Hadoop之HDFS
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,用于对海量数据的存储和管理,可以运行于廉价的服务器上,它的出现解决了海量非关系型的数据存储问题。
HDFS的优点
- 支持超大文件:将文件进行切块分别放到不同的节点上
- 检测和快速应对硬件故障:心跳机制
- 流式数据访问
- 简化的一致性模型:只要一个文件块写好,那么这个文件块就不允许在进行改动,只能读取。
- 高容错性:多复本。
- 可构建在廉价机器上:HDFS具有较好的扩展性。
HDFS的缺点
- 高延迟数据访问:不适合于交互式,也就意味着Hadoop不适合做实时分析,而是做的离线分析。
- 大量的小文件:文件的存储要经过namenode,namenode中要记录元数据,元数据是存储在内存中。大量的小文件会产生大量的元数据,导致内存被大量占用,降低namenode的处理效率。
- 多用户写入文件、修改文件:在hadoop2.0版本中,不支持修改,但是支持追加。
- 不支持超强的事务。
HDFS的结构:
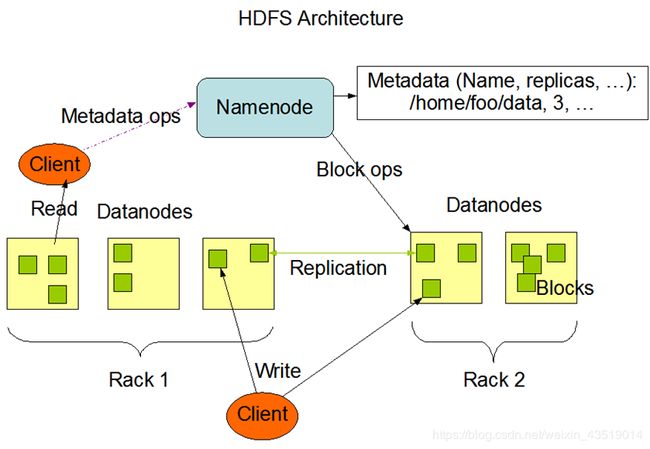
- DataNode: 存储数据的节点 ,并且是以数据块的形式来存储。
1)datanode存储namenode对应的clusterID以确定当前的datanode归哪一个namenode管理
2)datanode每隔一段时间(3s)会主动向namenode发送心跳信息(节点状态,节点数据)
3)如果namenode超过了10min没有收到datanode的心跳,则认为这个datanode产生lost,那么namenode就会将这个datanode上的数据copy到其他节点上。 - NameNode: 管理数据的节点,负责datanode的管理以及存储元数据。
- HDFS存储数据的时候会将文件进行切块,并且给每一个文件块分配一个递增的编号。
- HDFS存储数据的时候会对数据进行备份,每一个备份称之为是一个复本。在伪分布式下,复本设置为1,但是在全分布式下,复本默认是3个。3个复本是放到不同的datanode中,复本放置策略 - -机架感知策略:
1)第一个复本:客户端连接的是哪一个datanode,复本就放到哪一个datanode上。
2)第二个复本:要放到另一个机架的datanode上。
3)第三个复本:放到和第二个复本同机架的另一个datanode上。
4)如果有更多的复本数量,其他的复本随机放到其他的datanode。 - 如果某一个datanode宕机,那么这个时候namenode就会将这个datanode上所存放的复本进行复制,保证整个hdfs中有指定的复本数量。
- namenode需要管理datanode,namenode中存储管理信息 — 元数据 - metadata — FileName replicas block-Ids id2host:
1)记录文件存储位置 /node01/a.txt
2)记录文件切的块数
3)文件块存储的datanode的地址
/test/a.log,3,{b1,b2},[{b1:[h0,h1,h3]},{b2:[h0,h2,h4]}] — 存储的文件时a.log文件,存储在/test路径下,复本数量为3,切了2块,编号为b1,b2,b1存放在h0,h1,h3节点下,b2存放在h0,h2,h4节点下。 - datanode主动向namenode发送心跳,保持namenode对datanode的管理,心跳信息包含:1.节点状态 2.节点存储的数据
- 如果超过10min中,namenode没有收到datanode的心跳,那么就认为这个datanode已经lost,那么namenode就会将这个lost的datanode中的数据进行备份。
- Block : HDFS在存储数据的时候是将数据进行切块,分别存储到不同的节点上。在Hadoop1.0版本中,每一个block默认大小是64M,在Hadoop2.0版本中,每一个block默认大小是128M
例如:存一个400M的文件 - 要分为4块 - 其中前3块每一块是128M,第4块是16M。
一个100M文件 - 文件块按照实际大小100M存储。
文件切块的好处:
1)利于大文件的存储
2)方便传输
3)便于计算 - 之前我们说过NameNode负责datanode的管理以及存储元数据,而元数据存在内存中(快速查询)和磁盘中(崩溃恢复)。所以NameNode的结构又可划分为如下:

fsimage - 存储元数据,但是注意fsimage中的元数据和内存中并不一致,也就意味着fsimage中的数据并不是实时数据。
edits - 存储HDFS的操作。
fstime - 记录上一次的更新时间。
触发更新的条件:
1.文件大小 — 根据配置文件设置的edits log大小: fs.checkpoint.size ,默认64MB
2.定时更新 — 根据配置文件设置的时间间隔:fs.checkpoint.period ,默认3600秒
3.重启hdfs的时候也会触发更新 — 在合并过程中,HDFS不对外提供写服务,只提供读服务 — 重启hdfs的时候进行的更新阶段 — 安全模式
安全模式:
1.只能读不能写
2.检查复本数量以及总量 — 导致伪分布式环境下,复本数量必须设置为1
如果重启hdfs,处于安全模式,等待一会儿,检查完数据都没有问题,自动退出安全模式
重启hdfs之后如果长期处于安全模式中,说明数据有损坏:
1.强制退出安全模式 hadoop dfsadmin -safemode leave
2.关闭HDFS
3.删除dfs、nm-local-dir、logs
4.重新格式化 hadoop namenode -format
注:如果在生产环境下严禁私自重启HDFS,出现问题不懂请找负责人。
SecondaryNameNode
我们在启动HDFS的时候发现还有另一个进程也启动,那就是SecondaryNameNode,那么它是干嘛的呢?是fsimage和edits进行合并的节点。
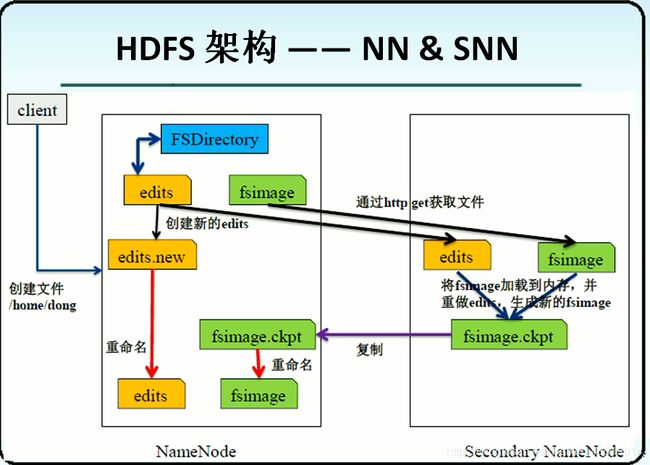
合并过程:
1.将edits和fsimage文件通过网络拷贝到Secondarynamenode上
2.在namenode产生一个edits.new记录合并期间的操作
3.拷贝完成之后,fsimage就会将其中的数据存到secondarynamenode的内存中
4.将edits的操作更新到secondarynamenode的内存中
5.更新完成之后,将内存中的数据写到fsimage.ckpt文件中
6.通过网络将fsimage.ckpt拷贝到namenode中
7.将fsimage.ckpt重命名为fsimage,并且将edits.new也重命名为edits。 - SecondaryNameNode只负责进行数据的合并,不是Namenode的热备,但是也能起到一定的备份作用,只是会产生数据的丢失。
HDFS的操作流程
读取数据
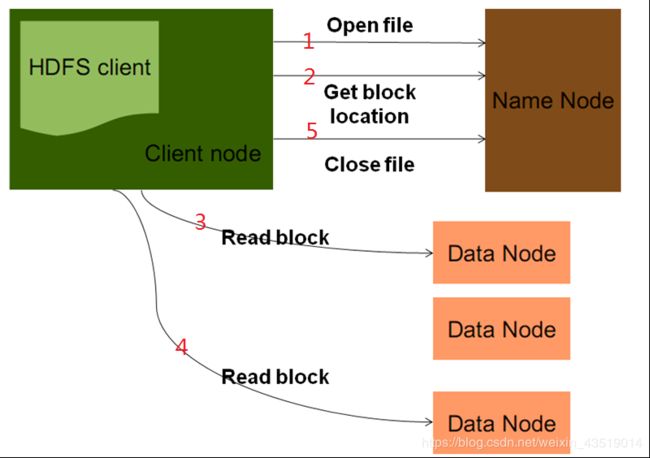
1.客户端发起RPC请求访问Namenode
2.namenode会查询元数据,找到这个文件的存储位置对应的数据块的信息。
3.namenode将文件对应的数据块的节点地址的全部或者部分放入一个队列中然后返回。
4.client收到这个数据块对应的节点地址
5.client会从队列中取出第一个数据块对应的节点地址,会从这些节点地址中选择一个最近的节点进行读取
6.将Block读取之后,对Block进行checksum的验证,如果验证失败,说明数据块产生损坏,那么client会向namenode发送信息说明该节点上的数据块损坏,然后从其他节点中再次读取这个数据块
7.验证成功,则从队列中取出下一个Block的地址,然后继续读取
8.当把这一次的文件块全部读完之后,client会向namenode要下一批block的地址
9.当把文件全部读取完成之后,从client会向namenode发送一个读取完毕的信号,namenode就会关闭对应的文件
写流程
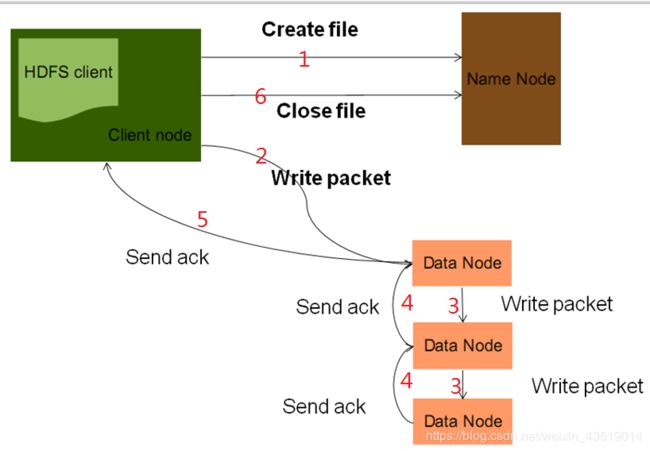
1.client发送RPC请求给namenode
2.namenode接收到请求之后,对请求进行验证,例如这个请求中的文件是否存在,再例如权限验证
3.如果验证通过,namenode确定文件的大小以及分块的数量,确定对应的节点(会去找磁盘空间相对空闲的节点来使用),将节点地址放入队列中返回
4.客户端收到地址之后,从队列中依次取出节点地址,然后数据块依次放入对应的节点地址上
5.客户端在写完之后就会向namenode发送写完数据的信号,namenode会给客户端返回一个关闭文件的信号
6.datanode之间将会通过管道进行自动的备份,保证复本数量
删除流程
1.Client发起RPC请求到namenode
2.namenode收到请求之后,会将这个操作记录到edits中,然后将数据从内存中删掉,给客户端返回一个删除成功的信号
3.客户端收到信号之后认为数据已经删除,实际上数据依然存在datanode上
4.当datanode向namenode发送心跳消息(节点状态,节点数据)的时候,namenode就会检查这个datanode中的节点数据,发现datanode中的节点数据在namenode中的元数据中没有记录,namenode就会做出响应,就会命令对应的datanode删除指定的数据
hdfs的操作指令
hadoop fs -put a.txt /a.txt - 上传文件
hadoop fs -mkdir /hadoopnode01 - 创建目录
hadoop fs -rm /hadoop-2.7.1_64bit.tar.gz - 删除文件
hadoop fs -rmdir /hadoopnode01 - 删除目录
hadoop fs -rmr /a - 递归删除
hadoop fs -get /a.txt /home - 下载
hadoop fs -ls / - 查看
hadoop fs -lsr / - 递归查看
hadoop fs -cat /a.txt - 查看内容
hadoop fs -tail /a.txt - 产看文件的最后1000个字节
hadoop fs -mv /a/a.txt /a/b.txt - 移动或者重命名
hadoop fs -touchz /demo.txt - 创建空文件
hadoop fs -getmerge /a demo.txt - 合并下载
Hadoop插件的使用:
因为我使用的eclipse,所以就以eclipse为示例。。。
1.将前面hadoopbin_for_hadoop2.7.1.zip的安装包解压
2.复制hadoop-eclipse-plugin-2.7.1.jar
3.找到eclipse的安装目录,将插件复制到eclipse安装目录下的子目录plugins中
4.重启eclipse
5.在eclipse中指定hadoop的安装目录

6.Window -show view
7.需要添加环境变量:HADOOP_USER_NAME=用户名
HDFS的API操作(仅作了解,现在基本没人用这些方法了,有了上面的插件,上传和下载文件都非常方便)
下载:
@Test
public void get() throws IOException, URISyntaxException {
// 创建连接
// uri - 连接地址
// conf - 配置
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI(“hdfs://192.168.60.132:9000”), conf);
// 获取读取文件的流
InputStream in = fs.open(new Path("/a/a.txt"));
FileOutputStream out = new FileOutputStream(“a.txt”);
// 读取数据
byte[] bs = new byte[1024];
int len = -1;
while ((len = in.read(bs)) != -1) {
out.write(bs, 0, len);
}
out.close();
}
上传:
@Test
public void put() throws IOException, URISyntaxException, InterruptedException{
// 创建连接
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI(“hdfs://192.168.60.132:9000”), conf, “root”);
OutputStream out = fs.create(new Path("/a/c.txt"));
FileInputStream in = new FileInputStream(“c.txt”);
byte[] bs = new byte[1024];
int len = -1;
while ((len = in.read(bs)) != -1) {
out.write(bs, 0, len);
}
in.close();
}
以上,胡说八道之道请指出,不胜感激!!!