GCN推导
GCN涉及到的理论比较多,包括信号分析中的傅里叶变换、图谱等理论,这里只做一个简单的推导,旨在让读者了解GCN推导的大致思路以及其中用到的定理,错误之处还请指出。大致了解GCN的思路后可移步学习其中涉及到的理论知识:
- 如何理解图卷积
- 图卷积网络 GCN Graph Convolutional Network
由于图是不规则化的非欧式结构数据,而CNN是在欧式数据(如图片、语音等)上进行卷积,如何在不规则的图上定义卷积?我们从卷积定理入手。
卷积定理
卷积定理:函数卷积的傅里叶变换是函数傅立叶变换的乘积
这个定理十分关键,假设有两个函数 f f f和 g g g, F F F代表傅里叶变换, F ( − 1 ) F^{(-1)} F(−1)为傅里叶逆变换, f ∗ g f*g f∗g为函数 f f f与 g g g的卷积,则根据卷积定理
F ( f ∗ g ) = F ( f ) ⋅ F ( g ) ⇒ f ∗ g = F ( − 1 ) { F ( f ) ⋅ F ( g ) } F(f*g)=F(f)\cdot F(g)⇒f*g=F^{(-1)}\{ F(f)\cdot F(g)\} F(f∗g)=F(f)⋅F(g)⇒f∗g=F(−1){F(f)⋅F(g)}
这表明卷积运算可以拆分为:傅里叶变换、傅里叶逆变换、乘积,乘积运算很简单,所以在图上定义卷积的关键是 如何定义图的傅里叶变换和傅里叶逆变换。
图的傅里叶变换
参考自傅里叶分析(强烈推荐)
傅里叶变换的简单理解(有点上升到哲学)
- 时域:我们所处的真实世界,以时间作为参照来观察动态的世界。
- 频域:“世界是永恒不变的”,世界是静止的。
傅里叶变换就是将函数从时域变换到频域中。很多在时域看似不可能做到的数学操作在频域反而很容易,例如卷积定理,在时域中卷积比较困难,但是通过傅里叶变换到频域中就只需要做一个简单的乘积操作,再将结果傅里叶逆变换回来就可以得到时域中的卷积。
传统的傅里叶变换定义为:
F ( w ) = F [ f ( x ) ] = ∫ f ( x ) e ( − i w x ) d x F(w)=F[f(x)]=∫f(x)e^{(-iwx)} dx F(w)=F[f(x)]=∫f(x)e(−iwx)dx
其中 w w w是频率,而傅里叶的逆变换为:
f ( x ) = ∫ F ( w ) e i w x d w f(x)=∫F(w)e^{iwx} dw f(x)=∫F(w)eiwxdw
可以看到对函数(在信号分析中又称为信号) f ( x ) f(x) f(x)的傅里叶变换本质上就是将 f ( x ) f(x) f(x)映射到以 e ( − i w x ) e^{(-iwx)} e(−iwx)为基向量的空间中。所以在图上定义傅里叶变换的关键是找到一组傅里叶变换的基,研究GSP(graph signal processing)的学者首先定义了图上的傅里叶变换,他们将传统傅里叶变换的基 e ( − i w x ) e^{(-iwx)} e(−iwx)变为图的拉普拉斯矩阵L的特征向量。
为什么会找拉普拉斯矩阵?因为 e ( − i w x ) e^{(-iwx)} e(−iwx)实际上是拉普拉斯算子 Δ Δ Δ的特征函数,对 x x x求二阶导有
Δ e ( − i w x ) = ∂ 2 ∂ x 2 e ( − i w x ) = − w 2 e ( − i w x ) Δe^{(-iwx)}=\frac{∂^2}{∂x^2} e^{(-iwx)}=-w^2 e^{(-iwx)} Δe(−iwx)=∂x2∂2e(−iwx)=−w2e(−iwx)
可见 e ( − i w x ) e^{(-iwx)} e(−iwx)是拉普拉斯算子 Δ Δ Δ的特征函数, w w w与特征值密切相关。所以学者便将 e ( − i w x ) e^{(-iwx)} e(−iwx)与图的拉普拉斯矩阵联系在一起(图拉普拉斯矩阵实际上是离散的拉普拉斯算子),并将拉普拉斯矩阵的特征向量作为图傅里叶变换的基,特征值对应频率w。假设拉普拉斯矩阵为 L L L(定义下一小节介绍),其特征分解为 L = U Λ U − 1 = U Λ U T L=UΛU^{-1}=UΛU^T L=UΛU−1=UΛUT(这里 U U U是正交矩阵,所以后面的等号成立), U = ( u 1 , u 2 , … , u n ) U=(u_1,u_2,…,u_n) U=(u1,u2,…,un), u l u_l ul是 L L L的第 l l l个特征向量, Λ = d i a g ( λ 1 , . . . , λ N ) Λ=diag(λ_1,...,λ_N) Λ=diag(λ1,...,λN)是特征值组成的对角矩阵。仿照传统傅里叶变换,图上的傅里叶变换定义为:
F ( λ l ) = ∑ i = 1 N f ( i ) u l ( i ) F(λ_l )=\sum_{i=1}^Nf(i)u_l (i) F(λl)=i=1∑Nf(i)ul(i)
u l ( i ) u_l (i) ul(i)代表 L L L第 l l l个特征向量的第 i i i个分量,进一步将其写为矩阵的形式:
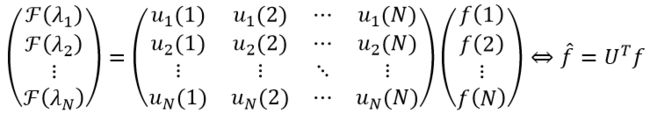
图的傅里叶逆变换为:
f = U f ^ f=U\hat{f} f=Uf^
图拉普拉斯矩阵
图的拉普拉斯矩阵 L = D − A L=D-A L=D−A,拉普拉斯矩阵的定义有几种,这是其中一种比较普遍的定义, D D D是顶点的度对角矩阵, A A A是图的邻接矩阵,拉普拉斯矩阵的定义只针对无向图,因此 L L L是一个实对称矩阵,对其进行特征分解得到的矩阵 U U U是正交的,所以它具备一组线性无关的正交基,因此可以作为傅里叶变换的基,还有很多其它性质,这里不详细介绍。
图卷积
以上分析得到两个重要结论:
- 卷积定理表明卷积运算可以拆分为傅里叶变换、傅里叶逆变换、乘积三个操作: f ∗ g = F − 1 { F ( f ) ⋅ F ( g ) } f*g=F^{-1}\{ F(f)\cdot F(g)\} f∗g=F−1{F(f)⋅F(g)}
- 傅里叶变换分析得出图上的傅里叶变换定义为 f ^ = U T f \hat{f} =U^Tf f^=UTf,傅里叶逆变换为 f = U f ^ f=U\hat{f} f=Uf^。
综上可得图卷积的定义为:
( f ∗ g ) G = U ( ( U T g ) ⋅ ( U T f ) ) (f*g)_G=U((U^T g)\cdot (U^T f)) (f∗g)G=U((UTg)⋅(UTf))
其中 f f f是节点输入特征, g g g是卷积核。因为 U T g U^T g UTg和 U T f U^Tf UTf都是一个向量,因此也可以将其写为

g ^ ( λ i ) \hat{g}(λ_i) g^(λi)是 U T g U^Tg UTg中的第 i i i个分量,两种写法是等价的。
深度学习中图卷积的三个重要演变过程
深度学习中的卷积就是要设计可以训练的卷积核,下面介绍3篇引用量很高的论文对图卷积的改进。
(1) Spectral Networks and Locally Connected Networks on Graphs. ICLR 2014
这篇文章第一次提出谱卷积神经网络,它直接将 g θ g_{θ} gθ作为可训练的卷积核:
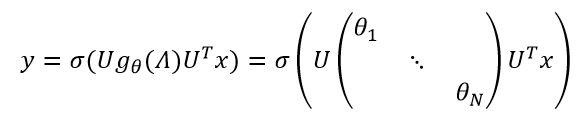
θ ∈ R N θ∈R^N θ∈RN是可训练参数, σ σ σ是非线性激活函数, x x x是顶点的特征向量。
缺点:计算量很大,每一次传播都需要计算 U g θ ( Λ ) U T Ug_θ (Λ)U^T Ugθ(Λ)UT三个矩阵的乘积,对于大图而言不可行,且特征分解耗时;另外有 N N N个参数,参数规模和图节点的规模一样多。
(2) Convolutional neural networks on graphs with fast localized spectral filtering. NIPS 2016
这篇文章(简称ChebNet)针对上述缺点巧妙设计了多项式卷积核:
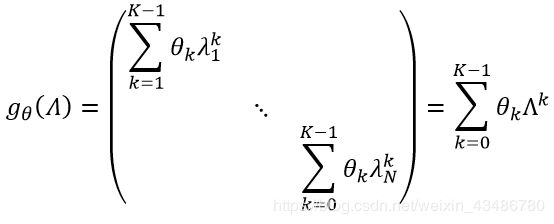
进而图卷积可写为:

可以发现现在参数只有K个,与节点个数N独立,参数的复杂度大大降低,且不需要对拉普拉斯矩阵进行特征分解。由于还要计算 L k L^k Lk,时间复杂度还是很高,因此作者用切比雪夫多项式(Chebyshev polynomial,这也是为什么称为ChebNet)对 L k L^k Lk进行 k k k阶截断拟合,切比雪夫多项式的递归定义为: T k ( x ) = 2 x T k − 1 ( x ) − T k − 2 ( x ) , T 0 = 1 , T 1 = x T_k (x)=2xT_{k-1}(x)-T_{k-2}(x) ,T_0=1 ,T_1=x Tk(x)=2xTk−1(x)−Tk−2(x),T0=1,T1=x且 x ∈ [ − 1 , 1 ] x∈[-1,1] x∈[−1,1]。首先将L缩放到 [ − 1 , 1 ] [-1,1] [−1,1]之间,得规范化拉普拉斯矩阵 L ~ = 2 L λ m a x − I n \widetilde{L}=\frac{2L}{λ_{max}} -I_n L =λmax2L−In,则:
x ∗ g θ = ∑ k = 0 K − 1 θ k L k x ≈ ∑ k = 0 K − 1 θ k T k ( L ~ ) x x*g_θ=∑_{k=0}^{K-1}θ_kL^kx≈∑_{k=0}^{K-1}θ_kT_k (\widetilde{L}) x x∗gθ=k=0∑K−1θkLkx≈k=0∑K−1θkTk(L )x
其中 T 0 ( L ~ ) = I n , T 1 ( L ~ ) = L ~ = 2 L λ m a x − I n n T_0 (\widetilde{L})=I_n,T_1 (\widetilde{L})=\widetilde{L}=\frac{2L}{λ_{max}} -I_nn T0(L )=In,T1(L )=L =λmax2L−Inn。
(3) GCN Semi-supervised classification with graph convolutional networks. ICLR 2017
这篇文章是引用量最高的一篇,它使用对称归一化的拉普拉斯矩阵 L = I n − D − 1 / 2 A D − 1 / 2 L=I_n-D^{-1/2} AD^{-1/2} L=In−D−1/2AD−1/2,并对ChebNet进行化简,令 K = 2 , λ m a x = 2 K=2,λ_{max}=2 K=2,λmax=2,则ChebNet变为:

为了防止过拟合,作者简化参数,令 θ = θ 0 = − θ 1 θ=θ_0=-θ_1 θ=θ0=−θ1,得:
x ∗ g θ = θ ( I n + D − 1 / 2 A D − 1 / 2 ) x x*g_θ=θ(I_n+D^{-1/2}AD^{-1/2})x x∗gθ=θ(In+D−1/2AD−1/2)x
另外由于 I n + D − 1 / 2 A D − 1 / 2 I_n+D^{-1/2} AD^{-1/2} In+D−1/2AD−1/2的特征值在 [ 0 , 2 ] [0, 2] [0,2]之间,重复叠加可能导致数值不稳定和梯度消失或爆炸,因此作者将其重整化为 I n + D − 1 / 2 A D − 1 / 2 → D ~ − 1 / 2 A D ~ − 1 / 2 I_n+D^{-1/2}AD^{-1/2}→\widetilde{D}^{-1/2} A\widetilde{D}^{-1/2} In+D−1/2AD−1/2→D −1/2AD −1/2,其中 A ~ = A + I n , D ~ i i = ∑ j A ~ i j \widetilde{A} =A+I_n,\widetilde{D}_{ii}=∑_j\widetilde{A}_{ij} A =A+In,D ii=∑jA ij 。最后就导出GCN的快速传播公式:
H ( k ) = σ ( A ^ H ( k − 1 ) W ( k ) ) H^{(k)}=σ(\hat{A} H^{(k-1)}W^{(k)}) H(k)=σ(A^H(k−1)W(k))
H ( k − 1 ) H^{(k-1)} H(k−1)是第k-1层的输出, W ( k ) W^{(k)} W(k)是第k层的卷积核, A ^ = D ~ − 1 / 2 A ~ D ~ − 1 / 2 \hat{A}=\widetilde{D}^{-1/2}\widetilde{A}\widetilde{D}^{-1/2} A^=D −1/2A D −1/2。