线性回归
什么是回归分析
回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。通常使用曲线/线来拟合数据点,目标是使曲线到数据点的距离差异最小。
线性回归
线性回归是回归问题中的一种,线性回归假设目标值与特征之间线性相关,即满足一个多元一次方程。通过构建损失函数,来求解损失函数最小时的参数w和b。通长我们可以表达成如下公式:
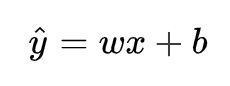
y_hat为预测值,自变量x和因变量y是已知的,而我们想实现的是预测新增一个x,其对应的y是多少。因此,为了构建这个函数关系,目标是通过已知数据点,求解线性模型中w和b两个参数。
目标/损失函数
求解最佳参数,需要一个标准来对结果进行衡量,为此我们需要定量化一个目标函数式,使得计算机可以在求解过程中不断地优化。
针对任何模型求解问题,都是最终都是可以得到一组预测值y_hat ,对比已有的真实值 y ,数据行数为 n ,可以将损失函数定义如下:
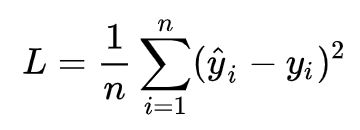
即预测值与真实值之间的平均的平方距离,统计中一般称其为MSE(mean square error)均方误差。把之前的函数式代入损失函数,并且将需要求解的参数w和b看做是函数L的自变量,可得

现在的任务是求解最小化L时w和b的值,
即核心目标优化式为

求解方式有两种:
1)最小二乘法(least square method)
求解 w 和 b 是使损失函数最小化的过程,在统计中,称为线性回归模型的最小二乘“参数估计”(parameter estimation)。我们可以将 L(w,b) 分别对 w 和 b 求导,得到

令上述两式为0,可得到 w 和 b 最优解的闭式(closed-form)解:

2)梯度下降(gradient descent)
梯度下降核心内容是对自变量进行不断的更新(针对w和b求偏导),使得目标函数不断逼近最小值的过程
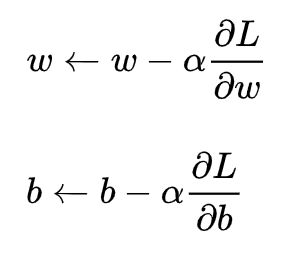
code
建立linear_regression.py文件,用于实现线性回归的类文件,包含了线性回归内部的核心函数:
# -*- coding: utf-8 -*-
import numpy as np
class LinerRegression(object):
def __init__(self, learning_rate=0.01, max_iter=100, seed=None):
np.random.seed(seed)
self.lr = learning_rate
self.max_iter = max_iter
self.w = np.random.normal(1, 0.1)
self.b = np.random.normal(1, 0.1)
self.loss_arr = []
def fit(self, x, y):
self.x = x
self.y = y
for i in range(self.max_iter):
self._train_step()
self.loss_arr.append(self.loss())
# print('loss: \t{:.3}'.format(self.loss()))
# print('w: \t{:.3}'.format(self.w))
# print('b: \t{:.3}'.format(self.b))
def _f(self, x, w, b):
return x * w + b
def predict(self, x=None):
if x is None:
x = self.x
y_pred = self._f(x, self.w, self.b)
return y_pred
def loss(self, y_true=None, y_pred=None):
if y_true is None or y_pred is None:
y_true = self.y
y_pred = self.predict(self.x)
return np.mean((y_true - y_pred)**2)
def _calc_gradient(self):
d_w = np.mean((self.x * self.w + self.b - self.y) * self.x)
d_b = np.mean(self.x * self.w + self.b - self.y)
return d_w, d_b
def _train_step(self):
d_w, d_b = self._calc_gradient()
self.w = self.w - self.lr * d_w
self.b = self.b - self.lr * d_b
return self.w, self.b
train.py 文件,用于生成模拟数据,并调用 liner_regression.py 中的类,完成线性回归任务
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from liner_regression import *
def show_data(x, y, w=None, b=None):
plt.scatter(x, y, marker='.')
if w is not None and b is not None:
plt.plot(x, w*x+b, c='red')
plt.show()
# data generation
np.random.seed(272)
data_size = 100
x = np.random.uniform(low=1.0, high=10.0, size=data_size)
y = x * 20 + 10 + np.random.normal(loc=0.0, scale=10.0, size=data_size)
# plt.scatter(x, y, marker='.')
# plt.show()
# train / test split
shuffled_index = np.random.permutation(data_size)
x = x[shuffled_index]
y = y[shuffled_index]
split_index = int(data_size * 0.7)
x_train = x[:split_index]
y_train = y[:split_index]
x_test = x[split_index:]
y_test = y[split_index:]
# visualize data
# plt.scatter(x_train, y_train, marker='.')
# plt.show()
# plt.scatter(x_test, y_test, marker='.')
# plt.show()
# train the liner regression model
regr = LinerRegression(learning_rate=0.01, max_iter=10, seed=314)
regr.fit(x_train, y_train)
print('cost: \t{:.3}'.format(regr.loss()))
print('w: \t{:.3}'.format(regr.w))
print('b: \t{:.3}'.format(regr.b))
show_data(x, y, regr.w, regr.b)
# plot the evolution of cost
plt.scatter(np.arange(len(regr.loss_arr)), regr.loss_arr, marker='o', c='green')
plt.show()
这里引用了https://www.cnblogs.com/geo-will/p/10468253.html的部分公式和代码
另有sklearn可以实现