GraphSAGE论文总结及源码解读
论文总结
论文地址,源码
本文只对论文做简单的总结分析,不详细介绍,GraphSAGE(即SAmple and aggreGatE)的主要贡献是引入了Inductive和Sample。
- Inductive:它把Aggregate function拆分出来,训练Aggregator让其学会聚合其邻居节点的feature,因此在训练时是看不到test节点的。而GCN采用全图的计算方式,学习到的参数很大程度是跟图结构有关,因此是transductive的(很大程度上是由于图拉普拉斯矩阵导致的。而GraphSAGE的聚合方式为:
a v ( k ) = A G G R E G A T E ( { h u ( k − 1 ) , u ∈ N ( v ) } ) h v ( k ) = σ ( W ( k ) [ h v ( k − 1 ) ∣ ∣ a v ( k ) ] ) a_v^{(k)}=AGGREGATE(\{h_u^{(k-1)},u\in N(v)\})\\ h_v^{(k)}=\sigma(W^{(k)}[h_v^{(k-1)}||a_v^{(k)}]) av(k)=AGGREGATE({hu(k−1),u∈N(v)})hv(k)=σ(W(k)[hv(k−1)∣∣av(k)])可以看到它采用逐点计算方式,学习到的参数与图结构无关,因此可以处理新节点任务。 - Sample:这篇论文的另一个亮点是对邻居进行了采样,采样思想也很简单。它主要是为了解决大图训练中内存溢出的问题,实际上这种采样比较繁琐(个人观点),在一些小图上时间反而比GCN还慢。这种方法的缺点是仍会造成内存溢出问题,例如计算第K层的一个顶点的embedding时需要第K-1层的邻居节点,同理计算第K-1层的邻居节点时又需要它在第K-2层的邻居节点,这种递归展开的现象称为neighborhood expansion problem,因此当GNN的层数很深时或节点的度很大时(节点的度符合幂律分布power-law distribution,即少数节点的度十分大)仍然会造成内存溢出。因此作者提出在抽样时固定邻居节点个数来缓解这个问题,假设一个batch的大小为b,为每个顶点固定抽样邻居的数量为r,GNN的层数为K,F为输入特征大小,其空间复杂度为 O ( b r K F + K F 2 ) O(br^KF+KF^2) O(brKF+KF2),其中 b r K br^K brK代表一共需要用到的节点数( r K r^K rK为递归邻域展开导致的), b r K F br^KF brKF为所有节点需要存储的embedding, F 2 F^2 F2为K个聚合器参数 W ( k ) W^{(k)} W(k) )的大小,这里假设了每一层的embedding都是F。
此外它还提出了3种聚合函数:Mean aggregator、Pooling aggregator、LSTM aggregator,值得一提的是,采样LSTM聚合方式更加复杂,所以有更强的表达能力,但实际上LSTM要求的是一种序列的输入,作者提出将邻居节点的特征向量随机排序得到一个序列并将其输入LSTM中,因此不同输入顺序会使得输出结果也不同,所以这种聚合器并不是对称的,也即不满足排列不变性permutation invariant,而Mean aggregator和Pooling aggregator都满足排列不变性,即改变输入节点的顺序,聚合函数的输出结果也不改变。
源码解读
GraphSAGE的源码中提供了两种训练方式的入口,supervised_train.py和unsupervised_train.py两种方式,本文只介绍有监督部分,本文从supervised_train.py开始逐步介绍GraphSAGE的思想,旨在讲懂代码中比较繁琐较难理解的地方并将其与论文中的公式对应,一些方法的使用示例会在代码中注释,文中只讲解重要的方法(其它细节可以参考另外一篇博客,这篇文章分析了无监督训练和一些其它方法,本文可以看作是它的补充,两篇文章一起读相信会起到更好的作用),希望对读者有所帮助。首先从下图大致明确代码的框架,各文件直接的调用层次。
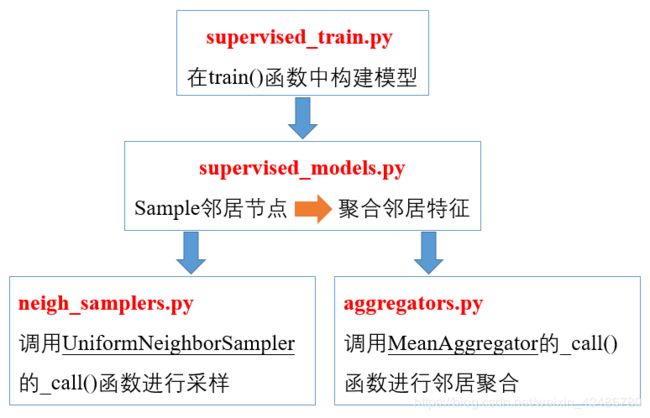
从supervised_train.py的train()函数开始,假设数据已经加载,load_data的具体操作放在文末代码注释中,我们可以获得:G图结构,features每个节点的特征(已经标准化),该例中ppi的特征大小是50,节点个数是14755,因此features的shape是(14755,50),id_map是一个字典,对应了每个节点的编号,例如{‘1’:1},表示节点’1’的编号是1,class_map是一个字典,对应了每个节点所属的类,表示为one-hot编码,ppi数据集一共有121类,因此每个节点对应一个121维的向量。
"""supervised_train.py """
G = train_data[0]
features = train_data[1]
id_map = train_data[2] # 每个节点对应的编号
class_map = train_data[4] # labels
为了实现mini-batch SGD,需要将节点划分,下面简单介绍一下minibatch.py
"""supervised_train.py """
minibatch = NodeMinibatchIterator(G,
id_map,
placeholders,
class_map,
num_classes,
batch_size=FLAGS.batch_size,
max_degree=FLAGS.max_degree,
context_pairs=context_pairs)
进入minibatch.py,这个文件主要是实现mini-batch。这里讲一个比较重要的函数construct_adj,函数返回adj、deg,分别是邻接表以及每个顶点的度,adj的shape是(14757,128),这里假设max_degree=128,即adj的每一行是每个顶点的128个邻居,如果顶点邻居不足128个则用有返回抽样补满128个,deg是14757大小的list,存储了每个节点在补齐邻居前实际邻居数。
"""minibatch.py """
def construct_adj(self):
# len(self.id2idx) => 14756 max_degree => 128
adj = len(self.id2idx)*np.ones((len(self.id2idx)+1, self.max_degree))
"""print(adj)
>>> [[14756. 14756. 14756. ... 14756. 14756. 14756.]
[14756. 14756. 14756. ... 14756. 14756. 14756.]
[14756. 14756. 14756. ... 14756. 14756. 14756.]
...
[14756. 14756. 14756. ... 14756. 14756. 14756.]
[14756. 14756. 14756. ... 14756. 14756. 14756.]
[14756. 14756. 14756. ... 14756. 14756. 14756.]]
adj.shape
>>> (14757,128) """
deg = np.zeros((len(self.id2idx),))
for nodeid in self.G.nodes():
# 如果是test/val节点则循环下一个节点
if self.G.node[nodeid]['test'] or self.G.node[nodeid]['val']:
continue
""" 获取nodeid的邻居集合 val/test节点不被包括在内
neighbors = []
for neighbor in self.G.neighbors(nodeid):
if not self.G[nodeid][neighbor]['train_removed']:
neighbors.append(self.id2idx[neighbor])
neighbors=np.array(neighbors)"""
neighbors = np.array([self.id2idx[neighbor]
for neighbor in self.G.neighbors(nodeid)
if (not self.G[nodeid][neighbor]['train_removed'])])
deg[self.id2idx[nodeid]] = len(neighbors) # nodeid的度
if len(neighbors) == 0:
continue
"""若度大于maxdegree 则无放回抽样max_degree个节点,否则有放回抽样max_degree个节点
保证邻居个数相同. """
if len(neighbors) > self.max_degree:
neighbors = np.random.choice(
neighbors, self.max_degree, replace=False)
elif len(neighbors) < self.max_degree:
neighbors = np.random.choice(
neighbors, self.max_degree, replace=True)
adj[self.id2idx[nodeid], :] = neighbors # nodeid的邻居为neighbors
"""adj:第i行是顶点i的max_degree个邻居的编号 就是一个邻接表
deg: 第i个元素是顶点i的度 """
return adj, deg
我们只需知道上面是划分batch并且得到了邻接表adj和度deg,回到上一层supervised_train.py,假设使用graphsage_mean则进入第一个if,并且假设samples_1=25,samples_2=10。首先构造一个邻居采样器sampler(只是定义了,并没开始采样),layer_infos是一个列表包含每一层的信息,列表中每个位置是一个自定义的元组,元组包含四个信息,每一层的名字、采样器、邻居采样个数(第一层是25,第二层是10)、输出维度。
"""supervised_train.py """
if FLAGS.model == 'graphsage_mean':
# Create model
sampler = UniformNeighborSampler(adj_info)
"""samples_1,2,3分别是三层GCN的采用个数,其中samples_3只有mean_model才有. """
layer_infos = [SAGEInfo("node", sampler,
FLAGS.samples_1, # 25
FLAGS.dim_1),
SAGEInfo("node", sampler,
FLAGS.samples_2, # 10
FLAGS.dim_2)]
接下来看看采样器sampler是如何进行采样的,进入neigh_samplers.py,UniformNeighborSampler继承了Layer,因此只需要重新实现_call()函数即可,再进行采样时输入inputs,它包含两个元素,ids是需要进行邻居采样的节点编号,num_samples是这一层采样的邻居个数,具体如何操作看下面的注释应该十分清楚,最后返回adj_lists的shape是(需要采样的节点个数,num_samples),每一行是每个节点采样得到的num_samples个邻居。
"""neigh_samplers.py """
def _call(self, inputs):
"""sample num_samples个节点邻居. ids是需要进行邻居采样的节点编号. """
ids, num_samples = inputs
"""tf.nn.embedding_lookup: https://vimsky.com/article/4298.html
embedding_lookup函数检索张量的行,类似于对numpy中的数组使用索引.
ids是下标, 即取出adj_info中对应的行 即需要采样节点的邻接表. """
adj_lists = tf.nn.embedding_lookup(self.adj_info, ids)
"""tf.random_shuffle: https://www.cnblogs.com/tsdblogs/p/10405030.html
张量沿着维度0(按行打乱)重新打乱.
例如,一个 3x2 张量可能出现的映射是:
[[1, 2], [[5, 6],
[3, 4], ==> [1, 2],
[5, 6]] [3, 4]]
这里要打乱邻居的顺序,即按列打乱,因此先transpose后再shuffle. """
adj_lists = tf.transpose(tf.random_shuffle(tf.transpose(adj_lists)))
"""函数:tf.slice(inputs, begin, size, name)
作用:从列表、数组、张量等对象中抽取一部分数据
begin和size是两个多维列表,他们共同决定了要抽取的数据的开始和结束位置
begin表示从inputs的哪几个维度上的哪个元素开始抽取
size表示在inputs的各个维度上抽取的元素个数
若begin[]或size[]中出现-1,表示抽取对应维度上的所有元素.
eg.
a = tf.constant([[1, 2, 3],
[4, 5, 6]])
# 从第一个维度(行)的0开始,即第0行开始,第二个维度(列)的0开始,即第0列开始
begin = [0, 0]
# 第一个维度划分大小为2,即两行,第二个维度划分大小为1 即1列
size = [2, 1]
print(tf.slice(a, begin, size))
>>> [[1]
[4]] """
"""这里即所有节点都被划分进来, 取前num_samples列,即num_samples个邻居. """
adj_lists = tf.slice(adj_lists, [0, 0], [-1, num_samples])
# shape(节点个数, num_samples)
return adj_lists
回到supervised_train.py,接下来是构造模型
"""supervised_train.py """
model = SupervisedGraphsage(num_classes,
placeholders,
features,
adj_info,
minibatch.deg,
layer_infos,
model_size=FLAGS.model_size,
sigmoid_loss=FLAGS.sigmoid,
identity_dim=FLAGS.identity_dim,
logging=True)
进入supervised_models.py具体GNN模型如何构造。SupervisedGraphsage继承了SampleAndAggregate模型,往后我们会看SampleAndAggregate中的一些函数,有些函数在Supervise时是不会用到的就先不介绍了,以免太乱。下面是进行参数初始化,比较重要的是self.features,在网上看到了一个解释得比较好的图,贴在下面。另外一个是self.dims,它是一个list,长度比GNN层数多1,每个位置的值代表每一层的输入维度,例如self.dims[0]是features.shape[1],即输入特征的维度,在示例中GNN两层的output_dim都是128,因此self.dims=[50,128,128]。在初始化参数后self.build()进入了模型的构造。
"""supervised_models.py """
''' self.features: https://www.cnblogs.com/shiyublog/p/9879875.html
para: features tf.get_variable()-> identity features
| |
self.features self.embeds --> At least one is not None
\ / --> Concat if both are not None
\ /
\ /
self.features
'''
# 构造self.features
if identity_dim > 0:
self.embeds = tf.get_variable(
"node_embeddings", [adj.get_shape().as_list()[0], identity_dim])
else:
self.embeds = None
if features is None:
if identity_dim == 0:
raise Exception(
"Must have a positive value for identity feature dimension if no input features given.")
self.features = self.embeds
else:
self.features = tf.Variable(tf.constant(
features, dtype=tf.float32), trainable=False)
if not self.embeds is None:
self.features = tf.concat([self.embeds, self.features], axis=1)
self.dims = [
(0 if features is None else features.shape[1]) + identity_dim]
self.dims.extend(
[layer_infos[i].output_dim for i in range(len(layer_infos))])
self.build()
注意这里重写了SampleAndAggregate中的bulid()方法,所以我们只看这里的build()方法就好了,贸然去看SampleAndAggregate里的build()方法会有点懵。这里构造了GNN模型,首先是利用self.sample对self.inputs1(即需要嵌入的batch)进行邻居采样,也即调用了父类中的sample方法进行采样(等会会介绍),采样结果samples1是一个list,长度是GNN层数加1,例如一个2层的GNN,则samples1[0]是需要嵌入的batch节点,samples1[1]是根据batch进行采样的邻居节点,samples1[2]是根据samples1[1]中节点进行采样的邻居节点,support_sizes1也是一个list,长度是GNN层数加1,它包含了每一个节点在每一层需要的邻居数(邻域扩张),如果不懂没关系,下文讲sample函数是会详细介绍。num_samples是一个list,长度是GNN层数,例如对于2层GNN,num_samples =[25,10],往下是根据采样得到的samples1等信息进行邻域聚合,聚合后得到batch中每个节点的嵌入self.outputs1,然后进行l2_normalize,最后再加一个全连接层(Dense),输出维度是类标个数50,往后是loss等等一些不太重要的东西…
def build(self):
"""self.inputs1即需要嵌入的batch
samples1[0]=self.inputs1 即最后一层需要嵌入的batch
samples1[1]是根据batch采样的邻居 所以samples1是一个包含了每一层采样结果的list
support_sizes1是一个包含了 `每一层与下一层累计的节点总数(由于邻域扩张,所以是乘以下一层)` 的list """
samples1, support_sizes1 = self.sample(self.inputs1, self.layer_infos)
"""num_samples包含了每一层采样的邻居个数 """
num_samples = [
layer_info.num_samples for layer_info in self.layer_infos]
self.outputs1, self.aggregators = self.aggregate(samples1,
[self.features],
self.dims,
num_samples,
support_sizes1,
concat=self.concat,
model_size=self.model_size)
dim_mult = 2 if self.concat else 1
self.outputs1 = tf.nn.l2_normalize(self.outputs1, 1)
dim_mult = 2 if self.concat else 1
# 最后再加一个全连接层
self.node_pred = layers.Dense(dim_mult*self.dims[-1],
self.num_classes,
dropout=self.placeholders['dropout'],
act=lambda x: x)
# TF graph management
self.node_preds = self.node_pred(self.outputs1)
self._loss()
grads_and_vars = self.optimizer.compute_gradients(self.loss)
clipped_grads_and_vars = [(tf.clip_by_value(grad, -5.0, 5.0) if grad is not None else None, var)
for grad, var in grads_and_vars]
self.grad, _ = clipped_grads_and_vars[0]
self.opt_op = self.optimizer.apply_gradients(clipped_grads_and_vars)
self.preds = self.predict()
接下来讲GraphSAGE核心的两个操作sample和aggregate函数。
首先是sample函数,进入父类中的sample函数,输入:
- inputs:需要嵌入的batch节点编号
- layer_infos:每一层的信息,实际会用到采样器、采样邻居数目两个重要信息
每一层的采样器用到neigh_samplers.py中UniformNeighborSampler的_call方法进行邻居采样,上面已经介绍了如何采样,sample函数返回samples, support_sizes,用一张图来解释这个采样过程。
"""models.py """
def sample(self, inputs, layer_infos, batch_size=None):
""" Sample neighbors to be the supportive fields for multi-layer convolutions.
Args:
inputs: batch inputs
batch_size: the number of inputs (different for batch inputs and negative samples).
"""
"""读懂这部分代码需要理解论文中算法2的采样思想, 它是递归采样的 即从最后一层开始根据inputs采样,
第i-1层根据第i层采样到的节点进行采样. """
if batch_size is None:
batch_size = self.batch_size
"""inputs是需要嵌入的节点(batch) samples[i]是倒数第i层采样到的节点, samples[0]=inputs就是需要嵌入的节点."""
samples = [inputs]
# size of convolution support at each layer per node
support_size = 1
"""support_sizes[i]是倒数第i层采样的节点个数 support_sizes[0]=1代表inputs不采样,是需要嵌入的一批节点"""
support_sizes = [support_size]
"""len(layer_infos)=2 (2层GNN)
layer_infos[t].num_samples 第t层每个节点采样的邻居数,不足的用放回抽样补齐.
sampler第t层的邻居采样器, 注意samples和support_sizes的顺序和层数是逆序的关系
samples[0]代表最后一层需要嵌入的batch节点. 所以这里是递归采样
最先输入的samples[0]是需要嵌入的batch, layer_infos[1].num_samples是第二层需要采样的邻居节点数(10)
得到的node是一个邻接表,shape是(batch_size,10),每一行代表batch中每个节点的邻居.
随后将其reshape成1维添加到samples中,在下一层就对这些节点的邻居进行采样, 可以看到这是指数级放大的. """
for k in range(len(layer_infos)):
t = len(layer_infos) - k - 1
support_size *= layer_infos[t].num_samples
sampler = layer_infos[t].neigh_sampler
node = sampler((samples[k], layer_infos[t].num_samples))
samples.append(tf.reshape(node, [support_size * batch_size, ]))
support_sizes.append(support_size)
return samples, support_sizes
假设有如下图,橙色节点是当前需要嵌入的batch。

采样过程就是一颗递归树,见下图,假设每一层固定采样的邻居数目都是2,则batch中每一个节点需要support_sizes[1]=2个节点来获得其第一跳邻居的信息(即递归树的第二层),需要support_sizes[2]=4个节点来获取其第二跳邻居的信息(即递归树的第三层)。如果看懂了这个过程应该就明白了GraphSAGE的递归采样思想,且应该能看懂以上代码了。

接下来是aggregate函数,输入
- samples:采样得到的samples列表
- input_features:输入特征
- dims:列表,存储每一层的输入维度,长度是层数加1,例如[50,128,128]
- num_samples:列表,存储每一层采样的邻居节点的数目,长度是层时,例如[25,10]
- support_sizes:不太好解释是什么意思,看上面吧…
返回聚合结果hidden[0]是batch节点的嵌入向量,aggregators貌似没什么用。下面以2层GNN为例,首先划分每一跳节点的输入特征,得到hidden是一个列表,hidden[0]代表batch节点的输入特征,看下图的递归树应该就能明白。
"""models.py """
def aggregate(self, samples, input_features, dims, num_samples, support_sizes, batch_size=None,
aggregators=None, name=None, concat=False, model_size="small"):
# length: number of layers + 1
"""2层GNN, len(samples)=3
hidden是一个列表, 列表中每一个元素是每一层节点的输入特征.
hidden[0]对应samples[0]即batch的输入特征.
hidden[1]是根据batch采样的邻居节点的特征. """
hidden = [tf.nn.embedding_lookup(
input_features, node_samples) for node_samples in samples]

然后是构造聚合器,aggregator_cls是一个聚合器,例如MeanAggregator,如果是最后一层则不添加非线性函数。
for layer in range(len(num_samples)):
dim_mult = 2 if concat and (layer != 0) else 1
# aggregator at current layer
if layer == len(num_samples) - 1: # last layer
aggregator = self.aggregator_cls(dim_mult*dims[layer], dims[layer+1], act=lambda x: x,
dropout=self.placeholders['dropout'],
name=name, concat=concat, model_size=model_size)
else:
aggregator = self.aggregator_cls(dim_mult*dims[layer], dims[layer+1],
dropout=self.placeholders['dropout'],
name=name, concat=concat, model_size=model_size)
aggregators.append(aggregator)
接着上面构造好当前层的聚合器后进行邻域聚合,对于内层循环的解释在注释中详细分析了。
# hidden representation at current layer for all support nodes that are various hops away
next_hidden = []
# as layer increases, the number of support nodes needed decreases
"""
batch 1 2 3
samples[1] 4 0 5 0 8 6
samples[2] 1 0 2 3 2 2 6 8 3 6 7 0
假设2层GNN,则len(num_samples)=2.假设concat=True
layer=0时即第一层GNN, hop从[0,2):
hop=0时,batch的第一跳邻居将信息传递给batch,即hidden[0]和hidden[1]输入到aggregator中
此时(按照PPT画的图)neigh_dims=(3,2,F1) 即3个batch节点每个batch节点有2个邻居向量(大小为F1)
hop=1时,batch的第二跳邻居将信息传递给batch的第一跳邻居,即hidden[1]和hidden[2]输入到aggregator中
此时neigh_dims=(3x2,2,F2)=(6,2,F2) 即3个batch节点的6邻居节点,每个节点有2个邻居向量(大小为F2)
注意layer=0时,batch还没有获得第二跳邻居的信息.
此时layer=0循环结束, hidden=next_hidden,每个节点更新了其第一跳邻居的信息
layer=1时即第二层GNN, hop从[0,1):
hop=0时,batch的第一跳邻居将信息传递给batch,即hidden[0]和hidden[1]输入到aggregator中
neigh_dims同上(3,2,F1),此时hidden[0]包含了layer=0时第一跳的信息,
hidden[1]则包含了batch的第二跳邻居的信息,聚合后batch就收集了第一跳邻居和第二跳邻居的信息了.
最后hidden[0]就是收集了第一跳邻居和第二跳邻居信息的batch节点的向量,即batch的output """
for hop in range(len(num_samples) - layer):
dim_mult = 2 if concat and (layer != 0) else 1 # 第一层不需要concat
neigh_dims = [batch_size * support_sizes[hop],
num_samples[len(num_samples) - hop - 1],
dim_mult*dims[layer]]
"""传给_call(inputs): hidden[hop]是self_vecs(batch), hidden[hop+1]是neigh_vecs(batch的邻居节点). """
h = aggregator((hidden[hop],
tf.reshape(hidden[hop + 1], neigh_dims)))
next_hidden.append(h)
hidden = next_hidden
接着我们来简单看看聚合器是如何聚合的,以MeanAggregator为例,打开aggregators.py文件,我们只需关系_call()函数是如何实现的。inputs包含两个元素,self_vecs和neigh_vecs,self_vecs是中心节点的向量,neigh_vecs是它们的邻居节点向量,且是一个三维的tensor,假设中心节点数量是N,该层每个节点的采样邻居数是S,特征大小是F,则neigh_vecs的shape是(N,S,F),即每个中心节点有S个邻居,每个邻居的向量大小是F,往下看代码就能理解了。
def _call(self, inputs):
"""self_vecs: h_v^(k-1)
neigh_vecs: h_u(k-1), u in N(v),
self_vecs是一个二维张量(supportsize*batchsize,F)
neigh_vecs是一个三维张量(supportsize*batchsize,第i层采样邻居数目,F)
先对neigh_vecs求平均得到neigh_means=(supportsize*batchsize,F)
然后concat或add self_vecs,neigh_means """
self_vecs, neigh_vecs = inputs
neigh_vecs = tf.nn.dropout(neigh_vecs, 1-self.dropout)
self_vecs = tf.nn.dropout(self_vecs, 1-self.dropout)
"""neigh_means是一个三维张量,看以下例子
x = tf.Variable([
[[1, 2],
[1, 2]],
[[4, 5],
[4, 5]],
[[7, 8],
[7, 8]]], dtype=tf.float32)
y = tf.reduce_mean(x, axis=1)
print(y)
>>> tf.Tensor([[1. 2.]
[4. 5.]
[7. 8.]], shape=(3, 2), dtype=float32)
"""
neigh_means = tf.reduce_mean(
neigh_vecs, axis=1) # shape(supportsize*batchsize,F)
# [nodes] x [out_dim]
from_neighs = tf.matmul(neigh_means, self.vars['neigh_weights'])
from_self = tf.matmul(self_vecs, self.vars["self_weights"])
if not self.concat:
output = tf.add_n([from_self, from_neighs])
else:
output = tf.concat([from_self, from_neighs], axis=1)
# bias
if self.bias:
output += self.vars['bias']
return self.act(output)
----------------------------------------------------------------------------------------------------------------------------------
以上是个人认为一些比较重要的方法,最后贴上load_data的注释。错误之处还请不吝指出。
def load_data(prefix, normalize=True, load_walks=False):
"""load graph. ./example_data/toy-ppi """
G_data = json.load(open(prefix + "-G.json"))
# type(G):