爬取中国最好大学网数据(Python的Scrapy框架与Xpath联合运用)
前言
大二上学期学校外出实习,做了一个关于爬取中国最好大学网http://www.zuihaodaxue.com/rankings.html的项目用的这个Scrapy框架,多线程还挺好用,爬取结束后用Pyecharts作图。写的代码可能有点粗糙,只是抒发拙见,还请各位大佬勿怪。
鄙人仅为一名普普通通大二学生,才学浅出,来此各地高人聚集处书写浅见,还望各位前辈高人多多指点海涵。我们诚邀各地有志之士加入我们的代码学习群交流:871352155(无论你会C/C++还是Java,Python还是PHP......有兴趣我们都欢迎你的加入,不过还请各位认真填写加群信息。群内目前多为大学生,打广告的先生女士就请不要步足了。我们希望有远见卓识的前辈能为即将步入社会的初犊提出建议指引方向。)
前情提要
之前啊,我写过一片关于Pyecharts的文章,是关于数据可视化,有兴趣的朋友可以去看看https://blog.csdn.net/weixin_43341045/article/details/104137445,关于这个数据的来源啊,可以很多种,我这里就介绍下爬虫。爬虫也有很多种库,写过一篇关于Selenium的爬虫https://blog.csdn.net/weixin_43341045/article/details/104014416。还有一个9行代码爬取B站专栏图片(BeautifulSoup4)https://blog.csdn.net/weixin_43341045/article/details/104411456
源码下载地址https://download.csdn.net/download/weixin_43341045/12520883
安装Scrapy框架方法
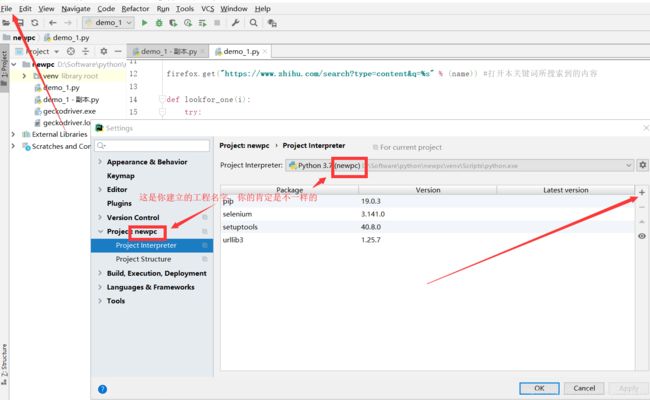
打开cmd后,输入pip install scrapy。如果你是用pycharm,左上角的File找到setting,然后在Project:XXX里面有个Project Interpreter,你会看见右边有一堆是你已经安装好的库,然后点击更靠右的+写上scrapy点击install package
1.1 研究背景
过去的网络爬虫主要以手动敲写正则表达式的方式给出爬取目标,但是这种“手工编写正则”的编写过程相对于利用Xpath来确定HTML文件部分位置将会节约大量时间。因此如何能够方便使用爬虫、提高爬行效率、在单位时间内尽可能多的获取高质量页面,已经成为目前网络爬虫研究的一个重要课题。
1.2 网络爬虫的发展概述
自1993年初 Matthew Gray’s Wandered 在麻省理工学院开发出有史记载的第一个网络爬虫以来,爬虫技术历经20多年的发展,技术已日趋多样。为满足不同用户多种多样的需求,创建开发了类型众多的爬虫系统
第2章 系统设计
2.1 系统架构
整个系统主要有六个模块,爬虫主控模块,网页下载模块,网页解析模块,URL 调度模块,数据存储模块,可视化模块。这几个模块之间相互协作,共同完成网络数据抓取的功能。
(1)主控模块,主要是完成一些初始化工作,生成种子 URL, 并将这些 URL 放入待爬取 URL 队列,启动网页下载器下载网页,然后解析网页,提取需要的数据和 URL 地址,进入工作循环,控制各个模块工作流程,协调各个模块之间的工作
(2)网页下载模块,主要功能就是下载网页,但其中有几种情况,对于可以匿名访问的网页,可以直接下载,对于需要身份验证的,就需要模拟用户登陆后再进行下载,对于需要数字签名或数字证书才能访问的网站,就需要获取相应证书,加载到程序中,通过验证之后才能下载网页。网络上数据丰富,对于不同的数据,需要不同的下载方式。数据下载完成后,将下载的网页数据传递给网页解析模块,将URL 地址放入已爬取 URL队列。
(3)网页解析模块,它的主要功能是从网页中提取满足要求的信息传递给数据清洗模块,提取 URL 地址传递给URL 调度模块,另外,它还通过正则表达式匹配的方式或Xpath或直接搜索的方式,来提取满足特定要求的数据,将这些数据传递给数据清洗模块。
(4)URL 调度模块,接收网页解析模块传递来的 URL地址,然后将这些 URL 地址和已爬取 URL 队列中的 URL 地址比较,如果 URL 存在于已爬取 URL 队列中,就丢弃这些URL 地址,如果不存在于已爬取 URL 队列中,就按系统采取的网页抓取策略,将 URL 放入待爬取 URL 地址相应的位置。
(5)数据存储模块,接收网页解析模块传送来的数据,网页解析模块提取的数据,一般是比较杂乱或样式不规范的数据,这就需要对这些数据进行清洗,整理,将这些数据整理为满足所需要的格式后,将数据存入不同的格式的文件当中,长期保存。最终将这些数据存入Sqlite数据库中。
(6)数据可视化模块,根据用户需求,统计数据库中的数据,将统计结果的文本格式以各式各样的图表展示出来,长期保存。
2.2 数据库设计
通过数据库语言定义字段名、数据类型、数据长度等创建表格,将uid设定为主键,防止数据重复、方便索引。创建表格后即可将爬取的数据写入数据库中。
高校信息表:
| 字段名 |
类型 |
长度 |
是否主键 |
是否为空 |
说明 |
| uid |
Int |
2147483647 |
是 |
否 |
自增序号 |
| rank |
Varchar |
50 |
否 |
否 |
排名 |
| uname |
Varchar |
60 |
否 |
否 |
学校名称 |
| loc |
Varchar |
50 |
否 |
否 |
省市 |
| score |
Int |
50 |
否 |
否 |
总分 |
| Matriculate_quality |
Varchar |
50 |
否 |
否 |
生源质量 |
| Culture_results |
Varchar |
50 |
否 |
否 |
培养结果 |
| Social_honor |
Varchar |
50 |
否 |
否 |
社会声誉 |
| Scientific_scale |
Varchar |
50 |
否 |
否 |
科研规模 |
| Quality_scientific |
Varchar |
50 |
否 |
否 |
科研质量 |
| Top_results |
Varchar |
50 |
否 |
否 |
顶尖成果 |
| Top_talent |
Varchar |
50 |
否 |
否 |
顶尖人才 |
| Science_technology_service |
Varchar |
50 |
否 |
否 |
科技服务 |
| Achievements_transformation |
Varchar |
50 |
否 |
否 |
成果转化 |
| Proportion_international |
Varchar |
50 |
否 |
否 |
学生国际化 |
2.3 网络爬虫的理论基础
网络爬虫是一个自动提取网页的程序,他为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。通用网络爬虫,又称“全网爬虫”,爬行对象从一些种子URL(统一资源定位符) 扩充到整个万维网,主要为“门户站点搜索引擎”和“大型Web服务提供商”采集数据。由于商业原因,它们的技术细节很少被公布出来。这类网络爬虫的爬行范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于等待刷新的页面太多,通常采用“并行工作”的方式,但需要较长时间才能刷新一次页面。通用网络爬虫,虽然存在着一定的缺陷,但它适用于为搜索引擎平台搜索广泛的主题,有较强的应用价值。
2.4 基于Scrapy框架的爬虫研究
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
2.4.1 Scrapy基本功能
Scrapy是一个为爬取网站数据、提取结构性数据而设计的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
2.4.2 Scrapy的架构
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件.
2.4.3 Scrapy的使用方法
1.新建项目 :新建一个新的爬虫项目
2.明确目标 (编写items.py):明确你想要抓取的目标
3.制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
4.存储内容 (pipelines.py):设计管道存储爬取内容
2.5 基于Xpath的标签选择研究
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
2.5.1 Xpath简介
XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPoiter与XSL间的语法模型。但是XPath很快的被开发者采用来当作小型查询语言
2.5.2 Xpath表达式
在XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。路径表达式是从一个XML节点(当前的上下文节点)到另一个节点、或一组节点的书面步骤顺序。这些步骤以“/”字符分开,每一步有三个构成成分:
2.5.3 Xpath运算符
| 运算符 |
描述 |
实例 |
返回值 |
| | |
计算两个节点集 |
//book | //cd |
返回所有拥有 book 和 cd 元素的节点集 |
| + |
加法 |
6 + 4 |
10 |
| - |
减法 |
6 - 4 |
2 |
| * |
乘法 |
6 * 4 |
24 |
| div |
除法 |
8 div 4 |
2 |
| = |
等于 |
price=9.80 |
如果 price 是 9.80,则返回 true。 如果 price 是 9.90,则返回 false。 |
| != |
不等于 |
price!=9.80 |
如果 price 是 9.90,则返回 true。 如果 price 是 9.80,则返回 false。 |
| < |
小于 |
price<9.80 |
如果 price 是 9.00,则返回 true。 如果 price 是 9.90,则返回 false。 |
| <= |
小于或等于 |
price<=9.80 |
如果 price 是 9.00,则返回 true。 如果 price 是 9.90,则返回 false。 |
| > |
大于 |
price>9.80 |
如果 price 是 9.90,则返回 true。 如果 price 是 9.80,则返回 false。 |
| >= |
大于或等于 |
price>=9.80 |
如果 price 是 9.90,则返回 true。 如果 price 是 9.70,则返回 false。 |
| or |
或 |
price=9.80 or price=9.70 |
如果 price 是 9.80, 或者 price 是 9.70,则返回 true。 |
| and |
与 |
price>9.00 and price<9.90 |
如果 price 大于 9.00, 并且 price 小于9.90,则返回 true。 |
| mod |
除法的余数 |
5 mod 2 |
|
2.6 基于Sqlite的数据库管理研究
SQLite,是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它是D.RichardHipp建立的公有领域项目。它的设计目标是嵌入式的,而且已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。它能够支持Windows/Linux/Unix等等主流的操作系统,同时能够跟很多程序语言相结合,比如 Tcl、C#、PHP、Java等,还有ODBC接口,同样比起Mysql、PostgreSQL这两款开源的世界著名数据库管理系统来讲,它的处理速度比他们都快。SQLite第一个Alpha版本诞生于2000年5月。 至2015年已经有15个年头,SQLite也迎来了一个版本 SQLite 3已经发布。
2.6.1 Sqlite的工作原理
不像常见的客户-服务器范例,SQLite引擎不是个程序与之通信的独立进程,而是连接到程序中成为它的一个主要部分。所以主要的通信协议是在编程语言内的直接API调用。这在消耗总量、延迟时间和整体简单性上有积极的作用。整个数据库(定义、表、索引和数据本身)都在宿主主机上存储在一个单一的文件中。它的简单的设计是通过在开始一个事务的时候锁定整个数据文件而完成的
2.6.2 Sqlite的功能特性
1. ACID事务
2. 零配置 – 无需安装和管理配置
3. 储存在单一磁盘文件中的一个完整的数据库
4. 数据库文件可以在不同字节顺序的机器间自由的共享
5. 支持数据库大小至2TB
6. 足够小, 大致13万行C代码, 4.43M
7. 比一些流行的数据库在大部分普通数据库操作要快
8. 简单, 轻松的API
9. 包含TCL绑定, 同时通过Wrapper支持其他语言的绑定
10. 良好注释的源代码, 并且有着90%以上的测试覆盖率
11. 独立: 没有额外依赖
12. 源码完全的开源, 你可以用于任何用途, 包括出售它
13. 支持多种开发语言,C, C++, PHP, Perl, Java, C#,Python, Ruby
2.7 本章小结
本章介绍Xpath定位文档路径的思想提出和理论基础,其次详细介绍了Sqlite数据库和Scrapy框架。
第3章 系统实现
3.1 运行爬虫爬取数据
通过“cd university(自定义爬虫名称)”命令进入到爬虫项目文件 夹根目录中,运行启动爬虫的命令“scrapy crawl universityspider(自定义爬虫名称)”,Scrapy为爬虫的start_urls属性中的每个URL链 接创建对应的响应对象Response,为创建的响应对象指定回调函数prase(),接着调度响应对象、执行下载器程序, 执行完成后生成响应对象,最后把响应对象反馈到Spider 类。在主题爬虫的运行过程中,首先收集与主题相关的页 面并将其称为URL种子集,然后从种子页面开始,将与主题相关度大的URL链接放入等待队列,减少无关网页的下载带来的消耗,确定每个链接的优先级。
3.2 数据存储
由于该文选用的是最好大学排名网站,将爬取筛选 后的数据存放到item中,运用Scrapy框架里包含的Feed exports命令可以很方便地导出文件,保存爬取到的各高校信息。 但是该文提取高校信息的目的是为了方便分析了解各高校,因而最终希望将爬取的信息数据导出到Sqlite文件中。

此图为运用Python 丰富强大的Sqlite3的库生成的数据库,Sqlite库中包含creat table,sqlite3.connect,cursor.execute等函数。其中creat table用来创建数据库表;sqlite3.connect对数据库的连接;cursor.execute用来执行增删查改等操作。
前端页面

#网页下载解析模块:
import random
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
class RotateUserAgentMiddleware(UserAgentMiddleware):
def __init__(self,user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
ua = random.choice(self.USER_AGENT_LIST)
if ua:
request.headers.setdefault('User-Agent', ua)
USER_AGENT_LIST = [ \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" \
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"#主控模块:
# -*- coding: utf-8 -*-
import scrapy
from university.items import UniversityItem
class UniversityspiderSpider(scrapy.Spider):
name = 'universityspider'
allowed_domains = ['zuihaodaxue.com']
start_urls = ['http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html']
def parse(self, response):
current_page_msg = response.xpath("//table[@class='table table-small-font table-bordered table-striped']/tbody[@class='hidden_zhpm']/tr[@class='alt']")
for msg in current_page_msg:
university = UniversityItem()
university['rank'] = msg.xpath('td[1]/text()').extract()
university['name'] = msg.xpath('td[2]/div/text()').extract()
university['loc'] = msg.xpath('td[3]/text()').extract()
university['score']=msg.xpath('td[4]/text()').extract()
university['Matriculate_quality']=msg.xpath("td[@class='hidden-xs need-hidden indicator5']/text()").extract()
university['Culture_results']=msg.xpath("td[@class='hidden-xs need-hidden indicator6']/text()").extract()
if(msg.xpath("td[@class='hidden-xs need-hidden indicator6']/text()").extract()==[]):
university['Culture_results']=['暂无数据']
else:
university['Culture_results'] = msg.xpath("td[@class='hidden-xs need-hidden indicator6']/text()").extract()
university['Social_honor']=msg.xpath("td[@class='hidden-xs need-hidden indicator7']/text()").extract()
university['Scientific_scale']=msg.xpath("td[@class='hidden-xs need-hidden indicator8']/text()").extract()
university['Quality_scientific']=msg.xpath("td[@class='hidden-xs need-hidden indicator9']/text()").extract()
university['Top_results']=msg.xpath("td[@class='hidden-xs need-hidden indicator10']/text()").extract()
university['Top_talent']=msg.xpath("td[@class='hidden-xs need-hidden indicator11']/text()").extract()
university['Science_technology_service']=msg.xpath("td[@class='hidden-xs need-hidden indicator12']/text()").extract()
university['Achievements_transformation']=msg.xpath("td[@class='hidden-xs need-hidden indicator13']/text()").extract()
university['Proportion_international']=msg.xpath("td[@class='hidden-xs need-hidden indicator14']/text()").extract()
yield university
后序
这个爬虫我不仅做了pyecharts数据可视化,还做了神经网络的预测和分类。由于课程繁忙等原因,写的很粗糙,有机会一定更新。