LeetCode刷题值得推荐的几个Python库
from collections import defaultdict,Counter
from functools import lru_cache
from itertools import combinations, permutations
import bisect,heapq
1、collections模块
使用defaultdict和Counter可以节省很多步骤,Counter统计列表的值出现的次数,并按多到少排序输出。
from collections import defaultdict,Counter
#defaultdict默认字典的键和值可以不存在
dic1 = defaultdict(int) #{:0}
dic1[1]+1
print(dic1)
#dic1 = {1:1}
dic2 = defaultdict(list) #{:[]}
dic2[1].append(1)
print(dic2)
#dic2 = {1:[1]}
#dic3 = defaultdict(set) #{:{}}
nums = [1,2,3,3,2,3,1,1,5,4,4,1,1]
count = Counter(nums)
print(count)
#count = Counter({1: 5, 3: 3, 2: 2, 4: 2, 5: 1})
collections.Orderdict() 能够对添加进来的键值对按添加先后的顺序排序,在LeetCode第146题LRU缓存机制中用到,很巧妙。
import collections
d1 = collections.OrderedDict()
d1['a'] = 'A'
d1['b'] = 'B'
d1['2'] = '2'
d1['c'] = 'C'
d1['1'] = '1'
print(d1,'\n')
d1.move_to_end('a') #把key='a'的值移到d1最后
print(d1,'\n')
d1.pop('c') #弹出key='c'的值
print(d1,'\n')
d1.popitem(last=False) #弹出d1第一个值,last=True弹出最后一个值
print(d1)
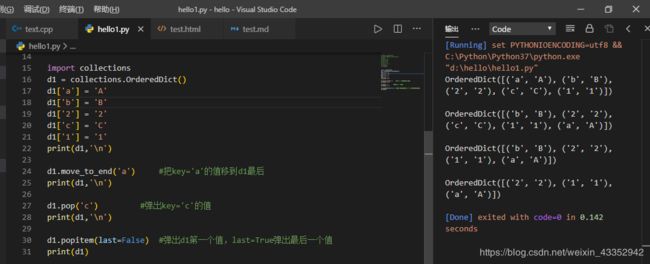
python字典现在是有序的了,除了上面的move_to_end()外,pop(),popitem()功能dict都能实现
2、itertools模块
itertools模块有很多功能,这里只讲常用的两个,combinations和permutations
import itertools
#combinations生成的子列表不重复,第一个参数为iterable对象,第二个参数为子列表的长度
x = list(itertools.combinations('ABC',2))
print(x)
#x = [('A', 'B'), ('A', 'C'), ('B', 'C')]
import itertools
#permutations生成的子列表包括重复,第一个参数为iterable对象,第二个参数为子列表的长度
x = list(itertools.permutations('ABC',2))
print(x)
# x = [('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'C'), ('C', 'A'), ('C', 'B')]
3、functools模块
functools.lru_cache()是非常实用的装饰器,它实现了备忘功能,把函数的结果保存起来,避免函数传入相同的参数时重复计算,lru_cache(maxsize,typed=False)有两个可选的参数,第一个是指定储存多少个调用函数的结果,第二个设为True,会把不同参数类型的结果分开保存,即把通常认为相等的浮点数和整数参数区分开。这两个参数一般都用不到。
在LeetCode中斐波那契数列的计算中使用lru_cache比没使用的快了40倍
#使用lru_cache()装饰器,参数必须是可散列值,
#可散列值例如int,str,float,不可散列如list,dict,set
import functools
class Solution:
@functools.lru_cache()
def fib(self, N: int) -> int:
if N < 2: return N
return self.fib(N-1) + self.fib(N-2)
4、bisect模块
bisect采用二分查找法返回排序数组指定值的下标,如果指定值不存在,返回应该插入的下标位置
import bisect
arr = [1,2,3,4,6,7]
x1 = bisect.bisect_left(arr,3) #返回arr中3的下标,不存在则返回应该插入的位置下标
#x1 = 2
x2 = bisect.bisect_right(arr,3)
#x2 = 3
bisect.insort_left(arr,3) #向arr左边插入值3
print(arr)
#arr = [1, 2, 3, 3, 4, 6, 7]
# bisect.insort_right(arr,3)
暂时只有这么多。
5、gcd(), ord(), chr()
math.gcd(a,b)用来求a和b两个数的最大公约数,刷LeetCode时有些题需要求公约数,使用gcd()会方便很多。
ord() 函数是 chr() 函数的配对函数,它以一个字符(长度为1)作为参数,返回对应的数值。chr()则以数值作为参数,返回字符。
# from fractions import gcd
import math
x = math.gcd(18,12) #求最大公约数
print(x) #x = 6
# ord('a')~ord('z') => 97~122 大写字母A--Z => 65--90
print(ord('a')) #ord('a') => 97
print(ord('z')) #ord('z') => 122
#更多符号
for i in range(33,128):
print(chr(i),end=' ')
#输出如下注释:
'''! " # $ % & ' ( ) * + , - . / 0 1 2 3 4 5 6 7 8 9 : ; < = >
? @ A B C D E F G H I J K L M N O P Q R S T U V W X Y Z [ \ ]
^ _ ` a b c d e f g h i j k l m n o p q r s t u v w x y z { | } ~ '''
#chr()函数则反过来
print(chr(65)) # => 'A'
print(chr(90)) # => 'Z'
6、heapq
- heappush(heap, x) :将x压入堆中
- heappop(heap) : 从堆中弹出最小的元素
- heapify(heap) :让列表具备堆特征
- heapreplace(heap, x) :弹出最小的元素,并将x压入堆中
- nlargest(n, iter):返回iter中n个最大的元素
- nsmallest(n, iter):返回iter中n个最小的元素