2. 正则表达式---提取字符串
2. 正则表达式—提取字符串
标签(空格分隔): 4.5python爬虫
regular expression 正则表达
导入正则函数
import re
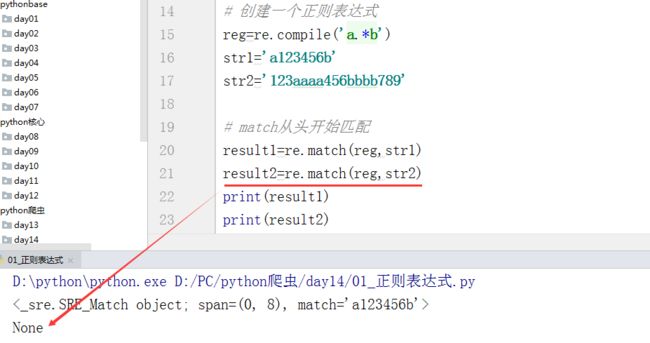
创建一个正则表达式
reg=re.compile(‘a.*b’)
str1=‘a123456b’
str2=‘123aaaa456bbbb789’
1. match—从头开始匹配
result1=re.match(reg,str1)
result2=re.match(reg,str2)
print(result1) # 输出的内容还是一个对象
print(result2) # 没有内容
2. search—寻找,返回找到的结果
reg=re.compile(‘a.*b$’)
str1=‘a123456b’
str2=‘123aaaa456bbbb789’
result1=re.search(reg,str1)
result2=re.search(reg,str2) #有^ / $ 时 None
print(result1)
print(result2)

^ 查找以什么为开头的
$ 查找以什么为结尾的
3. . (贪婪模式) 和 .*? (非贪婪模式)*
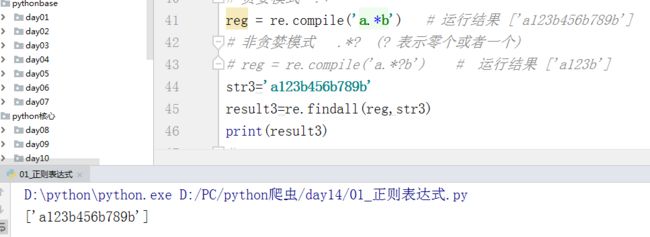
(1) 贪婪模式 .*
reg = re.compile(‘a.*b’) # 运行结果 [‘a123b456b789b’]
(2) 非贪婪模式 .*?
? 表示零个或者一个
reg = re.compile(‘a.*?b’) # 运行结果 [‘a123b’]
str3=‘a123b456b789b’
result3=re.findall(reg,str3)
print(result3)

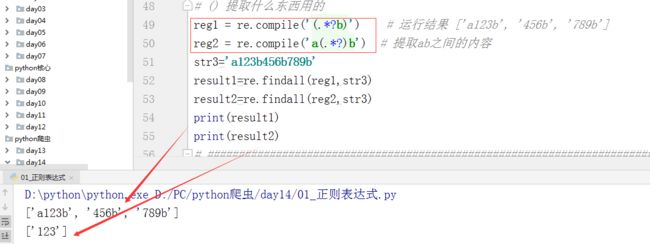
4. () 内为要提取的内容
reg1 = re.compile(’(.?b)’) # 提取b 之前的内容
reg2 = re.compile('a(.?)b’) # 提取ab之间的内容
str3=‘a123b456b789b’
result1=re.findall(reg1,str3)
result2=re.findall(reg2,str3)
print(result1)
print(result2)
5. sub 和 subn 替换
str5 = ‘a123’
print(str5.replace(‘a’,‘A’)) # A123
(1) re.sub
语法: re.sub (正则表达式,替换为什么,替换对象,替换次数(默认全部))
reg1 = re.compile(’[a-zA-Z]+’)
result5=re.sub(reg1,’,’,str5)
result5=re.sub(reg1,’,’,str5,2)
print(result5)
(2) re.subn
语法: re.subn (正则表达式,替换为什么,替换对象)
- re.subn 返回值是元组(替换后的字符串,替换的次数)
result6=re.subn(reg1,’,’,str5)
print(result6)

6. 提取中文 [\u4E00-\u9FA5]
reg = re.compile(’[\u4E00-\u9FA5]+’)
strang=‘张三:20,李四:22,王五:25’
result = re.findall(reg,strang)
print(result)

7. 正则表达式提取总结
总结:正则表达式
目的: 按照 指定的规则 从 字符串 中提取内容
指定的规则: 变量 reg = re.compile(‘字符串’,[匹配模式])
匹配模式: re.I 忽略大小写 re.S 让 . 可以匹配换行\n
字符串: 已有的str
提取内容:使用正则的方法
re.match(reg,str)
re.search(reg,str)
re.split(reg,str)
re.findall(reg,str) 返回list
re.sub(reg,str)
re.subn(reg,str)

8. 练习题
(1). 提取is|IS(不分大小写)
import re
str6=‘He is a boy , his name IS Jack.’
reg2 = re.compile(‘is’,re.I) # 方法1
或reg2 = re.compile(‘is|IS’) # 方法2
result7=re.findall(reg2,str6)
print(result7)
问题: 输出结果 [‘is’, ‘is’, ‘IS’] 但第二个is 是单词his 的部分
- \b 单词边界. 想让单词边界生效,要用r’\b’
str6=‘He is a boy , his name IS Jack.’
reg2 = re.compile(r’\bis\b’,re.I)
result7=re.findall(reg2,str6)
print(result7) # 运行结果 [‘is’, ‘IS’]

(2). 提取字符串导演/地区/时间
film = ‘’’
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /…
1994 / 美国 / 犯罪 剧情’’'
- 时间
方法1:
reg3= re.compile(’[0-9]{4}’)
result8=re.findall(reg3,film)
print(result8)
方法2:
reg3= re.compile(’\d{4}’)
print(re.findall(reg3,film))

- 地区
reg4= re.compile(’/(.*?)/’)
result9=re.findall(reg4,film)
print(result9)
方法2:
print(film.split(’/’)[-2])

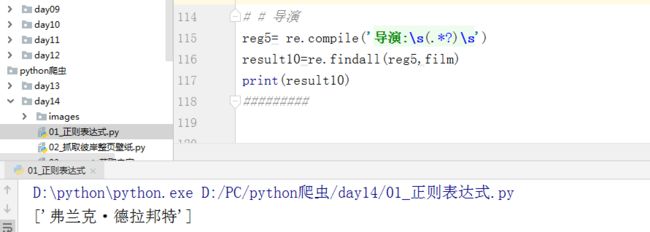
- 导演
reg5= re.compile(‘导演:\s(.*?)\s’)
result10=re.findall(reg5,film)
print(result10)
方法2:
regd = re.compile(‘导演: (.*?) 主演’)
print(re.findall(regd,film))