符出现重复,且重复位置不一定时,需要先对字符串进行排序,
* 再对字符串进行“去重”处理,之后按照回溯框架即可。
* */
法1:DFS
注意(tip):
1.用set去重。
2.为什么把把变量定义到开头成全局变量? 因为这样定义的话就不用从dfs(s,0)中往下传更多的参数,下面的函数用到的时候很方便。
3.string也可以理解成一种特殊的容器,所以也可以用string.push_back()
class Solution {
public:
int n;//定义成全局变量
string tmp;
vector<bool> st;
//vector res;
set<string> res; //使用set去重
vector<string> permutation(string s) {
if(s.empty()) return {};
n=s.size();
st=vector<bool> (n);
dfs(s,0);
return vector<string>(res.begin(),res.end());
}
void dfs(string & s, int u){
if(u==n){
res.insert(tmp);
return;
}
for(int i=0; i<n; i++){
if(!st[i]){
st[i]=true;
tmp.push_back(s[i]);
dfs(s,u+1);
tmp.pop_back();
st[i]=false;
}
}
}
};
法2:next_perputation()
class Solution {
public:
vector<string> permutation(string s) {
if(s.empty()) return {};
sort(s.begin(), s.end());//注意
vector<string> res;
res.push_back(s);
while(next_permutation(s.begin(),s.end())){
res.push_back(s);
}
return res;
}
};
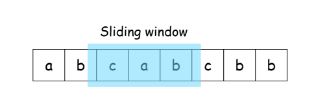
(3)面试题48. 最长不含重复字符的子字符串【中等】
请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
子串与子序列的区别:
子串:
示例 :
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
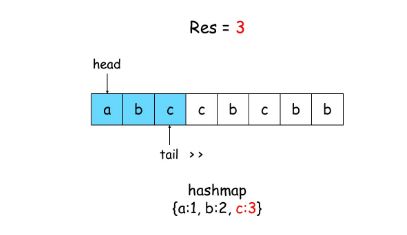
思路:hash 动画讲解
class Solution {
public:
int lengthOfLongestSubstring(string s) {
if(s.empty()) return 0;
if(s.size()==1) return 1;
unordered_map<char,int> m; //注意char, map<char,int> m 也行
int head=0,res=0;
for(int tail=0;tail<s.size();++tail)
{ //因为会有 l > ~ 的情况;例如这个样例 "abba"。
if(m.find(s[tail])!=m.end()) head=max(m[s[tail]],head);//
m[s[tail]]=tail+1;
res=max(res,tail-head+1);
}
return res;
}
};
(4)面试题50. 第一个只出现一次的字符
在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。
示例:
s = "abaccdeff"
返回 "b"
s = ""
返回 " "
思路:hash
class Solution {
public:
char firstUniqChar(string str) {
map<char, int> mp;
for(int i = 0; i < str.size(); i++)
mp[str[i]]++;
for(int i = 0; i < str.size(); i++){
if(mp[str[i]]==1)
return str[i]; //如果题目要求输出位置,就return i;
}
return ' ';
}
};
(5)面试题58 - II. 左旋转字符串
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。
示例 1:
输入: s = "abcdefg", k = 2
输出: "cdefgab"
示例 2:
输入: s = "lrloseumgh", k = 6
输出: "umghlrlose"
法1: 先翻转前n个,再翻转后n个,最后再整体翻转。
class Solution {
public:
string reverseLeftWords(string str, int n) {
int len=str.length();
if(str.empty()||n<=0)
return str; //假设输入str为abcXYZdef,n=3
//参数是下标
Reverse(str,0,n-1); //反转前n个字符,得到cbaXYZdef
Reverse(str,n,len-1); //反转第n个字符后面所有的字符cbafedZYX
Reverse(str,0,len-1); //反转整个字符串XYZdefabc
return str;
}
//交换函数
void Reverse(string & str,int begin,int end){
while(begin<end)
swap(str[begin++],str[end--]);
}
/* //交换函数
void Reverse(string &str,int begin,int end)
{
int temp;
while(begin
};
法2: 对函数的一种熟练运用
class Solution {
public:
string reverseLeftWords(string str, int n) {
if(n<0) return NULL;
if(n==0) return str;
//string s1=str.substr(0,n);//添加n个;
string s1(str,0,n);//从第0个开始,添加n个
str.erase(0,n);//删除迭代器0和n范围内的元素 p311;
str=str+s1;
return str;
}
};
法3: 两个for循环吧,先加这部分再加那部分
class Solution {
public:
string reverseLeftWords(string s, int n) {
string res=""; //''报错
for(int i=n; i<s.size(); i++){
res += s[i];
}
for(int i=0; i<n; i++){
res += s[i];
}
return res;
}
};
(6)面试题58 - I. 翻转单词顺序
输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变。为简单起见,标点符号和普通字母一样处理。例如输入字符串"I am a student. “,则输出"student. a am I”。
示例 1:
输入: "the sky is blue"
输出: "blue is sky the"
示例 2:
输入: " hello world! "
输出: "world! hello"
解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
示例 3:
输入: "a good example"
输出: "example good a"
解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
如果像例1一样,没有多余的空格(牛客就只有例1),则下面这样挺好理解
2次翻转。用两个指针,先翻转整个句子,再翻转句子中的每个单词。
end--;
reverse(str,begin,end);
这两句话合并后应该是reverse(str,begin,–end); 而不是reverse(str,begin,end–);,因为要先减了之后才送入函数。
class Solution {
public:
//先翻转整个句子,再翻转句子中的每个单词
string ReverseSentence(string str) {
if(str.empty())//如果是指针,才说指针不为null
return str;
int length=str.length();//
reverse(str,0,length-1);
int begin=0;
int end=0;
while(str[begin]!='\0'){
if(str[begin]==' '){
begin++;
end++;
}
else if(str[end]==' '||str[end]=='\0'){
end--;
reverse(str,begin,end);
end++;
begin=end;
}
else
end++;
}
return str;
}
void reverse(string & str,int begin,int end){
while(begin<end)
swap(str[begin++],str[end--]);
}
};
如果有多余的空格,像例2例3,用stringsream比较方便
class Solution {
public:
string reverseWords(string s) {
stringstream ss(s);
string ans="",temp;
// ss<
while(ss>>temp){ //ss流输入到temp 比如:I am a boy 第一个输入temp的是I
ans=" "+temp+ans;
}
if(ans!="")
ans.erase(ans.begin());
return ans;
}
};
注意:
初始化字符串的时候用 双引号 “”
空格用 单引号 ’ '