大型电商架构亿级流量电商详情页系统实战-缓存架构+高可用服务架构+微服务架构(七)
文章目录
- 八十九、高并发场景下恐怖的缓存雪崩现象以及导致系统全盘崩溃的后果
- 九十、缓存雪崩的基于事前+事中+事后三个层次的完美解决方案
- 九十一、基于hystrix完成对redis访问的资源隔离以避免缓存服务被拖垮
- 九十二、为redis集群崩溃时的访问失败增加fail silent容错机制
- 九十三、为redis集群崩溃时的场景部署定制化的熔断策略
- 九十四、基于hystrix限流完成源服务的过载保护以避免流量洪峰打死MySQL
- 九十五、为源头服务的限流场景增加stubbed fallback降级机制
- 九十六、高并发场景下的缓存穿透导致MySQL压力倍增问题以及其解决方案
- 九十七、在缓存服务中开发缓存穿透的保护性机制
- 九十八、高并发场景下的nginx缓存失效导致redis压力倍增问题以及解决方案
- 九十九、在nginx lua脚本中开发缓存失效的保护性机制
- 一零零、支撑高并发与高可用的大型电商详情页系统的缓存架构课程总结
八十九、高并发场景下恐怖的缓存雪崩现象以及导致系统全盘崩溃的后果
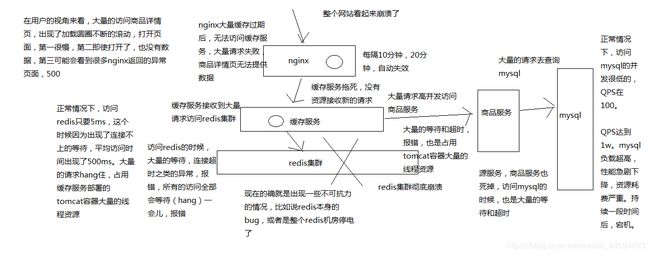
缓存雪崩这种场景,缓存架构中非常重要的一个环节,应对缓存雪崩的解决方案,避免缓存雪崩的时候,造成整个系统崩溃,带来巨大的经济损失
- redis集群彻底崩溃
- 缓存服务大量对redis的请求hang住,占用资源
- 缓存服务大量的请求打到源头服务去查询mysql,直接打死mysql
- 源头服务因为mysql被打死崩溃,对源头服务的请求也hang住,占用资源
- 缓存服务大量的资源全部耗费在访问redis和源服务无果,最后自己被拖死,无法提供服务
- nginx无法访问缓存服务,redis和源服务,只能基于本地缓存提供服务,单缓存过期后,没有数据提供
- 网站崩溃
行业里真实的缓存雪崩的经验和教训
某电商,之前就是出现过,整个缓存的集群彻底崩溃了,因为主要是集群本身的bug,导致自己把自己给弄死了,虽然当时也是部署了双机房的,但是还是死了
电商大量的,几乎所有的应用都是基于那个缓存集群去开发的
导致各种服务的线程资源全部被耗尽,然后用在了访问那个缓存集群时的等待、超时和报错上了
然后导致各种服务就没有资源对外提供服务咯
然后各种降级措施也没做好,直接就是整体系统的全盘崩溃
导致网站就没法对外出售商品咯,导致了很大数额的经济的损失
java架构师,资深java工程师,对自己技术有点要求,多学一些,多思考一些各种场景下的缓存架构,用来解决各种各样的问题
自己做系统架构设计的时候,多留个心眼儿,考虑一下各种高并发场景下可能出现的问题,数据不一致,热点缓存,重建并发冲突,redis高可用性,缓存雪崩, 缓存穿透,缓存失效
架构设计做好一些,稳定性也做好一些
你的系统能够承载各种各样的故障,才能在真正发生故障的时候,减少对公司的损失,保住大家的饭碗
你说你用过redis,系统里面涉及过这种缓存的架构,高并发场景下的各种问题,结合你的业务,怎么去设计整套缓存架构的,跳槽面试的时候,说点牛逼的出来
九十、缓存雪崩的基于事前+事中+事后三个层次的完美解决方案
相对来说,考虑的比较完善的一套方案,分为事前,事中,事后三个层次去思考怎么来应对缓存雪崩的场景
1、事前解决方案
发生缓存雪崩之前,事情之前,怎么去避免redis彻底挂掉
redis本身的高可用性,复制,主从架构,操作主节点,读写,数据同步到从节点,一旦主节点挂掉,从节点跟上
双机房部署,一套redis cluster,部分机器在一个机房,另一部分机器在另外一个机房
还有一种部署方式,两套redis cluster,两套redis cluster之间做一个数据的同步,redis集群是可以搭建成树状的结构的
一旦说单个机房出了故障,至少说另外一个机房还能有些redis实例提供服务
2、事中解决方案
redis cluster已经彻底崩溃了,已经开始大量的访问无法访问到redis了
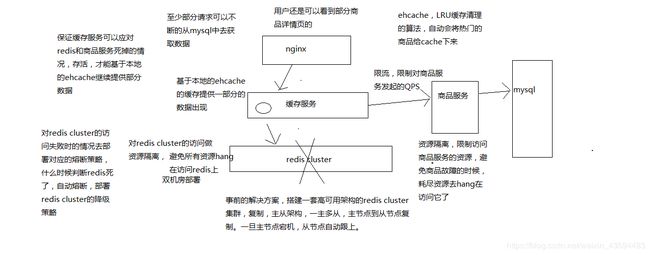
(1)ehcache本地缓存
所做的多级缓存架构的作用上了,ehcache的缓存,应对零散的redis中数据被清除掉的现象,另外一个主要是预防redis彻底崩溃
多台机器上部署的缓存服务实例的内存中,还有一套ehcache的缓存
ehcache的缓存还能支撑一阵
(2)对redis访问的资源隔离
(3)对源服务访问的限流以及资源隔离
3、事后解决方案
(1)redis数据可以恢复,做了备份,redis数据备份和恢复,redis重新启动起来
(2)redis数据彻底丢失了,或者数据过旧,快速缓存预热,redis重新启动起来
redis对外提供服务
缓存服务里,熔断策略,自动可以恢复,half-open,发现redis可以访问了,自动恢复了,自动就继续去访问redis了
基于hystrix的高可用服务这块技术之后,先讲解缓存服务如何设计成高可用的架构
缓存架构应对高并发下的缓存雪崩的解决方案,基于hystrix去做缓存服务的保护
要带着大家去实现的有什么东西?事前和事后不用了吧
事中,ehcache本身也做好了
基于hystrix对redis的访问进行保护,对源服务的访问进行保护,讲解hystrix的时候,也说过对源服务的访问怎么怎么进行这种高可用的保护
但是站的角度不同,源服务如果自己本身不知道什么原因出了故障,我们怎么去保护,调用商品服务的接口大量的报错、超时
限流,资源隔离,降级
九十一、基于hystrix完成对redis访问的资源隔离以避免缓存服务被拖垮
这一讲开始,用几讲的时间,给咱们的redis的访问这一块,加上保护措施,给商品服务的访问加上限流的保护措施(重复,之前已经)
redis这一块,全都用hystrix的command进行封装,做资源隔离,确保说,redis的访问只能在固定的线程池内的资源来进行访问
哪怕是redis访问的很慢,有等待和超时,也不要紧,只有少量额线程资源用来访问,缓存服务不会被拖垮
九十二、为redis集群崩溃时的访问失败增加fail silent容错机制
上一节课,我们已经通过hystrix command对redis的访问进行了资源隔离
资源隔离,避免说redis访问频繁失败,或者频繁超时的时候,耗尽大量的tomcat容器的资源去hang在redis的访问上
限定只有一部分线程资源可以用来访问redis
你是不是说,如果redis集群彻底崩溃了,这个时候,可能command对redis的访问大量的报错和timeout超时,熔断(短路)
降级机制,fallback
fail silent模式,fallback里面直接返回一个空值,比如一个null,最简单了
在外面调用redis的代码(CacheService类),是感知不到redis的访问异常的,只要你把timeout、熔断、熔断恢复、降级,都做好了
可能会出现的情况是,当redis集群崩溃的时候,CacheService获取到的是大量的null空值
根据这个null空值,我们还可以去做多级缓存的降级访问,nginx本地缓存,redis分布式集群缓存,ehcache本地缓存,CacheController
九十三、为redis集群崩溃时的场景部署定制化的熔断策略
缓存雪崩的解决方案,事中,发生缓存雪崩的时候,解决方案
redis集群崩溃的时候,会怎么样?
(1)首先大量的等待,超时,报错
(2)如果是短时间内报错,会直接走fallback降级,直接返回null
(3)超时控制,你应该判断说redis访问超过了多长时间,就直接给timeout掉了
不推荐说用默认的值,一般不太精准,redis的访问你首先自己先统计一下访问时长的百分比,hystrix dashboard,TP90 TP95 TP99
一般来说,redis访问,假设说TP99在100ms,那么此时,你的timeout稍微多给一些,100ms
1、timeout超时控制
HystrixCommandProperties.Setter()
.withExecutionTimeoutInMilliseconds(int value)
意义在于哪里,一旦说redis出现了大面积的故障,此时肯定是访问的时候大量的超过100ms,大量的在等待和超时
就可以确保说,大量的请求不会hang住过长的时间,比如说hang住个1s,500ms,100ms直接就报timeout,走fallback降级了
2、熔断策略
(1)circuitBreaker.requestVolumeThreshold
设置一个rolling window,滑动窗口中,最少要有多少个请求时,才触发开启短路
举例来说,如果设置为20(默认值),那么在一个10秒的滑动窗口内,如果只有19个请求,即使这19个请求都是异常的,也是不会触发开启短路器的
HystrixCommandProperties.Setter()
.withCircuitBreakerRequestVolumeThreshold(int value)
我们应该根据我们自己的平时的访问流量去设置,而不是用默认值,比如说,我们认为平时一般的时候,流量也可以在每秒在QPS 100,10秒的滑动窗口就是1000
一般来说,你可以设置这样的一个值,根据你自己的系统的流量去设置
假如说,你设置的太少了,或者太多了,都不太合适
举个例子,你设置一个20,结果在晚上最低峰的时候,刚好是30,可能晚上的时候因为访问不频繁,大量的找不到缓存,可能超时频繁了一些,结果直接就给短路了
(2)circuitBreaker.errorThresholdPercentage
设置异常请求量的百分比,当异常请求达到这个百分比时,就触发打开短路器,默认是50,也就是50%
HystrixCommandProperties.Setter()
.withCircuitBreakerErrorThresholdPercentage(int value)
我们最好还是自己定制,自己设置,你说如果是要50%的时候才短路的话,会有什么情况呢,10%短路,也不太靠谱,90%异常,才短路
我觉得这个值可以稍微高一些,redis集群彻底崩溃,那么基本上就是所有的请求,100%都会异常,60%,70%
也有可能偶然出现网络的抖动,导致比如说就这10秒钟,访问延时高了一些,其实可能并不需要立即就短路,可能下10秒马上就恢复了
金融支付类的接口,可能这个比例就会设置的很低,因为对异常系统必须要很敏感,可能就是10%异常了,就直接短路了,不让继续访问了
比如金融支付类的接口,正常来说,是很重要的,而且必须是很稳定,我们不能容忍任何的延迟或者是报错
一旦支付类的接口,有10%的异常的话,我们基本就可以认为这个接口已经出问题了,再继续访问的话,也许访问的就是有问题的接口,可能造成资金的错乱,等给公司造成损失
熔断,不让访问了,走降级策略
就是对整个系统,是一个安全性的保障
(3)circuitBreaker.sleepWindowInMilliseconds
设置在短路之后,需要在多长时间内直接reject请求,然后在这段时间之后,再重新导holf-open状态,尝试允许请求通过以及自动恢复,默认值是5000毫秒
HystrixCommandProperties.Setter()
.withCircuitBreakerSleepWindowInMilliseconds(int value)
如果redis集群崩溃了,会在5s内就直接恢复,1分钟
public GetProductInfoFromRedisCommand(Long productId) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("RedisGroup"))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withExecutionTimeoutInMilliseconds(100) //超时时间 100ms
.withCircuitBreakerRequestVolumeThreshold(100) //10秒的滑动窗口有100个异常
.withCircuitBreakerErrorThresholdPercentage(70) //异常百分比
.withCircuitBreakerSleepWindowInMilliseconds(60 * 1000))); //恢复时间
this.productId = productId;
}
九十四、基于hystrix限流完成源服务的过载保护以避免流量洪峰打死MySQL
redis集群彻底崩溃的时候,一个是对redis本身做资源隔离、超时控制、熔断策略
大量的请求,高并发会去访问源服务,商品服务(提供商品数据),QPS 10000去访问商品服务,基于mysql去查询
QPS 10000去访问mysql,会怎么样,mysql打死,商品服务也会死掉
就是要对商品服务这种源服务的访问施加限流的措施
限流怎么限,hystrix本身就是提供了两种机制,线程池(内部做了异步化处理,可以处理超时),semaphore(信号量,让tomcat线程执行运行逻辑,没有内部的异步化处理,一旦超时,会导致tomcat线程就hang住了)
一般推荐的是,线程池用来做有网络访问的这种资源隔离,因为涉及到网络,就很容易超时;sempahore是用来做对服务纯内存的一些复杂业务逻辑的操作,进行限流,因为不涉及网络访问,就是纯粹为了避免说对内存内的复杂业务逻辑进行太高并发的访问,造成系统本身的故障
semaphore是很合适的,比如一些推荐、搜索,有部分算法,复杂的算法,是放在服务内部纯内存去运行的,一个服务暴露出来的就是某个算法的执行
这个时候,就很适合用semaphore
访问外部的商品服务,所以还是用线程池做限流了。。。
算一下,要限多少,怎么限
假设说,每次商品服务的访问性能在200ms,1个线程一秒可以执行5次访问,假设说我们一个缓存服务实例对这个商品服务的访问每秒在150次
所以这个时候,我们就需要30个线程,每个线程每秒可以访问5次,总共每秒30个线程可以访问150次
这个时候呢,我们限流,要做得事情是这样子的,我们算的这个每秒150次访问时正常情况下,如果是非正常情况下,每秒1000次,甚至1w次,此时就可以自然限流
因为我们的线程池就30个。。。,还要设置等待队列
非正常情况下,直接线程池+等待队列全满,此时就会会出现大量的reject操作,然后就会去调用降级逻辑
接下来,我们要做限流,设置的就是线程池的大小,还有等待队列的大小,30个线程可以每秒处理150个请求,但是偶尔会多一些出来,同时30个线程处理150个请求会快一些,不用花费1秒钟,等待队列给一些buffer,不要偶尔1秒钟来了200条请求,50条直接给reject掉,等待队列,150个,30个线程直接500ms处理完了,等待队列中的50个请求可以继续处理
public ProductInfoCommand(Long productId) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ProductInfoService"))
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter()
.withCoreSize(10) //线程数
.withMaximumSize(30) //最大线程数
.withAllowMaximumSizeToDivergeFromCoreSize(true) //动态变化
.withKeepAliveTimeMinutes(1) //空闲线程存活时间(1分钟)
.withMaxQueueSize(50) //等待队列
.withQueueSizeRejectionThreshold(100)));
this.productId = productId;
}
九十五、为源头服务的限流场景增加stubbed fallback降级机制
我们上一讲讲到说,限流,计算了一下线程池的最大的大小,和这个等待队列,去限制了每秒钟最多能发送多少次请求到商品服务
避免大量的请求都发送到商品服务商去
限流过后,就会导致什么呢,比如redis集群崩溃了,雪崩,大量的请求涌入到商品服务调用的command中,是线程池不够
reject,被reject掉的请求就会去执行fallback降级逻辑
理清楚一些前提,首先一个请求都发送到这里来了,那么nginx本地缓存肯定就没了,redis已经崩溃了,ehcache中找不到这条数据对应的缓存
只能从源头的商品服务里面去查询,但是被限流了,这个请求只能走降级方案
都是用之前讲解的一些技术,stubbed fallback降级机制,残缺的降级
一般这种情况下,就是说,用请求参数中少量的数据,加上纯内存中缓存的少量的数据来提供残缺的数据服务
就给大家举个例子,我们之前讲解的stubbed fallback,是从内存中加载了部分品牌数据,加载了部分城市地理位置的数据啦。。。
方案,可以做,冷热分离
冷数据,也就是说你可以这么认为,将一些过时的数据,比如一个商品信息一周前的版本,放入大数据的在线存储中,比如比较合适做冷数据存放的是hbase
hadoop,离线批处理,hdfs分布式存储,yarn分布式资源调度(跟hbase没关系),mapreduce分布式计算
hbase,基于hdfs分布式存储基础之上,封装了一个系统,叫做hbase,分布式在线存储,分布式NoSQL数据库,里面可以放大量的冷数据
hbase,可以做商品服务热数据是放mysql,可以将一周前,一个月前的数据快照,做一份冷备放到hbase来备用
你本来正常情况下是直接去访问商品服务,去拉取热数据
发送请求去访问hbase,去加载冷数据,hbase本身是分布式的,所以也是可以承载高并发的访问的(分布式的特性比mysql),即使这个时候大量并发到了hbase,如果你集群运维够好的话,也开始以撑住的,加载到一条冷数据的话,那么此时就是过期的数据,商品一周前或者一个月前的一个快照版本
但是至少有数据,还可以显示一下
多级降级机制,先走hbase冷备,然后再走stubbed fallback
缓存雪崩的回顾
1、事前,redis高可用性,redis cluster,sentinal,复制,主从,从->主,双机房部署
2、事中,ehcache可以抗一抗,redis挂掉之后的资源隔离、超时控制、熔断,商品服务的访问限流、多级降级,缓存服务在雪崩场景下存活下来,基于ehcache和存活的商品服务提供数据
3、事后,快速恢复Redis,备份+恢复,快速的缓存预热的方案
public class ProductInfoCommand extends HystrixCommand<ProductInfo> {
private Long productId;
public ProductInfoCommand(Long productId) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ProductInfoService"))
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter()
.withCoreSize(10) //线程数
.withMaximumSize(30) //最大线程数
.withAllowMaximumSizeToDivergeFromCoreSize(true) //动态变化
.withKeepAliveTimeMinutes(1) //空闲线程存活时间(1分钟)
.withMaxQueueSize(50) //等待队列
.withQueueSizeRejectionThreshold(100)));
this.productId = productId;
}
@Override
protected ProductInfo run() throws Exception {
// 发送http或rpc接口调用,去调用商品服务的接口
String productInfoJSON = "{\"id\": "+productId+", \"name\": \"iphone7手机\", \"price\": 5599, \"pictureList\":\"a.jpg,b.jpg\", \"specification\": \"iphone7的规格\", \"service\": \"iphone7的售后服务\", \"color\": \"红色,白色,黑色\", \"size\": \"5.5\", \"shopId\": 1, \"modifyTime\": \"2019-07-29 16:31:00\"}";
return JSONObject.parseObject(productInfoJSON, ProductInfo.class);
}
@Override
protected ProductInfo getFallback() {
return new HbaseColdDataCommand(productId).execute();
}
/**
* 一级降级,从Hbase获取冷备数据
*/
private class HbaseColdDataCommand extends HystrixCommand<ProductInfo> {
private Long productId;
public HbaseColdDataCommand(Long productId) {
super(HystrixCommandGroupKey.Factory.asKey("HBaseGroup"));
this.productId = productId;
}
@Override
protected ProductInfo run() throws Exception {
//查询hbase
String productInfoJSON = "{\"id\": "+productId+", \"name\": \"hbase iphone7手机\", \"price\": 5599, \"pictureList\":\"a.jpg,b.jpg\", \"specification\": \"iphone7的规格\", \"service\": \"iphone7的售后服务\", \"color\": \"红色,白色,黑色\", \"size\": \"5.5\", \"shopId\": 1, \"modifyTime\": \"2019-07-29 16:31:00\"}";
return JSONObject.parseObject(productInfoJSON, ProductInfo.class);
}
/**
* 二级降级
* @return
*/
@Override
protected ProductInfo getFallback() {
ProductInfo productInfo = new ProductInfo();
productInfo.setId(productId);
// 从内存中找一些残缺的数据拼装进去
return productInfo;
}
}
}
九十六、高并发场景下的缓存穿透导致MySQL压力倍增问题以及其解决方案
九十七、在缓存服务中开发缓存穿透的保护性机制
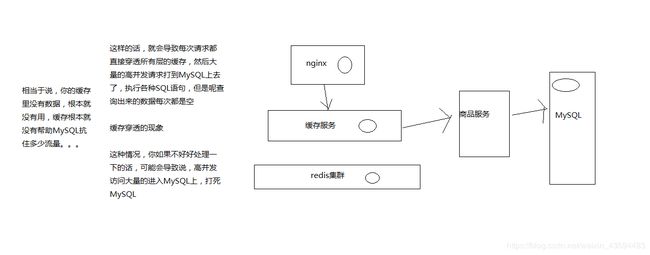
我们的缓存穿透的解决方案,其实非常的简单,就是说每次如果从源服务(商品服务)查询到的数据是空,就说明这个数据根本就不存在
那么如果这个数据不存在的话,我们不要不往redis和ehcache等缓存中写入数据,我们呢,给写入一个空的数据,比如说空的productInfo的json串
给nginx也是,返回一个空的productInfo的json串咯
因为我们有一个异步监听数据变更的机制在里面,也就是说,如果数据变更的话,某个数据本来是没有的,可能会导致缓存穿透,所以我们给了个空数据
但是现在这个数据有了,我们接收到这个变更的消息过后,就可以将数据再次从源服务中查询出来
然后设置到各级缓存中去了
九十八、高并发场景下的nginx缓存失效导致redis压力倍增问题以及解决方案
缓存失效
就是大家还记得,我们在nginx中设置本地的缓存的时候,会给一个过期的时间,比如说10分钟
10分钟以后自动过期,过期了以后,就会重新从redis中去获取数据
这个10分钟到期自动过期的事情,就叫做缓存的失效
如果缓存失效以后,那么实际上此时,就会有大量的请求回到redis中去查询
缓存失效的问题。。。。
如果说同一时间来了1000个请求,都将缓存cache在了nginx自己的本地,缓存失效的时间都设置了10分钟
那么是不是可能导致10分钟过后,这些数据,就自动全部在同一时间失效了
如果同一时间全部失效,会不会导致说同一时间大量的请求过来,在nginx里找不到缓存数据,全部高并发走到redis上去了
加重大量的网络请求,网络负载也会加重
解决方案是什么呢?
九十九、在nginx lua脚本中开发缓存失效的保护性机制
math.randomseed(tostring(os.time()):reverse():sub(1, 7))
local expireTime = math.random(600, 1200)
一零零、支撑高并发与高可用的大型电商详情页系统的缓存架构课程总结
1、亿级流量电商网站的商品详情页系统架构
面临难题:对于每天上亿流量,拥有上亿页面的大型电商网站来说,能够支撑高并发访问,同时能够秒级让最新模板生效的商品详情页系统的架构是如何设计的?
解决方案:异步多级缓存架构+nginx本地化缓存+动态模板渲染的架构
2、redis企业级集群架构
面临难题:如何让redis集群支撑几十万QPS高并发+99.99%高可用+TB级海量数据+企业级数据备份与恢复?
解决方案:redis的企业级备份恢复方案+复制架构+读写分离+哨兵架构+redis cluster集群部署
3、多级缓存架构设计
面临难题:如何将缓存架构设计的能够支撑高性能以及高并发到极致?同时还要给缓存架构最后的一个安全保护层?
解决方案:nginx抗热点数据+redis抗大规模离线请求+ehcache抗redis崩溃的三级缓存架构
4、数据库+缓存双写一致性解决方案
面临难题:高并发场景下,如何解决数据库与缓存双写的时候数据不一致的情况?
解决方案:异步队列串行化的数据库+缓存双写一致性解决方案
5、缓存维度化拆分解决方案
面临难题:如何解决大value缓存的全量更新效率低下问题?
解决方案:商品缓存数据的维度化拆分解决方案
6、缓存命中率提升解决方案
面临难题:如何将缓存命中率提升到极致?
解决方案:双层nginx部署架构+lua脚本实现一致性hash流量分发策略
7、缓存并发重建冲突解决方案
面临难题:如何解决高并发场景下,缓存重建时的分布式并发重建的冲突问题?
解决方案:基于zookeeper分布式锁的缓存并发重建冲突解决方案
8、缓存预热解决方案
面临难题:如何解决高并发场景下,缓存冷启动导致MySQL负载过高,甚至瞬间被打死的问题?
解决方案:基于storm实时统计热数据的分布式快速缓存预热解决方案
9、热点缓存自动降级方案
面临难题:如何解决热点缓存导致单机器负载瞬间超高?
解决方案:基于storm的实时热点发现+毫秒级的实时热点缓存负载均衡降级
10、高可用分布式系统架构设计
面临难题:如何解决分布式系统中的服务高可用问题?避免多层服务依赖因为少量故障导致系统崩溃?
解决方案:基于hystrix的高可用缓存服务,资源隔离+限流+降级+熔断+超时控制
11、复杂的高可用分布式系统架构设计
面临难题:如何针对复杂的分布式系统将其中的服务设计为高可用架构?
解决方案:基于hystrix的容错+多级降级+手动降级+生产环境参数优化经验+可视化运维与监控
12、缓存雪崩解决方案
面临难题:如何解决恐怖的缓存雪崩问题?避免给公司带来巨大的经济损失?
解决方案:全网独家的事前+事中+事后三层次完美缓存雪崩解决方案
13、缓存穿透解决方案
面临难题:如何解决高并发场景下的缓存穿透问题?避免给MySQL带来过大的压力?
解决方案:缓存穿透解决方案
14、缓存失效解决方案
面临难题:如何解决高并发场景下的缓存失效问题?避免给redis集群带来过大的压力?
解决方案:基于随机过期时间的缓存失效解决方案
硬件规划
每日上亿流量,高峰QPS过1万
nginx部署,负载很重,16核32G,建议给3~5台以上,就非常充裕了,每台抗个几千QPS
缓存服务部署,4核8G,按照每台QPS支撑500,部署个10~20台
redis部署,每台给8核16G,根据数据量以及并发读写能力来看,部署5~10个master,每个master挂一个slave,主要是为了支撑更多数据量,1万并发读写肯定没问题了